这篇文章记述了关于CMU15-445数据库的知识点。
2021-01-18 编译
今天配置了一天的开发环境。centos 7 的 gcc 版本是 4.8,不支持 C++ 17 的编译。于是又下载最新的 gcc 源码进行编译:编译的速度巨慢不说,它还老报错,缺这个少那个的。真让人头大,最后直接编译不下去了,留下一个烂摊子给我,郁闷死了。好在最后在网上找到一篇博客挺靠谱的。
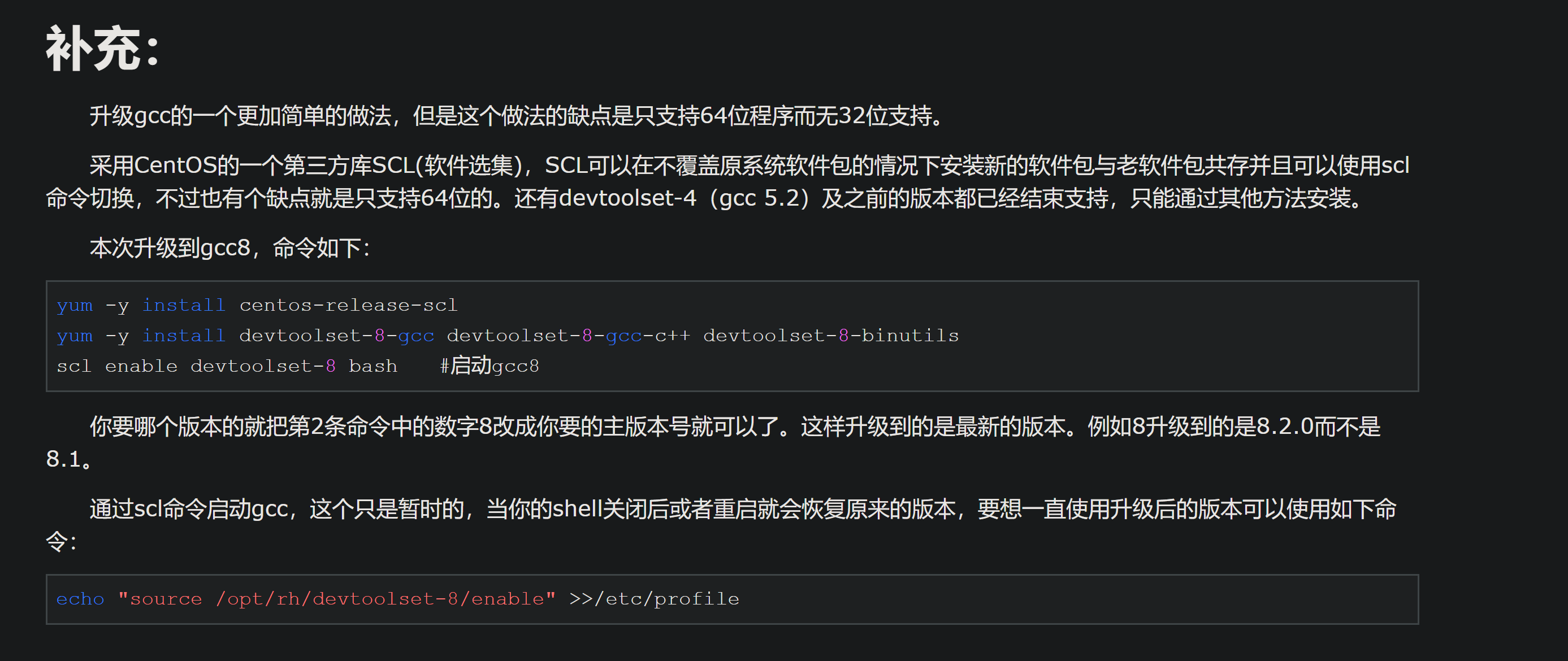
升级GCC版本
https://www.cnblogs.com/ToBeExpert/p/10297697.html
2021-01-19 调试
试了其他人写好的程序发现编译不通过。最后决定就用官方的版本进行了编译,可是官方的版本采用了 Google Test 进行测试,咱野路子用惯了,没用过这么高级的工具,再加上 Github 的渣渣网速,就一直卡在 clone Google Test 的进度上,最后找了谷歌应用商店里的一个插件 Github加速 ,更换了下载地址,顿时下载速度起飞。
可是我一直习惯用 VSCode 连接远端服务器进行调试。由于我之前刚重装过系统,进 VSCode 之后死活连不上服务器,总是报错 “过程试图写入的管道不存在”。重新生成公钥私钥也解决不了。最后发现问题所在:我的系统环境变量里的 ssh 被设置成了 win10 自带的 openSSH ,替换掉我自己的 Git 里的 ssh 路径之后还是不行,隐隐看到 VSCode 还是用的 openSSH 进行连接,于是重启电脑之后让环境变量生效,轻松连上服务器。
接着进行测试,发现加上这 Google Test 之后我连 main 函数入口都找不到了,这怎么单步调试呢?加断点也进不去啊。总是显示有几个 Test 被 DISABLED 了。
解决办法:
TEST(BufferPoolManagerTest, DISABLED_BinaryDataTest)
改成:
TEST(BufferPoolManagerTest, BinaryDataTest)
就能进入断点里面了。
真高级!
2021-01-20 B+树
今天看了 HashTable 和 B+ 树的视频。
这算得上是数据库中最重要的两个数据结构了吧。
先来理清一下“索引 index”的概念:
索引是关系数据库中对某一列或多个列的值进行预排序的数据结构。通过使用索引,可以让数据库系统不必扫描整个表,而是直接定位到符合条件的记录,这样就大大加快了查询速度。
例如这样一个查询:select * from table1 where id=10000。如果没有索引,必须遍历整个表,直到ID等于10000的这一行被找到为止;有了索引之后(必须是在ID这一列上建立的索引),即可在索引中查找。由于索引是经过某种算法优化过的,因而查找次数要少的多。可见,索引是用来定位的。
索引的效率取决于索引列的值是否散列,即该列的值如果越互不相同,那么索引效率越高。反过来,如果记录的列存在大量相同的值,例如
gender列,大约一半的记录值是M,另一半是F,因此,对该列创建索引就没有意义。可以对一张表创建多个索引。索引的优点是提高了查询效率,缺点是在插入、更新和删除记录时,需要同时修改索引,因此,索引越多,插入、更新和删除记录的速度就越慢。
对于主键,关系数据库会自动对其创建主键索引。使用主键索引的效率是最高的,因为主键会保证绝对唯一。
2021-01-23 LRU
今天主要是完成了 LRU 替换算法的开发。出现了两个小失误:
1 | bool LRUReplacer::Victim(frame_id_t *frame_id) { |
2021-01-26 buffer_pool
今天是回到家的第一天,主要工作计划如下:
- CMU 的 B+ 树的代码编写
- 2+2方法的彩色纹理实现
- 更新一下自己的简历和个人主页
reinterpret_cast运算符是用来处理无关类型之间的转换;它会产生一个新的值,这个值会有与原始参数(expressoin)有完全相同的比特位。
什么是无关类型?我没有弄清楚,没有找到好的文档来说明类型之间到底都有些什么关系(除了类的继承以外)。后半句倒是看出了reinterpret_cast的字面意思:重新解释(类型的比特位)。我们真的可以随意将一个类型值的比特位交给另一个类型作为它的值吗?其实不然。
auto root = reinterpret_cast<BPlusTreeLeafPage<KeyType, ValueType, KeyComparator> *>(page->GetData());
std::atomic next_page_id_;
C++中对共享数据的存取在并发条件下可能会引起data race的undifined行为,需要限制并发程序以某种特定的顺序执行,有两种方式:使用mutex保护共享数据,原子操作:针对原子类型操作要不一步完成,要么不做,不可能出现操作一半被切换CPU,这样防止由于多线程指令交叉执行带来的可能错误。非原子操作下,某个线程可能看见的是一个其它线程操作未完成的数据。
2021-01-28 static
1 | // 要插入的值比当前最小的还小,赶紧给我腾位置 array 指的是数组首地址, + 1 代表移动一个元素的空间大小(此处为sizeof(MappingType)的大小) |
改动了 b_plus_tree_leaf_page.h中 bool Lookup(const KeyType &key, ValueType *value, const KeyComparator &comparator) const;为 ``bool Lookup(const KeyType &key, ValueType &value, const KeyComparator &comparator) const`
链接时出现下面报错:原因是 static 变量要在类外面进行初始化,不然就会出现链接错误。
1 | [100%] Linking CXX executable b_plus_tree_insert_test |
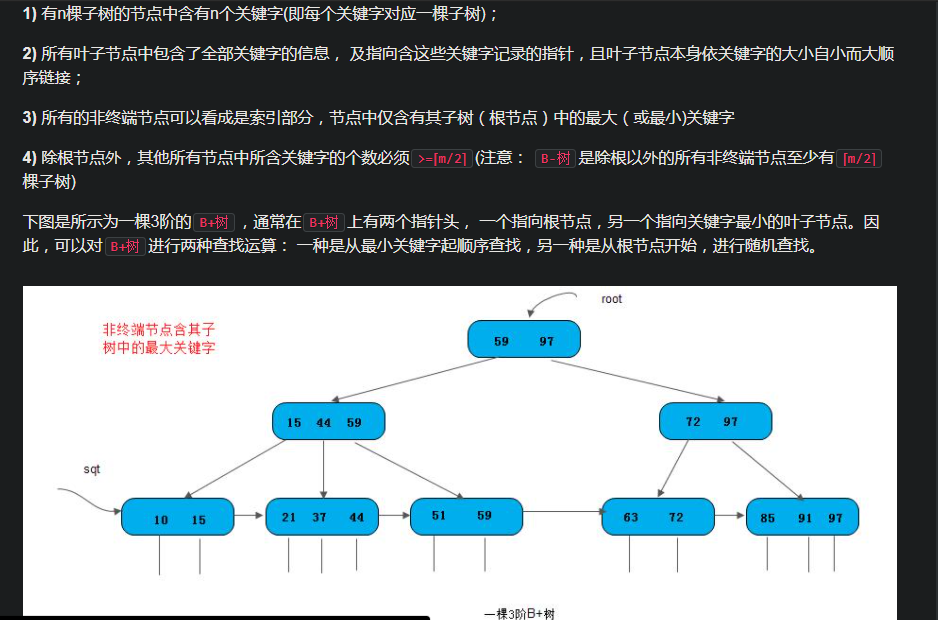
2021-01-29 B+ index
1 | // 删除节点 |
2021-01-30 互斥锁
昨天好不容易跑起来了,就碰上了一个非常棘手的问题,lockRoot()会在这里死锁住,不知道是谁申请了互斥锁忘了释放了。这该如何排查呢?
