这篇文章记述了关于HTTPS的知识点。
服务器会产生一对私钥和公钥,私钥自己妥善保管,公钥则分发给各个客户端。客户端利用这个公钥将要发的信息进行加密,这样即使中间人手里也有公钥(因为服务器分发公钥的时候是普而无私的),它也利用公钥解不开这个客户端用公钥加密过的信息。因为只有私钥才可以解密公钥加密的信息。
这是为什么呢?

我第一个错误的想法是既然客户端是利用服务器的公钥加密过的,那么中间人也可以利用公钥解密出这条信息(这很明显是错误的,因为你不能使用锁头去打开锁头,你只能使用钥匙去打开锁头),还有一个错误的想法是既然中间人公钥都有了,它也可以根据公钥反推出私钥来。(这从理论上来讲是可能的,但是需要花费大量的时间去金钱,比如你手里有一个锁头,你需要把它拆开然后根据弹子的尺寸去磨制钥匙,这太费劲了。放在公私钥中,则需要时间很长的运算才能解出来私钥,这不值得)
现在我们还存在一个问题,如果公钥被中间人拿到篡改呢:
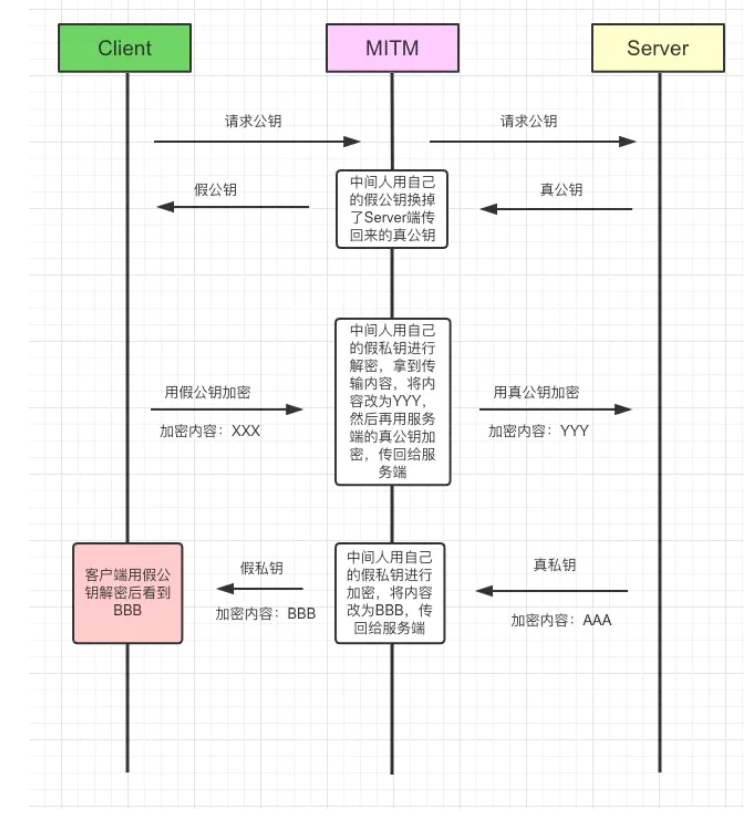
客户端拿到的公钥是假的,如何解决这个问题?