1 | INDEX_TEMPLATE_ARGUMENTS |
哦,缘赖氏佐田,进入每个函数时都会设置std::lock_guard<std::mutex> lock(mutex_);智能指针控制的互斥锁,他会把mutex给锁住。在进入InsertIntoLeaf函数的时候就会发生死锁。
1 | INDEX_TEMPLATE_ARGUMENTS |
正确做法应该是:
1 | INDEX_TEMPLATE_ARGUMENTS |
接着又碰到了一个问题:
1 | ValueType B_PLUS_TREE_INTERNAL_PAGE_TYPE::Lookup(const KeyType &key, const KeyComparator &comparator) const { |
断言失败,因为我插入第一个元素的时候获取叶子节点页面时里面就只有一个元素啊,这该如何是好?
这段代码中,static_cast<int32_t>(key >> 32)透露出当 一个 page 最多能储存 2^32个key;超过就换新的 page_id,此处模板为 8 个 Bytes,即为 int64_t。
1 | std::vector<int64_t> keys = {1, 2, 3, 4, 5}; |
2021-01-31
今天是一月的最后一天,佐田的问题还是没有解决,我决定换个测试案例进行测试。
1 | // header_page相当于一个目录,保存了所有的index及其对应的root_page_id |
unordered_map 的排序不能写成sort(unordered_map<int, int>& a, unordered_map<int, int>& b){return a.second < b.second} 而是应该写成sort(pair<int, int>& a, pair<int, int>& b){return a.second < b.second}
但是在0220的力扣刷题中我写了
sort(map_.begin(), map_.end(), [&](pair<int, int>& A, pair<int, int>& B) {return A.second > B.second;});代码却报错:
In file include from ./precompiled/headder...我怀疑是没有包含头文件造成的(0314:这是不对的)
2
3
4
5
6
for (auto& i : m)
tmp.push_back(i);
std::sort(tmp.begin(), tmp.end(),
[=](std::pair<int, int>& a, std::pair<int, int>& b) { return a.second < b.second; });
2021-02-01 调试
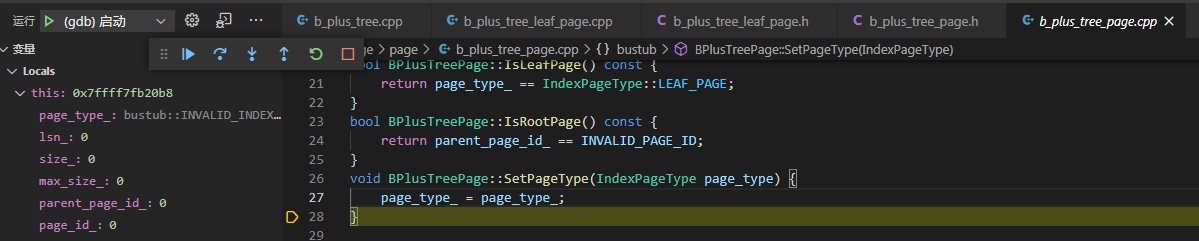
问题查出来了,这个设置叶子页面类型的函数 SetPageType 不干事:接收到本来应该是 LEAF_PAGE 的参数却不不给人家 page_type_ 赋值,导致人家还是为 INVALID_PAGE_TYPE
w 瞎了眼了!
page_type_ = page_type_; 应该改为 page_type_ = page_type;
2021-02-04 B+树
1 | /* Append an entry at the beginning. |
2021-02-06 聚簇索引
https://blog.csdn.net/justloveyou_/article/details/78308460
https://blog.csdn.net/Zzhou1990/article/details/108637517
- 聚集索引。表数据按照索引的顺序来存储的,也就是说索引项的顺序与表中记录的物理顺序一致。对于聚集索引,叶子结点即存储了真实的数据行,不再有另外单独的数据页。 在一张表上最多只能创建一个聚集索引,因为真实数据的物理顺序只能有一种。
- 非聚集索引。表数据存储顺序与索引顺序无关。对于非聚集索引,叶结点包含索引字段值及指向数据页数据行的逻辑指针,其行数量与数据表行数据量一致。
- 在《数据库原理》一书中是这么解释聚簇索引和非聚簇索引的区别的:
聚簇索引的叶子节点就是数据节点,而非聚簇索引的叶子节点仍然是索引节点,只不过有指向对应数据块的指针。
1 | 【聚簇索引】 |
SNAT-DNAT
1 | 从定义上讲,SNAT是原地址转换,DNAT是目标地址转换。区分这两个功能可以简单的由服务的发起者是谁来区分,内部地址要访问公网上的服务时,内部地址会主动发起连接,将内部地址转换成公有ip。网关这个地址转换称为SNAT. 当内部需要对外提供服务时,外部发起主动连接,路由器或着防火墙的网关接收到这个连接,然后把连接转换到内部,此过程是由带公有ip的网关代替内部服务来接收外部的连接,然后在内部做地址转换,此转换称为DNAT.主要用于内部服务对外发布。 |
递归
TCP可靠传输
剑指offer
并发控制
存储变长数据
网络项目
拍摄结构光照片
小论文
2021-02-11 page 的布局
每一个 page 里包含了一个元信息头 Header,这个头里面包含了页面的内容:页面大小、校验和、访问时间
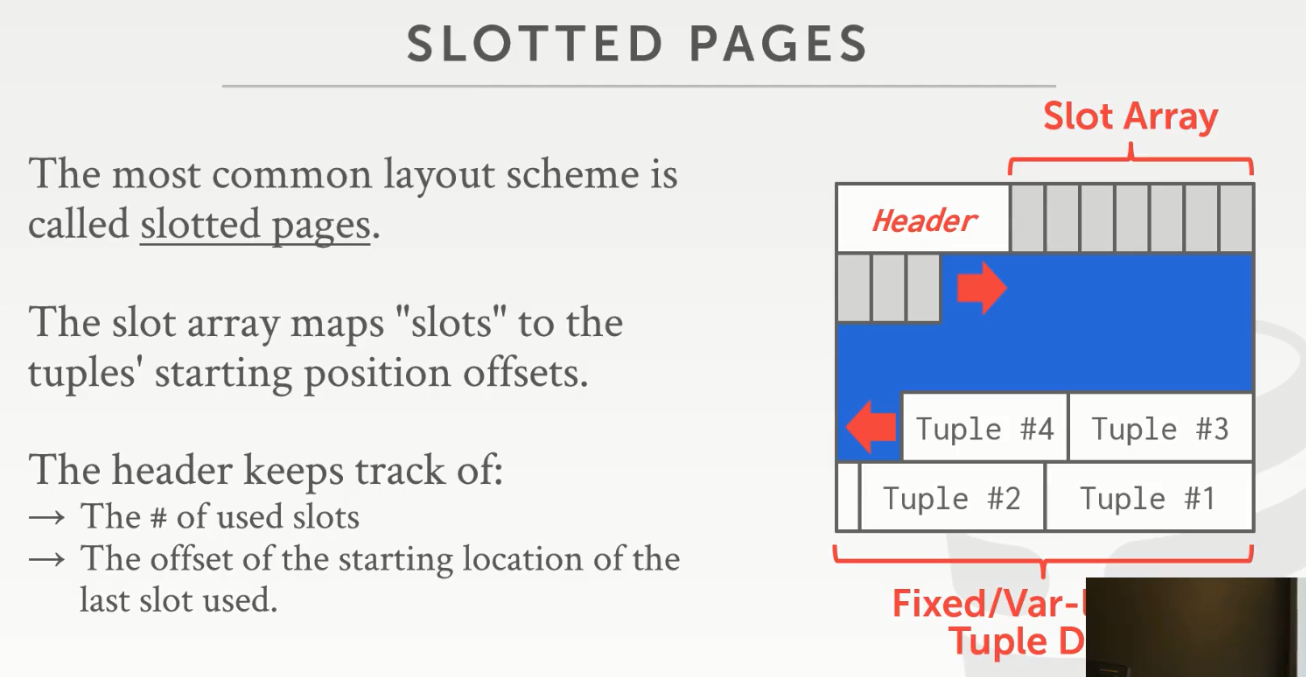
灰色的是 slot array,每一个槽里存储着元组的起始偏移地址。
元组的长度是可变的或者是固定的
为什么 slot array 从头到尾增长、元组从尾到头增长?
这样迟早会在中间留下一块无法存储任何新信息的地方,这样我们就说我们的页面已满。如果是对半劈分进行从头到尾的增长,有可能插槽不够用了,有可能元组空间不够用了。这样的增长方式对于空间的利用率可以说是比较高的。
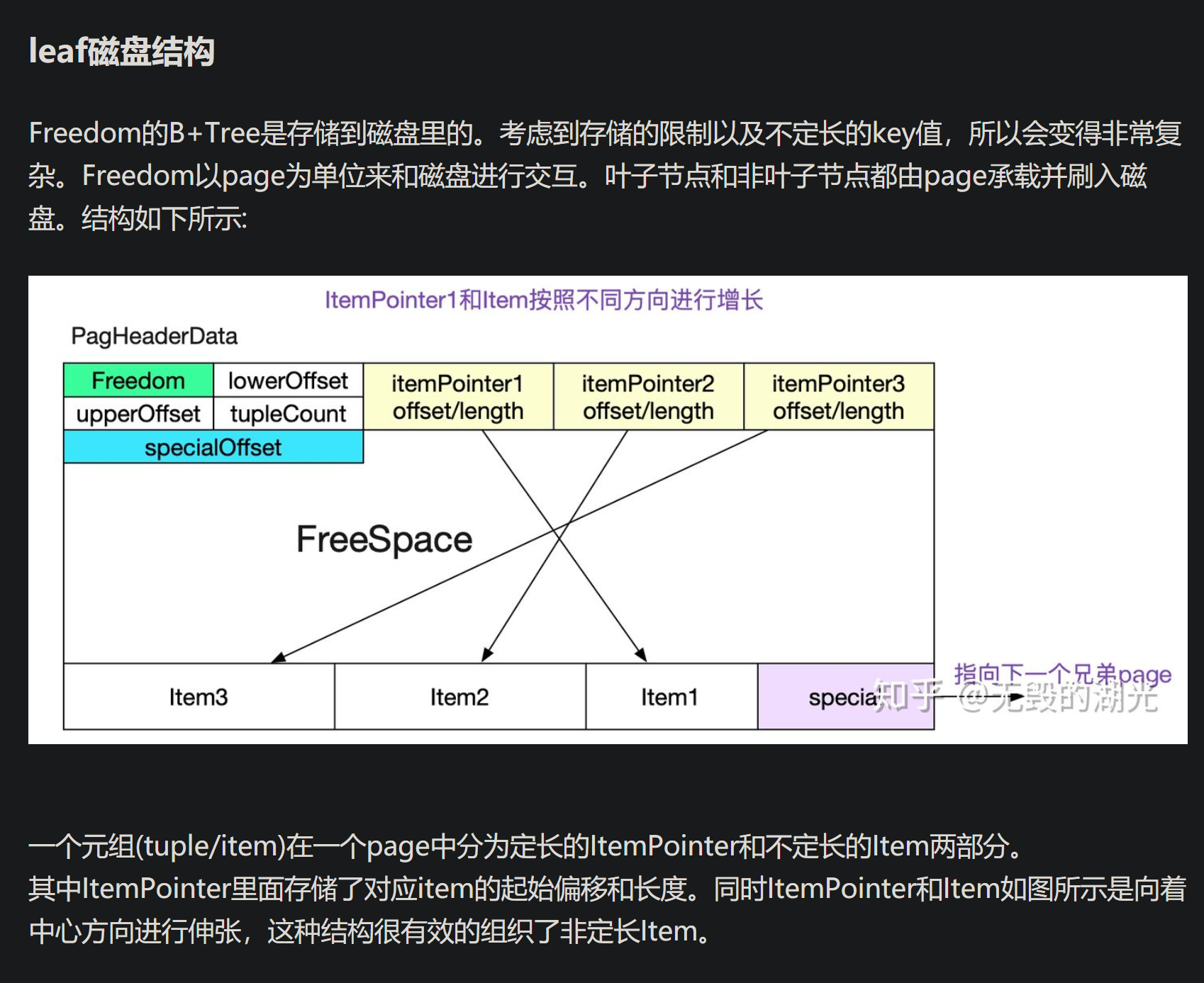
这样的页面布局好处是什么呢?
想象一下你要移动一个元组从这个页面到另外一个页面:只需要记录下页面ID和插槽号就可以了
可变长度的怎么弄?
我觉得只有一个起始偏移地址,对于固定长度的元组读取倒还好说,但是对于可变长度的,它的尾部无法确定啊。
通过仔细看代码,发现他的元组不仅会记录起始偏移地址,还会记录元组大小
2021-02-14 条件变量 互斥锁
可变参数
1 | // helper function to launch multiple threads |
看到下面这段代码,产生质疑:如果析构时发现互斥锁还被别人持有,岂不是会一直堵塞在这块?