第三方认证
公钥被掉包,是因为客户端无法分辨传回公钥的到底是中间人,还是服务器,这也是密码学中的身份验证问题。
在HTTPS中,使用 证书 + 数字签名 来解决这个问题。
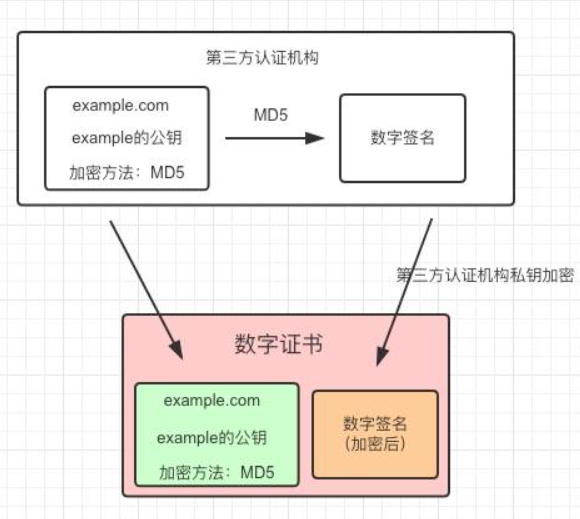
这里假设加密方式是MD5,将网站的信息加密后通过第三方机构的私钥再次进行加密,生成数字签名。
数字证书 = 网站信息 + 数字签名
假如中间人拦截后把服务器的公钥替换为自己的公钥,因为数字签名的存在,会导致客户端验证签名不匹配,这样就防止了中间人替换公钥的问题。
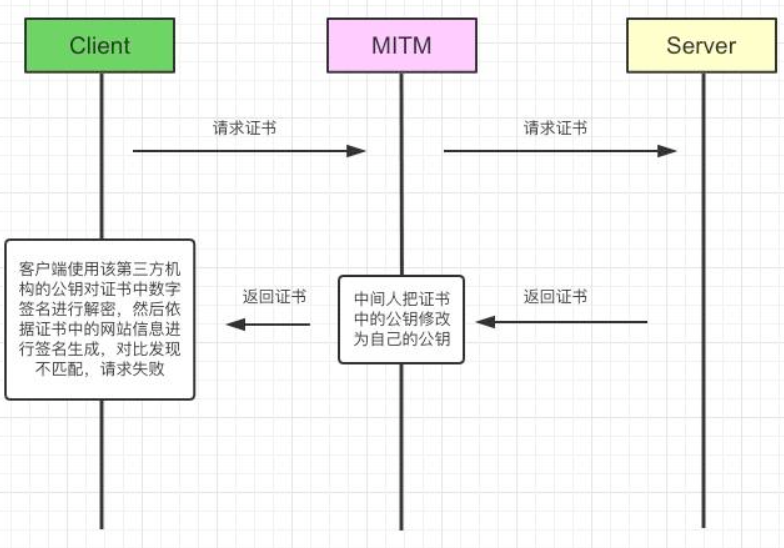
浏览器安装后会内置一些权威第三方认证机构的公钥,比如VeriSign、Symantec以及GlobalSign等等,验证签名的时候直接就从本地拿到相应第三方机构的公钥,对私钥加密后的数字签名进行解密得到真正的签名,然后客户端利用签名生成规则进行签名生成,看两个签名是否匹配,如果匹配认证通过,不匹配则获取证书失败。
补:
数字证书是如何保证公钥来自请求的服务器呢?数字证书上有持有人的相关信息,通过这点可以确定其不是一个中间人;但是证书也是可以伪造的,如何保证证书为真呢?
一个证书中含有三个部分:”证书内容,散列算法,加密密文”,证书内容会被散列算法hash计算出hash值,然后使用CA机构提供的私钥进行RSA加密。
当客户端发起请求时,服务器将该数字证书发送给客户端,客户端通过CA机构提供的公钥对加密密文进行解密获得散列值(数字签名),同时将证书内容使用相同的散列算法进行Hash得到另一个散列值,比对两个散列值,如果两者相等则说明证书没问题。
- 客户端发送一个