1 | public: |
lock(),调用线程将锁住该互斥量。线程调用该函数会发生下面 3 种情况:(1). 如果该互斥量当前没有被锁住,则调用线程将该互斥量锁住,直到调用 unlock之前,该线程一直拥有该锁。(2). 如果当前互斥量被其他线程锁住,则当前的调用线程被阻塞住。(3). 如果当前互斥量被当前调用线程锁住,则会产生死锁(deadlock)。
try_lock(),尝试锁住互斥量,如果互斥量被其他线程占有,则当前线程也不会被阻塞。线程调用该函数也会出现下面 3 种情况,(1). 如果当前互斥量没有被其他线程占有,则该线程锁住互斥量,直到该线程调用 unlock 释放互斥量。(2). 如果当前互斥量被其他线程锁住,则当前调用线程返回 false,而并不会被阻塞掉。(3). 如果当前互斥量被当前调用线程锁住,则会产生死锁(deadlock)。
std::recursive_mutex 介绍
std::recursive_mutex 与 std::mutex 一样,也是一种可以被上锁的对象,但是和 std::mutex 不同的是,std::recursive_mutex 允许同一个线程对互斥量多次上锁(即递归上锁),来获得对互斥量对象的多层所有权,std::recursive_mutex 释放互斥量时需要调用与该锁层次深度相同次数的 unlock(),可理解为 lock() 次数和 unlock() 次数相同,除此之外,std::recursive_mutex 的特性和 std::mutex 大致相同。
相信 Linux 程序员都用过 Pthread, 但有了 C++11 的 std::thread 以后,你可以在语言层面编写多线程程序了,直接的好处就是多线程程序的可移植性得到了很大的提高,所以作为一名 C++ 程序员,熟悉 C++11 的多线程编程方式还是很有益处的。
C++ 11 标准引入了四个头文件来支持多线程编程,分别是
:该头文主要声明了两个类, std::atomic 和 std::atomic_flag,另外还声明了一套 C 风格的原子类型和与 C 兼容的原子操作的函数。 :该头文件主要声明了 std::thread 类,另外 std::this_thread 命名空间也在该头文件中。 :该头文件主要声明了与互斥量(mutex)相关的类,包括 std::mutex 系列类,std::lock_guard, std::unique_lock, 以及其他的类型和函数。 :该头文件主要声明了与条件变量相关的类,包括 std::condition_variable 和 std::condition_variable_any。 :该头文件主要声明了 std::promise, std::package_task 两个 Provider 类,以及 std::future 和 std::shared_future 两个 Future 类,另外还有一些与之相关的类型和函数,std::async() 函数就声明在此头文件中。
https://www.cnblogs.com/haippy/p/3236136.html
std::thread 构造
| default (1) | thread() noexcept; |
|---|---|
| initialization (2) | template <class Fn, class... Args> explicit thread (Fn&& fn, Args&&... args); |
| copy [deleted] (3) | thread (const thread&) = delete; |