ClientHello消息到服务器端,消息中同时包含了它的 Transport Layer Security (TLS) 版本,可用的加密算法和压缩算法。- 服务器端向客户端返回一个
ServerHello消息,消息中包含了服务器端的 TLS 版本,服务器所选择的加密和压缩算法,以及数字证书认证机构(Certificate Authority,缩写 CA)签发的服务器公开证书,证书中包含了公钥。客户端会使用这个公钥加密接下来的握手过程,直到协商生成一个新的对称密钥。证书中还包含了该证书所应用的域名范围(Common Name,简称 CN),用于客户端验证身份。- 客户端根据自己的信任 CA 列表,验证服务器端的证书是否可信。如果认为可信(具体的验证过程在下一节讲解),客户端会生成一串伪随机数,使用服务器的公钥加密它。这串随机数会被用于生成新的对称密钥
- 服务器端使用自己的私钥解密上面提到的随机数,然后使用这串随机数生成自己的对称主密钥
- 客户端发送一个
Finished消息给服务器端,使用对称密钥加密这次通讯的一个散列值- 服务器端生成自己的 hash 值,然后解密客户端发送来的信息,检查这两个值是否对应。如果对应,就向客户端发送一个
Finished消息,也使用协商好的对称密钥加密- 从现在开始,接下来整个 TLS 会话都使用对称秘钥进行加密,传输应用层(HTTP)内容
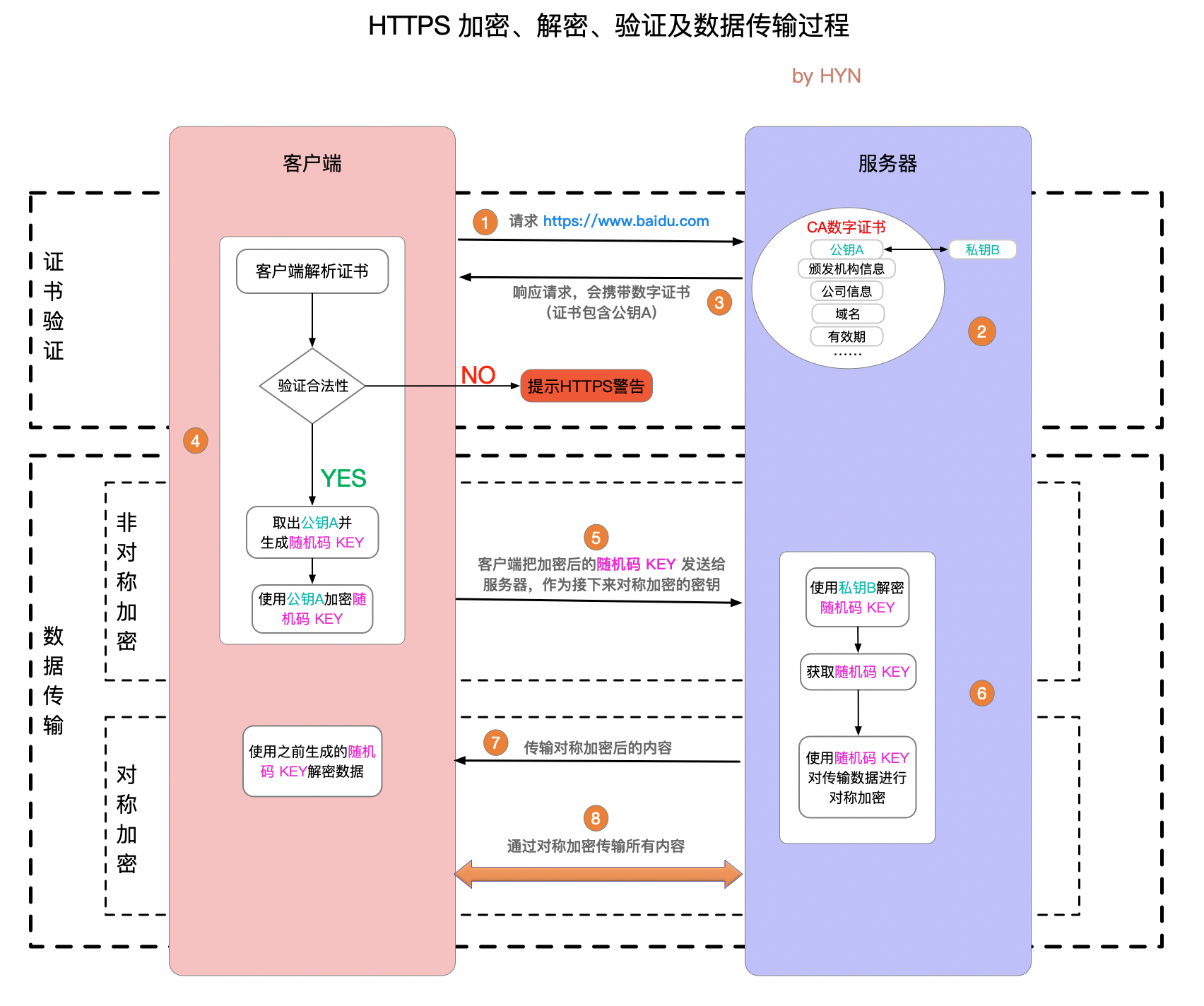
1.客户端请求 HTTPS 网址,然后连接到 server 的 443 端口 (HTTPS 默认端口,类似于 HTTP 的80端口)。