| move (4) | thread (thread&& x) noexcept; |
- (1). 默认构造函数,创建一个空的 thread 执行对象。
- (2). 初始化构造函数,创建一个 thread对象,该 thread对象可被 joinable,新产生的线程会调用 fn 函数,该函数的参数由 args 给出。
- (3). 拷贝构造函数(被禁用),意味着 thread 不可被拷贝构造。
- (4). move 构造函数,move 构造函数,调用成功之后 x 不代表任何 thread 执行对象(注意这句话)。
- 注意:可被 joinable 的 thread 对象必须在他们销毁之前被主线程 join 或者将其设置为 detached.
1 |
|
这里很明显的指出了移动构造函数的效果,t3 在当成参数传进 t4 之后,t3 就失去了语义。
2021-02-15 condition_variable 类介绍
std::condition_variable 是 C++11 多线程编程中的条件变量。
当
std::condition_variable对象的某个wait类函数被调用的时候,它使用std::unique_lock(通过std::mutex)来锁住当前的线程,当前的线程会一直被阻塞(进入睡眠等待状态),直到有其他的线程在同一个std::condition_variable对象上调用notify类函数来唤醒它。
unique_lock 与 lock_guard 区别
大部分情况下,两者的功能是一样的,不过unique_lock 比lock_guard 更灵活.
unique_lock提供了lock, unlock, try_lock等接口.
lock_guard没有多余的接口,构造函数时拿到锁,析构函数时释放锁
lock_guard 比unique_lock 要省时.
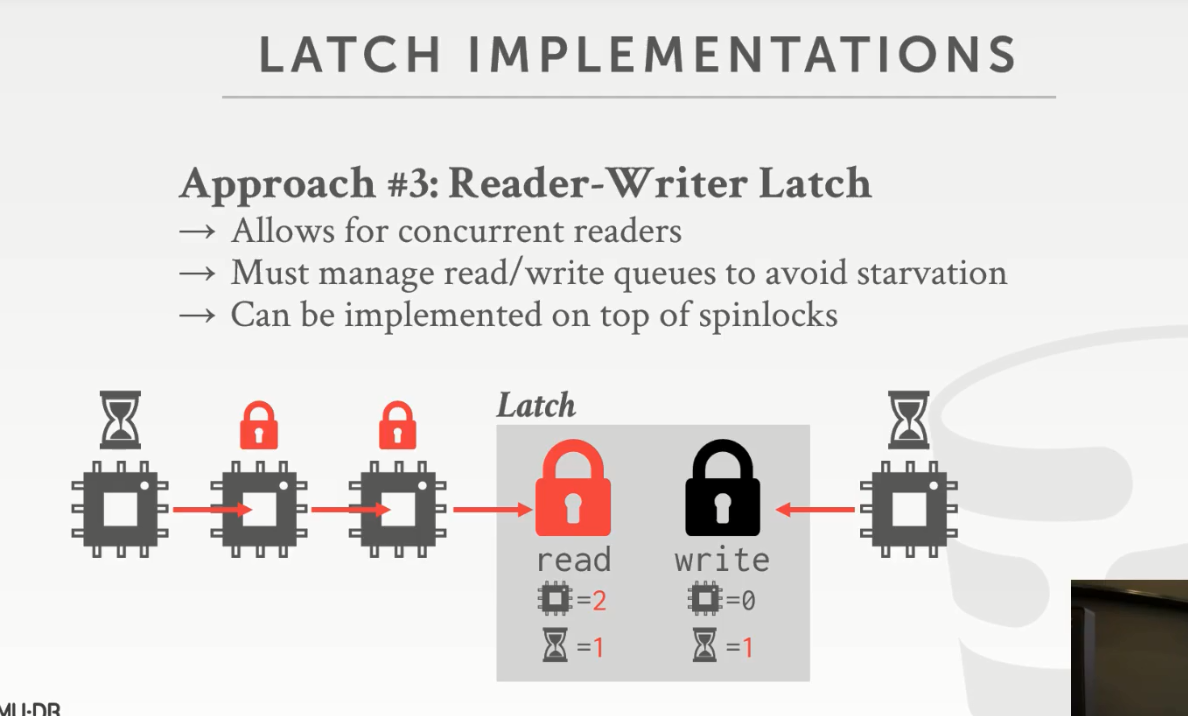
reader-writer latch
左边有两个读线程,那么 read latch 会计数为2
这时来了一个写线程,别人还正在读呢,你就不能直接去写,所以会等待计数为1;
这时又来了一个读线程,如果让计数变为3,那么写线程会饥饿,取决于具体的策略,此处是将读线程等待,让写线程赶紧执行。
double free or corruption
2021-02-20 并发
关于B+ 树索引的并发,有如下需要注意的地方:
一个安全的节点应该具备两种特质:一是不全满(可以给插入留出足够的空间);二是超过半满(不会因为删除而split)
设想这样一种场景:
线程1想要删除44,删完之后节点就只剩一个值了,需要重新平衡
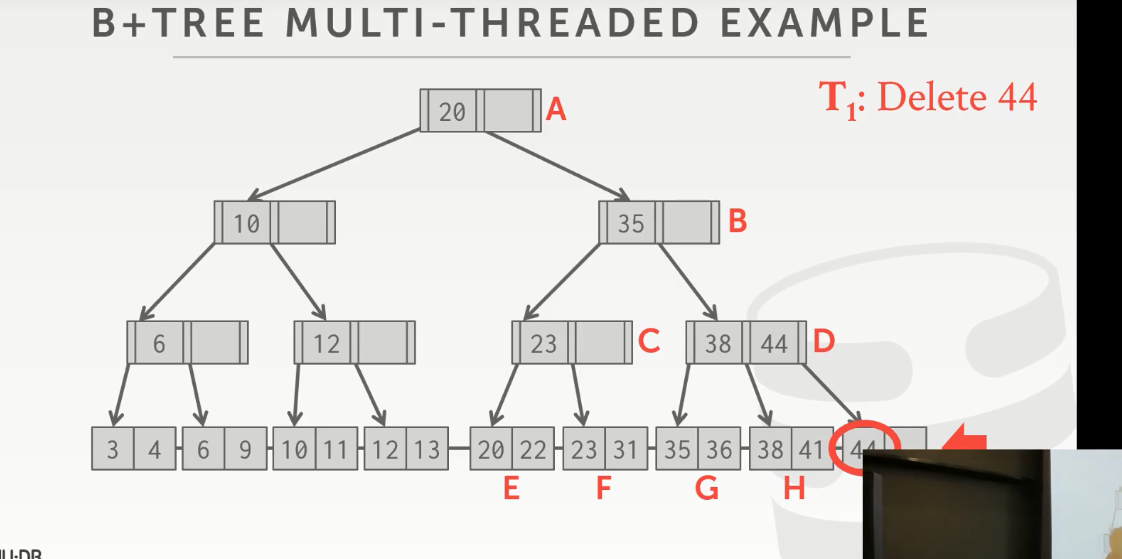
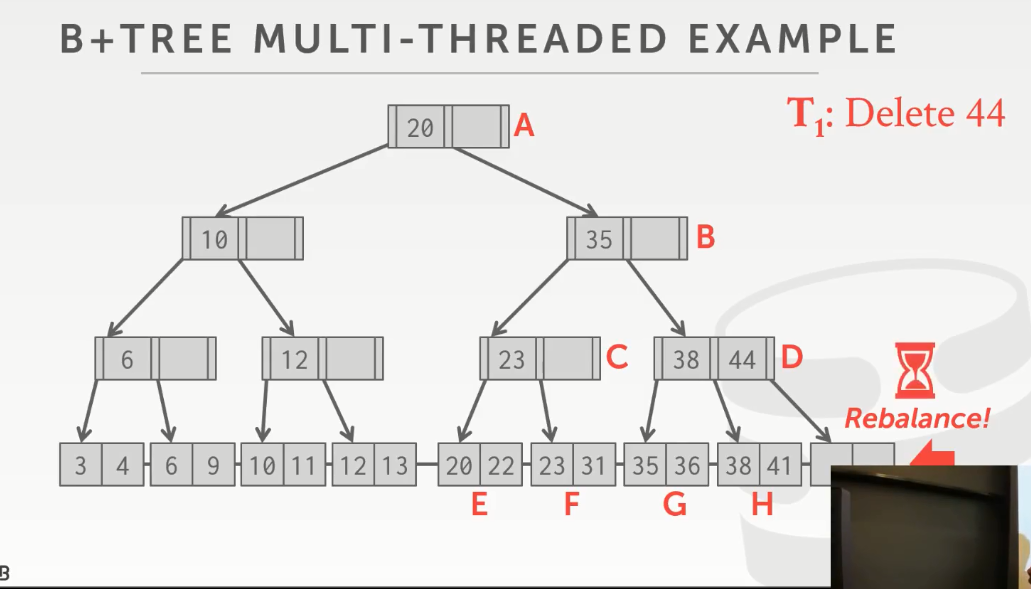
哎,恰好就在这重新平衡时,操作系统将线程1替换出去了
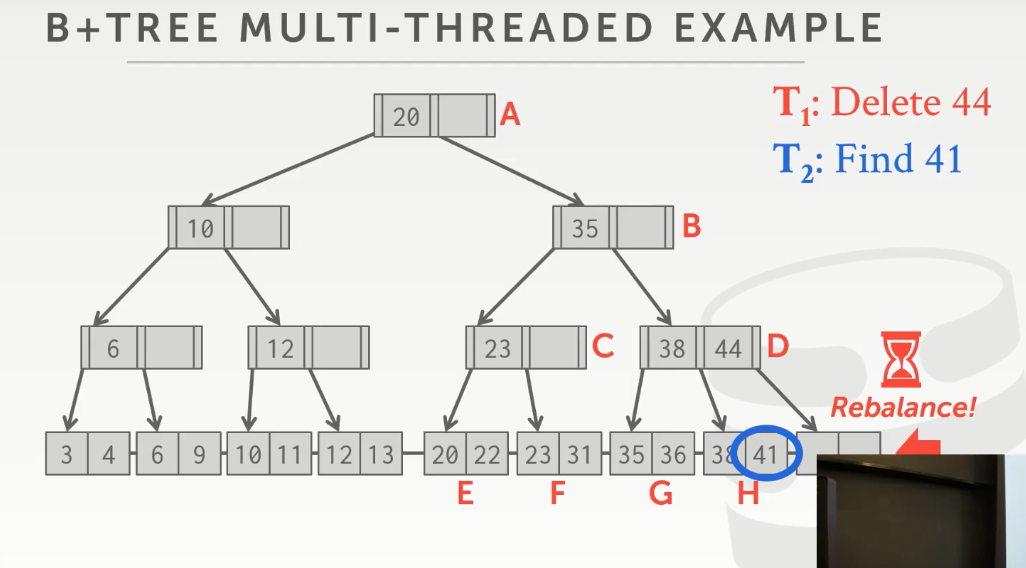
换进来的线程2想要查找41节点
线程2好不容易找到D索引处,恰好此时操作系统又把线程1替换进来了,线程1就把41 split 到旁边的节点上了。线程2再执行的时候就会找到一个不存在的地址。
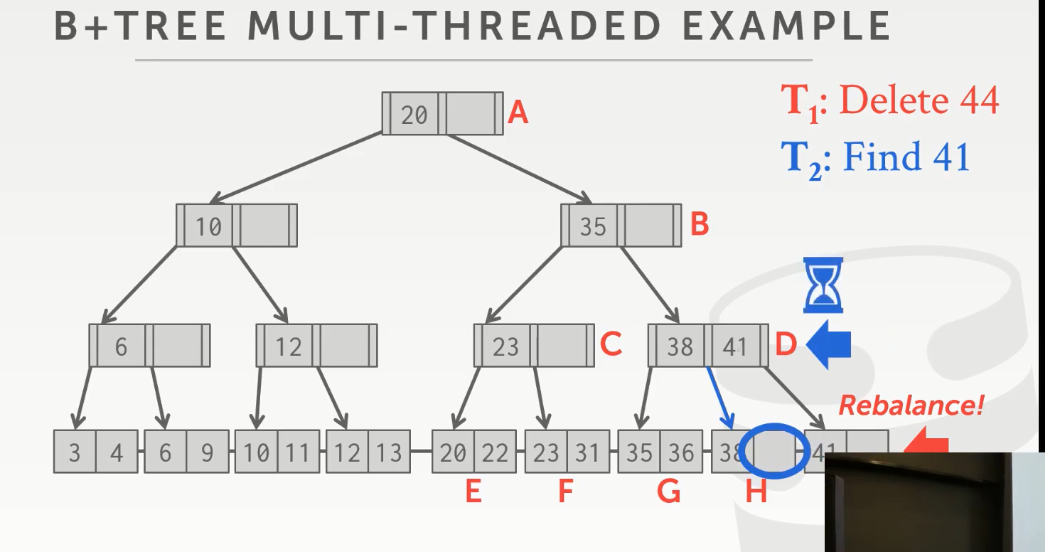
想要解决这个问题,需要依赖 latch crabbing 技术,crab 是螃蟹的意思。此处是说先给父亲节点上锁,再给儿子节点上锁,如果确认父亲节点是安全的话就释放父亲节点。类似螃蟹走路时一条腿跟着前面一条腿的移动而移动。