2.采用 HTTPS 协议的服务器必须要有一套数字 CA (Certification Authority)证书,证书是需要申请的,并由专门的数字证书认证机构(CA)通过非常严格的审核之后颁发的电子证书 (当然了是要钱的,安全级别越高价格越贵)。颁发证书的同时会产生一个私钥和公钥。私钥由服务端自己保存,不可泄漏。公钥则是附带在证书的信息中,可以公开的。证书本身也附带一个证书电子签名,这个签名用来验证证书的完整性和真实性,可以防止证书被篡改。
3.服务器响应客户端请求,将证书传递给客户端,证书包含公钥和大量其他信息,比如证书颁发机构信息,公司信息和证书有效期等。Chrome 浏览器点击地址栏的锁标志再点击证书就可以看到证书详细信息。
4.客户端解析证书并对其进行验证。如果证书不是可信机构颁布,或者证书中的域名与实际域名不一致,或者证书已经过期,就会向访问者显示一个警告,由其选择是否还要继续通信。就像下面这样:
如果证书没有问题,客户端就会从服务器证书中取出服务器的公钥A。然后客户端还会生成一个随机码 KEY,并使用公钥A将其加密。
5.客户端把加密后的随机码 KEY 发送给服务器,作为后面对称加密的密钥。
6.服务器在收到随机码 KEY 之后会使用私钥B将其解密。经过以上这些步骤,客户端和服务器终于建立了安全连接,完美解决了对称加密的密钥泄露问题,接下来就可以用对称加密愉快地进行通信了。
7.服务器使用密钥 (随机码 KEY)对数据进行对称加密并发送给客户端,客户端使用相同的密钥 (随机码 KEY)解密数据。
8.双方使用对称加密愉快地传输所有数据。
为什么要有签名?
大家可以想一下,为什么要有数字签名这个东西呢?
第三方认证机构是一个开放的平台,我们可以去申请,中间人也可以去申请呀:
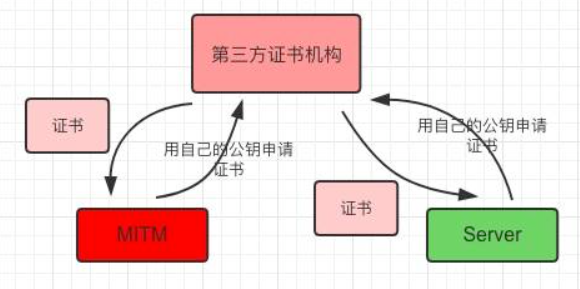
如果没有签名,只对网站信息进行第三方机构私钥加密的话,会存在下面的问题:
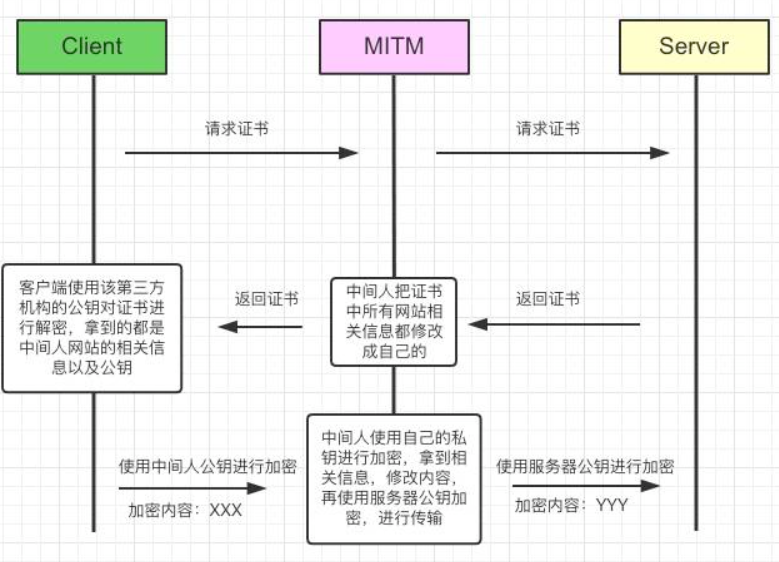
因为没有认证,所以中间人也向第三方认证机构进行申请,然后拦截后把所有的信息都替换成自己的,客户端仍然可以解密,并且无法判断这是服务器的还是中间人的,最后造成数据泄露。
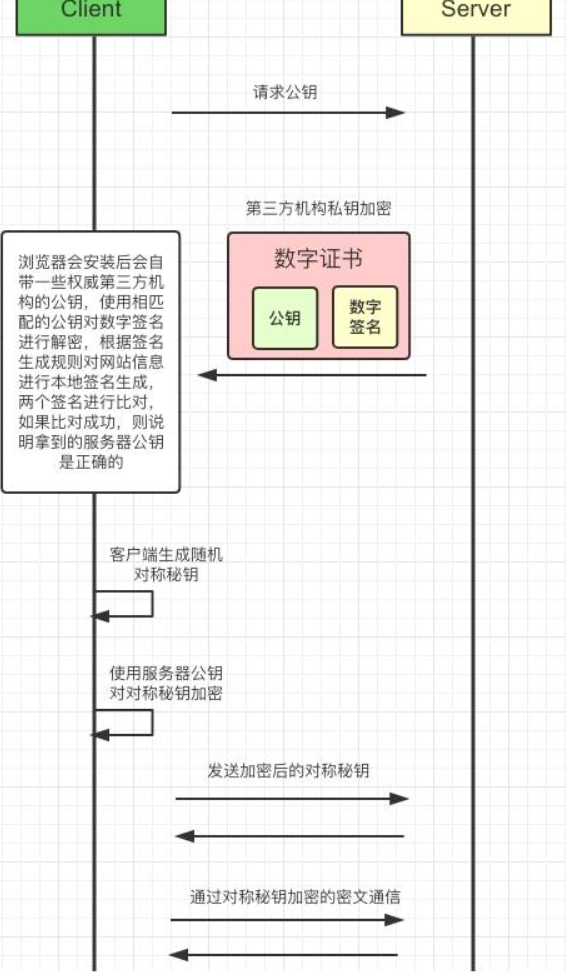
对称加密
在安全的拿到服务器的公钥之后,客户端会随机生成一个对称秘钥,使用服务器公钥加密,传输给服务端,此后,相关的 Application Data 就通过这个随机生成的对称秘钥进行加密/解密,服务器也通过该对称秘钥进行解密/加密:
总结
HTTPS就是使用SSL/TLS协议进行加密传输,让客户端拿到服务器的公钥,然后客户端随机生成一个对称加密的秘钥,使用公钥加密,传输给服务端,后续的所有信息都通过该对称秘钥进行加密解密,完成整个HTTPS的流程。
公钥私钥非对称加密
看一个小时候经常在《趣味数学》这类书里的一个数学小魔术:
让对方任意想一个3位数,并把这个数和91相乘[公钥],然后告诉我积的最后三位数,我就可以猜出对方想的是什么数字啦!比如对方想的是123,那么对方就计算出123 * 91等于11193,并把结果的末三位193告诉我。看起来,这么做似乎损失了不少信息,让我没法反推出原来的数。不过,我仍然有办法:只需要把对方告诉我的结果再乘以11[私钥],乘积的末三位就是对方刚开始想的数了。可以验证一下,193 * 11 = 2123,末三位正是对方所想的秘密数字!