以下这张图需要好好理解一下:对于查找而言,从根节点开始往下查找,给它的孩子节点上R锁,这样当出现前文所述的情况时,如果新来的线程想要修改孩子节点的值,一看上面还有人正在读它呢,自己的修改是不是要往后推迟一下,等人家读完再进行修改。
对于插入和删除而言:
如果不全满或者超过一半那就是安全的,可以放心的进行插入和删除,不用担心自己修改完之后产生 split 和 merge 的情况,导致自己被替换出去后别人读到空数据。假设不安全,那么这个 W锁会被该线程所持有,别人在读的时候就会慎重。一旦是安全的,就释放祖先节点上的锁。

这块 Andy 的视频做了四个很好的动图解析,时间在第 33 分钟左右。
有一个学生提了个问题很不错:释放W锁的时候的顺序是什么样的?是从上到下的。因为别人还急等着用最上边的索引节点呢,你先释放底下的话,上面有锁别人还是访问不了啊。
root 瓶颈与乐观锁
由于每个线程都会给 root 节点加上锁,这会造成整体并发的瓶颈。解决办法就是采用乐观锁:先假设你们不会有那么大的修改量连我 root 节点都给修改了,所以我把W锁换成R锁,一路锁下来,等到叶子节点产生分裂或合并时再重做之前的工作并使用W锁。
read latch 阻止别人写(可以共享); write latch 阻止别人修改它
2021-02-28
mysql 创建表
1 | CREATE TABLE IF NOT EXISTS `runoob_tbl`( |
stack中如果没有元素的话,访问top,如果栈为空,返回值未定义
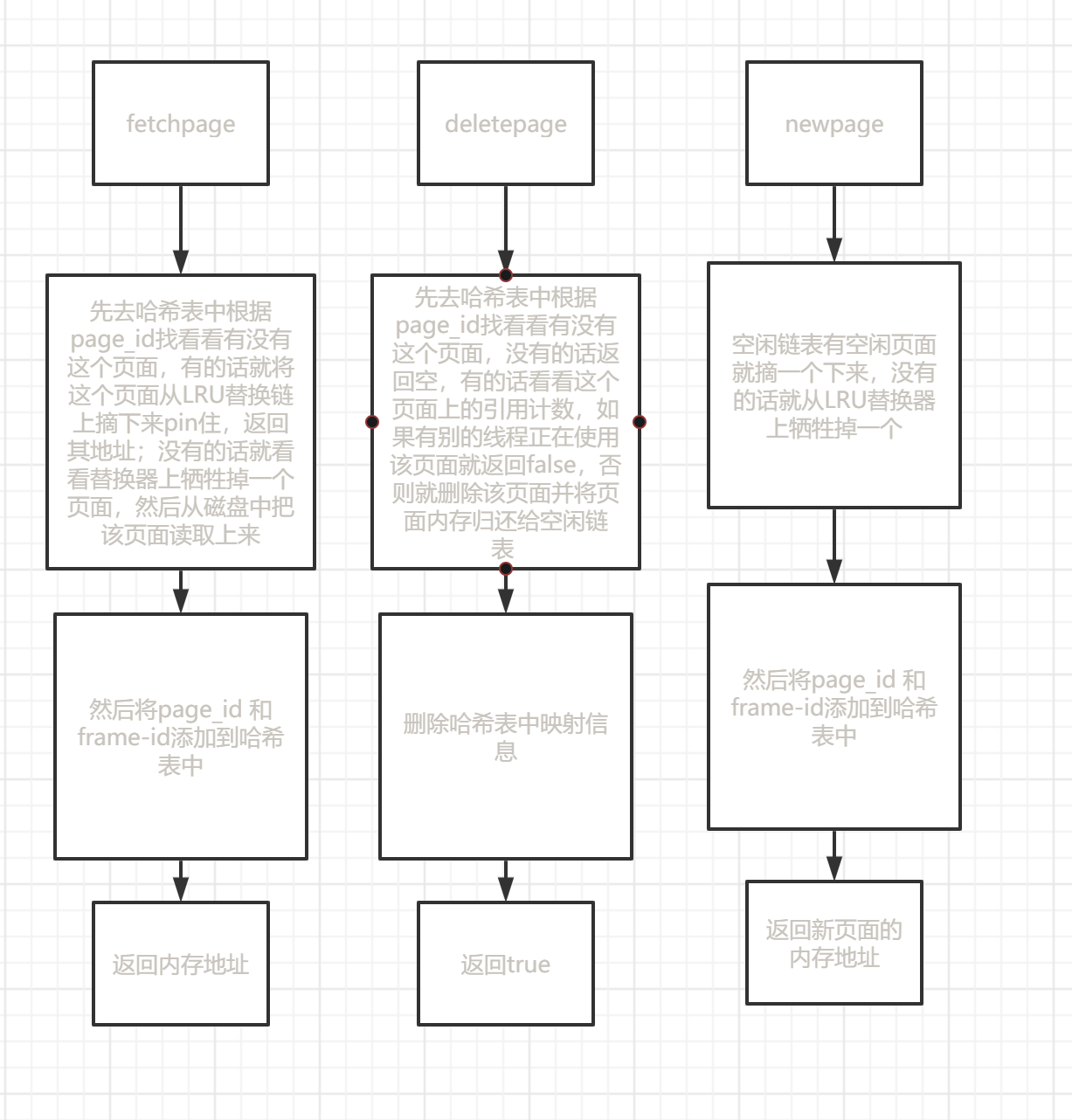
NewPageImpl
分配新页:
先在缓冲池里面分配:如果缓冲池里面没满–>直接从空闲链表上摘一个空闲页面进行分配;如果缓冲池里面满了–>利用LRU替换掉一页
Page *BufferPoolManager::NewPageImpl(page_id_t *page_id)
2021-03-07
并发控制
从上到下的话:
对于读而言:先给父节点上读锁,再给子节点上读锁,然后再释放父节点的锁,类似螃蟹爬的时候那个一个腿动了以后另外一个腿跟上
对于写而言:先给父节点上写锁,再给子节点上锁,查看是否是安全的,如果是安全的就释放父节点的锁;
从左到右的话:
对于下图从左到右的查询和从右到左的查询,每个节点上加两个锁是可以的,因为读锁可以被共享;
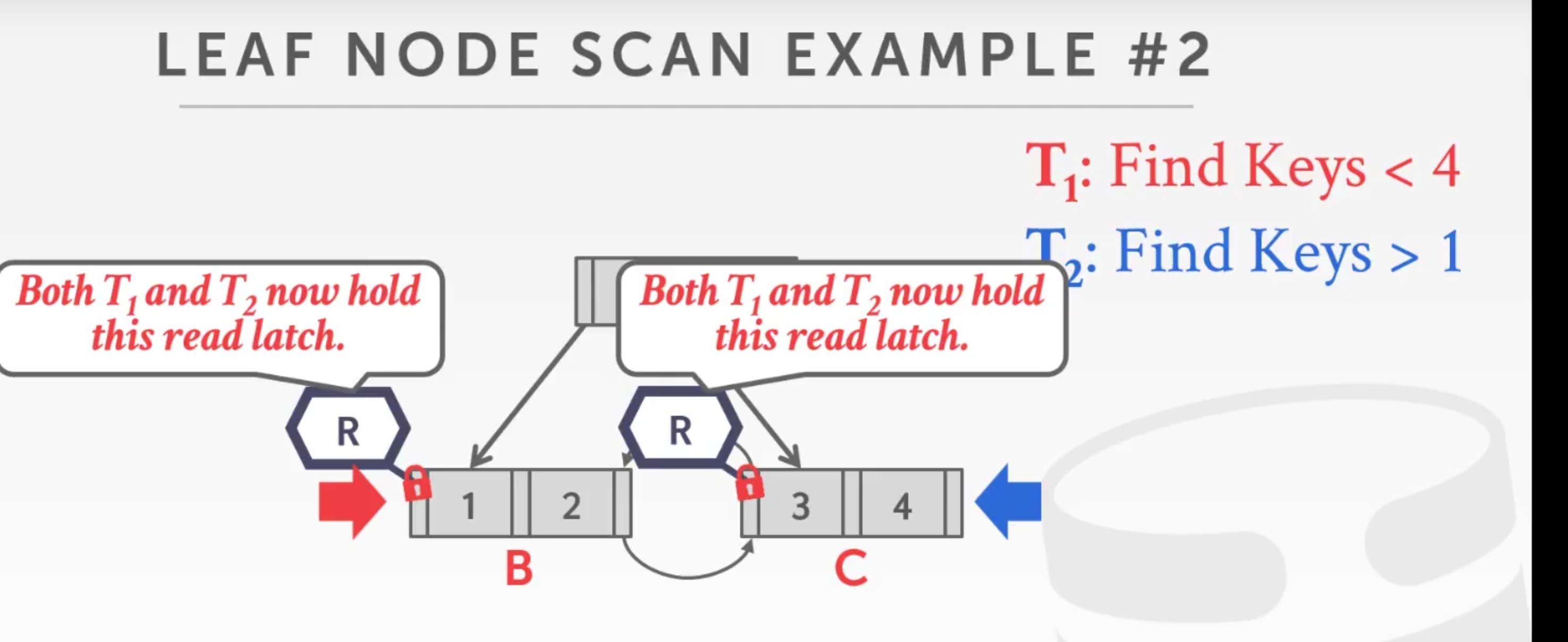
对于下图所示,盲目的等待不是一个好的办法,最好就是t2自杀掉


B+树索引的逻辑
啥时候分裂?
当插入数据的时候发现数量已经达到最大数量之后开始分裂:先在BPM中申请一个新的页面,然后将一半的数据移动到新的页面;然后将新的页面的第一个节点插入到索引节点上
2021-03-17
https://zhuanlan.zhihu.com/p/137647823

对于越慢的设备,选择越大的节点数量:因为这样一次可以读取很多索引到内存里。但是也不是无限大,需要根据你的工作量来定:如果你是范围查询比较多的话,节点数量越多肯定越好。但是如果你是从根到叶子的定点查询的话肯定是节点数量越少越好:因为多了的话每次做二分很费劲的好不好。

2021-03-18
昨天美团面试我的时候问了我如果某一列的索引很长该怎么办?我说的是可以利用哈希来做。
仔细看了PPT,对于长度不一致的列索引,一种方法是将其在元组中的位置做成指针,可是感觉这样不大好排序啊:你一个地址怎么二分出原来属性的大小关系呢?

有的索引会重复。一种就是储存重复的索引和数据。二是对于重复的构建一个链表。

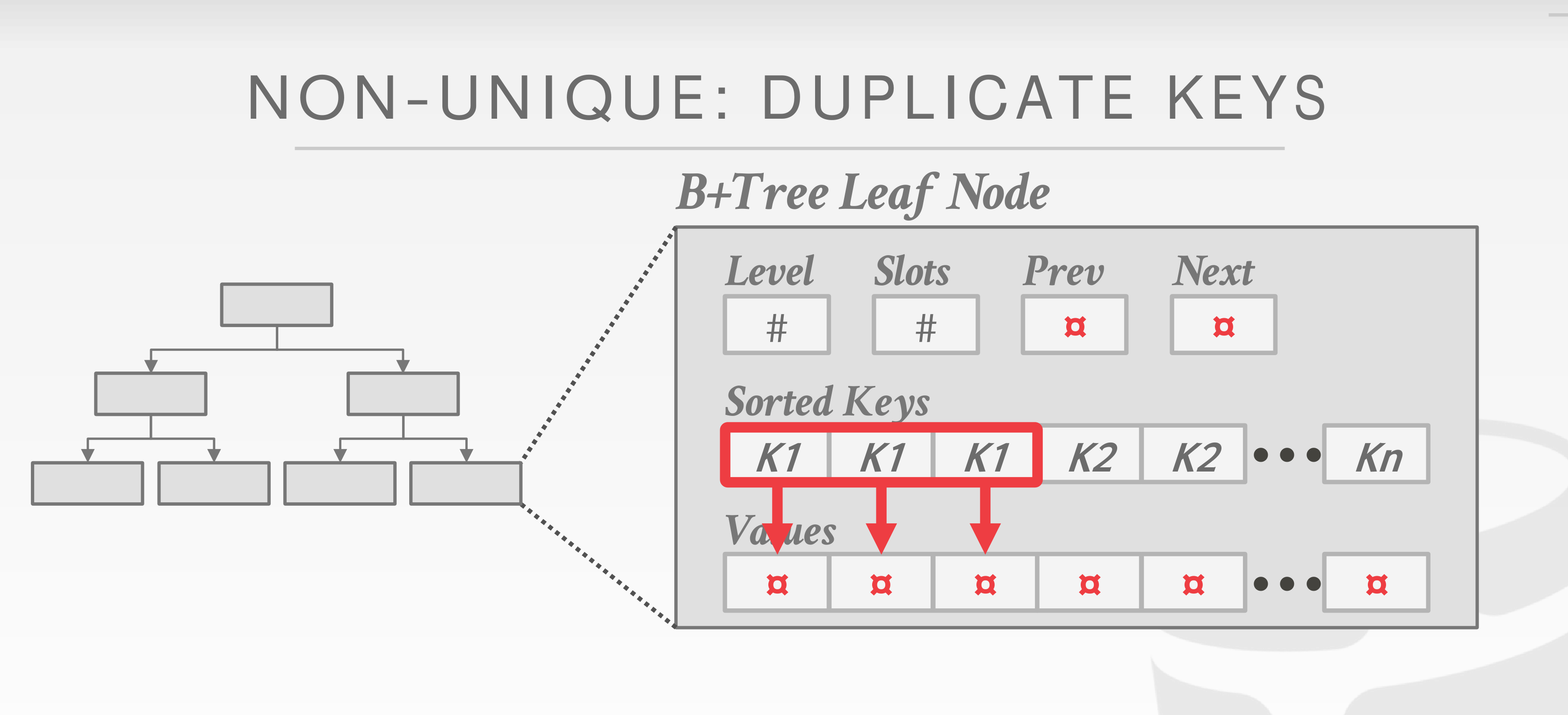
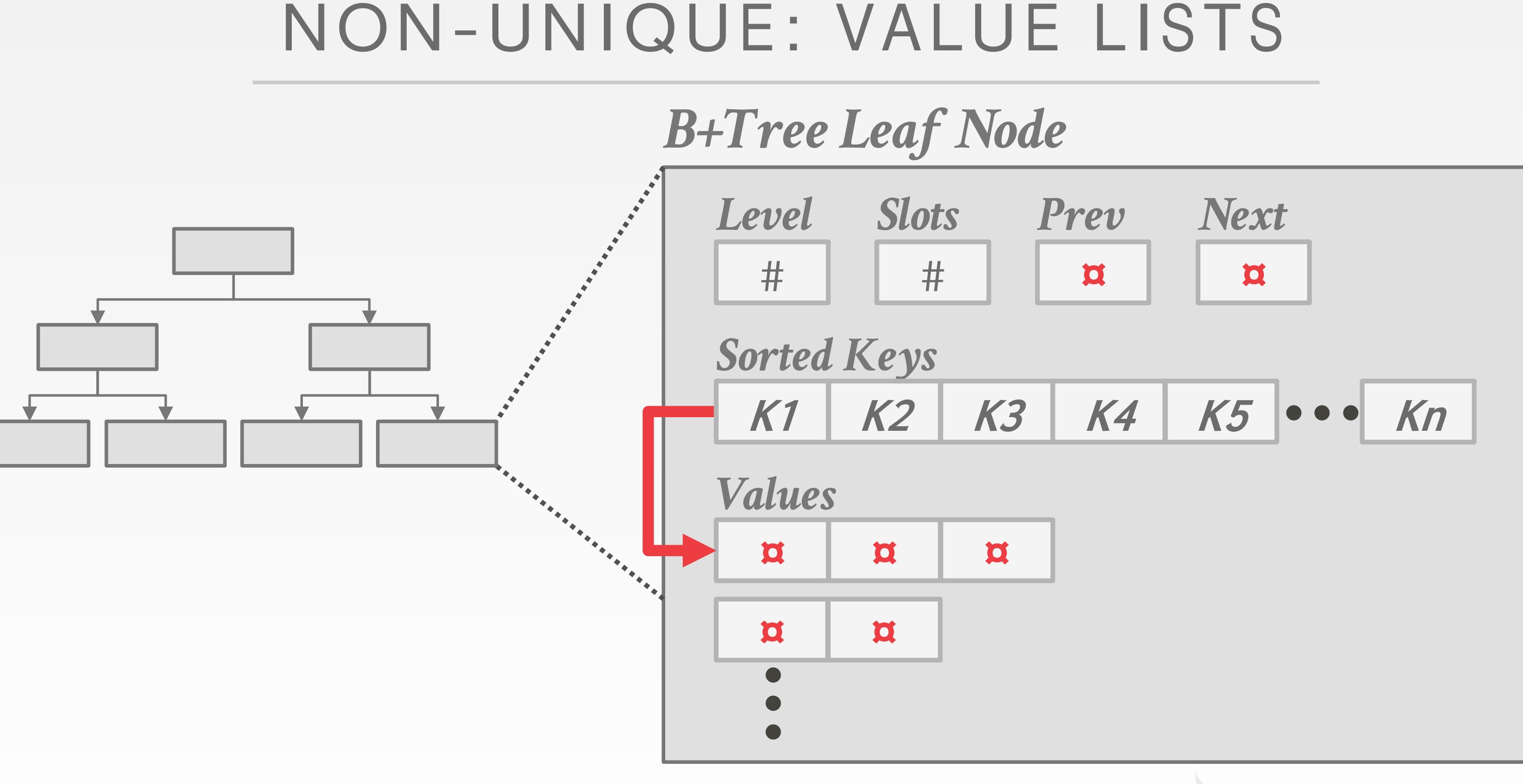
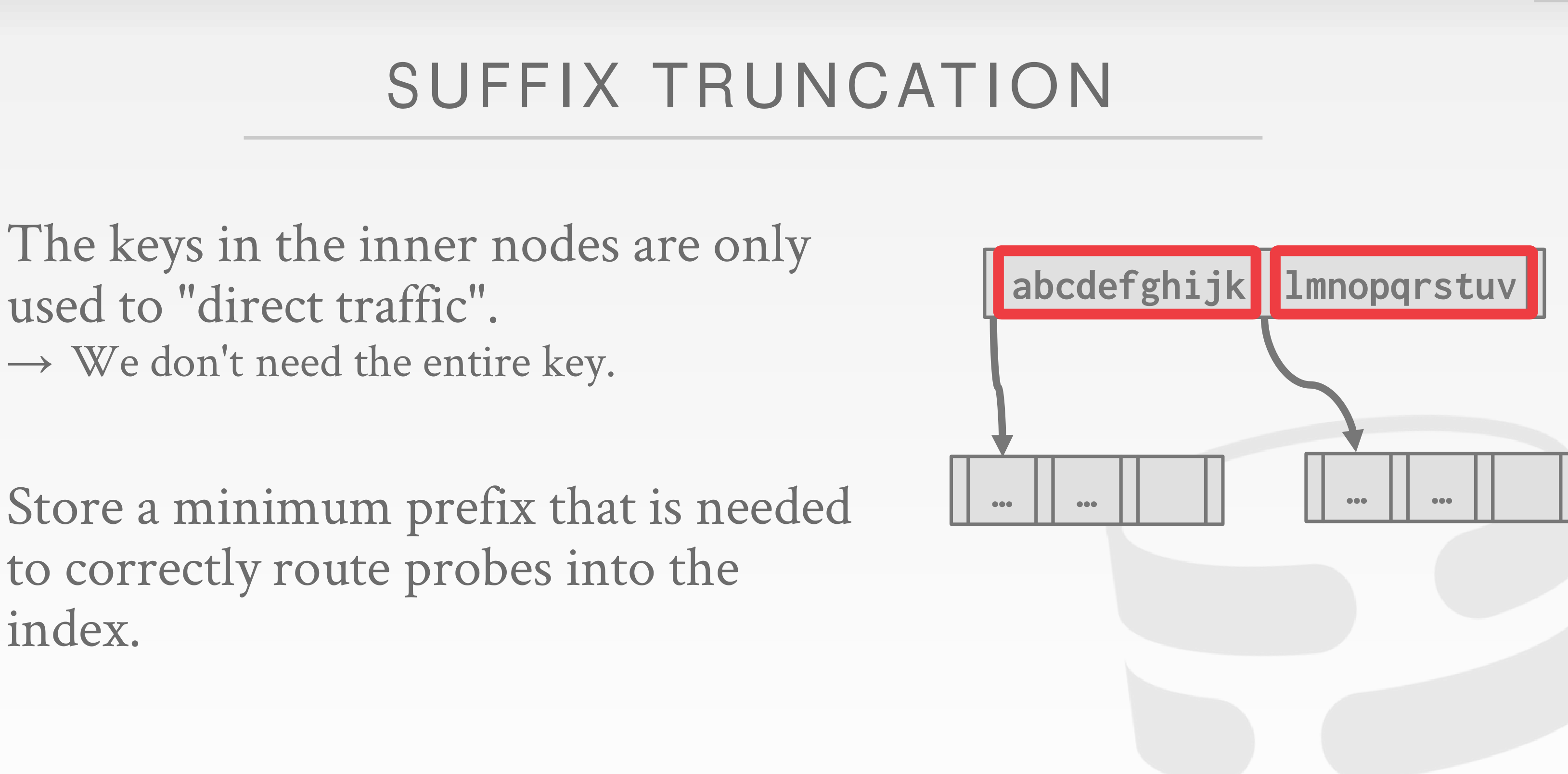
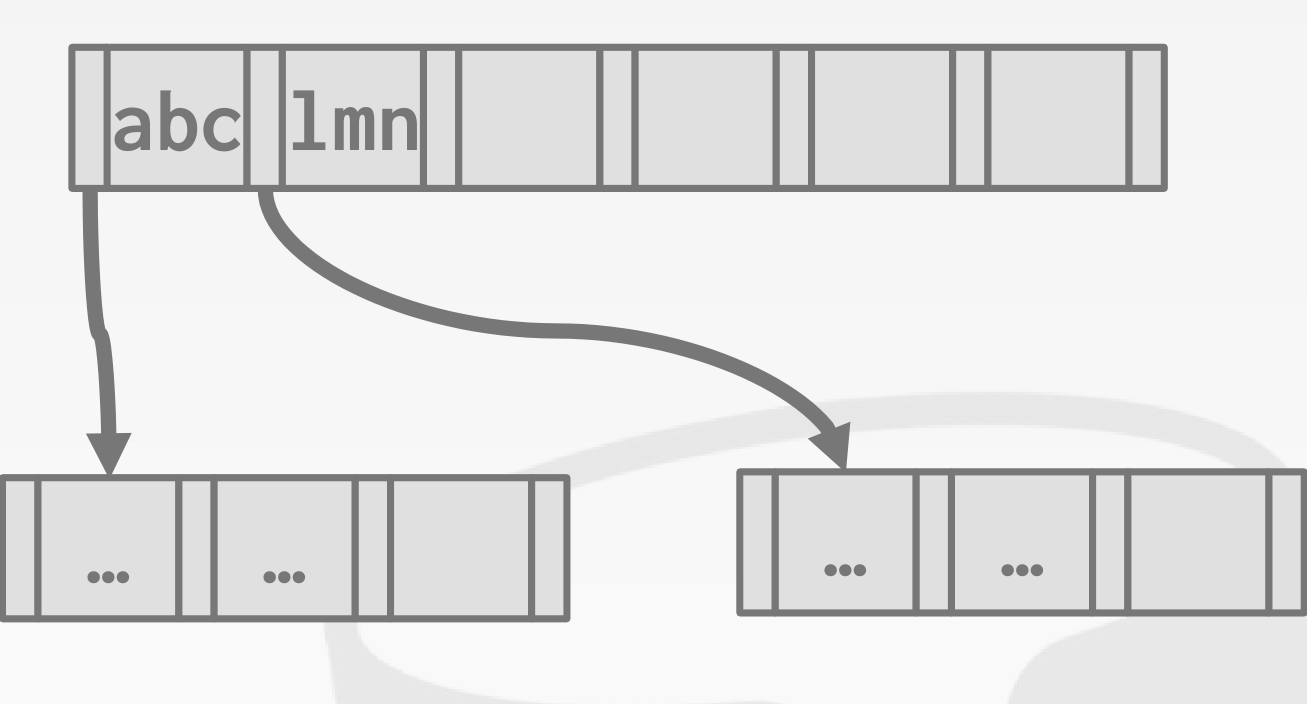
对于在同一个叶子节点的索引啊,他们可能具有相同的前缀,可以提取出来做成压缩前缀。

我不需要存储那么长的索引,只需要存储能将探针路由到正确索引的就可以了
2021-04-02
包括项目介绍,线程池相关,并发模型相关,HTTP报文解析相关,定时器相关,日志相关,压测相关,综合能力等。
项目介绍
- 为什么要做这样一个项目?
- 介绍下你的项目
线程池相关
- 手写线程池
- 线程的同步机制有哪些?
- 线程池中的工作线程是一直等待吗?
- 你的线程池工作线程处理完一个任务后的状态是什么?
- 如果同时1000个客户端进行访问请求,线程数不多,怎么能及时响应处理每一个呢?
- 如果一个客户请求需要占用线程很久的时间,会不会影响接下来的客户请求呢,有什么好的策略呢?
并发模型相关
- 简单说一下服务器使用的并发模型?
- reactor、proactor、主从reactor模型的区别?
- 你用了epoll,说一下为什么用epoll,还有其他复用方式吗?区别是什么?
HTTP报文解析相关
- 用了状态机啊,为什么要用状态机?
- 状态机的转移图画一下
- https协议为什么安全?
- https的ssl连接过程
- GET和POST的区别
数据库登录注册相关
- 登录说一下?
- 你这个保存状态了吗?如果要保存,你会怎么做?(cookie和session)
- 登录中的用户名和密码你是load到本地,然后使用map匹配的,如果有10亿数据,即使load到本地后hash,也是很耗时的,你要怎么优化?
- 用的mysql啊,redis了解吗?用过吗?
定时器相关
- 为什么要用定时器?
- 说一下定时器的工作原理
- 双向链表啊,删除和添加的时间复杂度说一下?还可以优化吗?
- 最小堆优化?说一下时间复杂度和工作原理
日志相关
- 说下你的日志系统的运行机制?
- 为什么要异步?和同步的区别是什么?
- 现在你要监控一台服务器的状态,输出监控日志,请问如何将该日志分发到不同的机器上?(消息队列)
压测相关
- 服务器并发量测试过吗?怎么测试的?
- webbench是什么?介绍一下原理
- 测试的时候有没有遇到问题?
综合能力
- 你的项目解决了哪些其他同类项目没有解决的问题?
- 说一下前端发送请求后,服务器处理的过程,中间涉及哪些协议?