其实道理很简单,91乘以11等于1001,而任何一个三位数乘以1001后,末三位显然都不变(例如123乘以1001就等于123123)。
知道原理后,我们可以构造一个定义域和值域更大的加密解密系统。比方说,任意一个数乘以400000001后,末8位都不变,而400000001 = 19801 * 20201,于是你来乘以19801,我来乘以20201,又一个加密解密不对称的系统就构造好了。
HTTP状态码
2XX 表示请求被服务器理解接受
3XX 重定向
这类状态码表示客户端需要进一步操作才能完成请求
301:Moved Permnately
被请求的资源已经永远的转移到新的位置(新的URI),将来要是再访问这个资源就使用这个新的URI就可以了。
302:Found
要求客户端执行临时重定向(原始描述短语为“Moved Temporarily”)。[20]由于这样的重定向是临时的,客户端应当继续向原有地址发送以后的请求。
404 Not Found
请求失败,请求所希望得到的资源未被在服务器上发现,但允许用户的后续请求。
501 (尚未实施) 服务器不具备完成请求的功能。 例如,服务器无法识别请求方法时可能会返回此代码。
502 (错误网关) 服务器作为网关或代理,从上游服务器收到无效响应。
503 (服务不可用) 服务器目前无法使用(由于超载或停机维护)。 通常,这只是暂时状态
HTTP cookie session 的区别
类似这种面试题,实际上都属于“开放性”问题,你扯到哪里都可以。不过如果我是面试官的话,我还是希望对方能做到一点——
不要混淆 session 和 session 实现。
本来 session 是一个抽象概念,开发者为了实现中断和继续等操作,将 user agent 和 server 之间一对一的交互,抽象为“会话”,进而衍生出“会话状态”,也就是 session 的概念。
而 cookie 是一个实际存在的东西,http 协议中定义在 header 中的字段。可以认为是 session 的一种后端无状态实现。
而我们今天常说的 “session”,是为了绕开 cookie 的各种限制,通常借助 cookie 本身和后端存储实现的,一种更高级的会话状态实现。
所以 cookie 和 session,你可以认为是同一层次的概念,也可以认为是不同层次的概念。具体到实现,session 因为 session id 的存在,通常要借助 cookie 实现,但这并非必要,只能说是通用性较好的一种实现方案。
一句话: session的常见实现要借助cookie来发送sessionID.
作者:欲三更
链接:https://www.zhihu.com/question/19786827/answer/84540780
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
1,session 在服务器端,cookie 在客户端(浏览器)
2,session 默认被存在在服务器的一个文件里(不是内存)
3,session 的运行依赖 session id,而 session id 是存在 cookie 中的,也就是说,如果浏览器禁用了 cookie ,同时 session 也会失效(但是可以通过其它方式实现,比如在 url 中传递 session_id)
4,session 可以放在 文件、数据库、或内存中都可以。
5,用户验证这种场合一般会用 session因此,维持一个会话的核心就是客户端的唯一标识,即 session id
作者:冯特罗
链接:https://www.zhihu.com/question/19786827/answer/21643186
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
http是无状态的协议,客户每次读取web页面时,服务器都打开新的会话,而且服务器也不会自动维护客户的上下文信息,那么要怎么才能实现网上商店中的购物车呢,session就是一种保存上下文信息的机制,它是针对每一个用户的,变量的值保存在服务器端,通过SessionID来区分不同的客户,session是以cookie或URL重写为基础的,默认使用cookie来实现,系统会创造一个名为JSESSIONID的输出cookie,我们叫做session cookie,以区别persistent cookies,也就是我们通常所说的cookie,注意session cookie是存储于浏览器内存中的,并不是写到硬盘上的,这也就是我们刚才看到的JSESSIONID,我们通常情是看不到JSESSIONID的,但是当我们把浏览器的cookie禁止后,web服务器会采用URL重写的方式传递Sessionid,我们就可以在地址栏看到 sessionid=KWJHUG6JJM65HS2K6之类的字符串。
作者:wuxinliulei
链接:https://www.zhihu.com/question/19786827/answer/66706108
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
四、HTTP 2.0 和 1.1 区别
后面我们将通过几个方面来说说HTTP 2.0 和 HTTP1.1 区别,并且和你解释下其中的原理。
区别一:多路复用
多路复用允许单一的 HTTP/2 连接同时发起多重的请求-响应消息。看个例子:
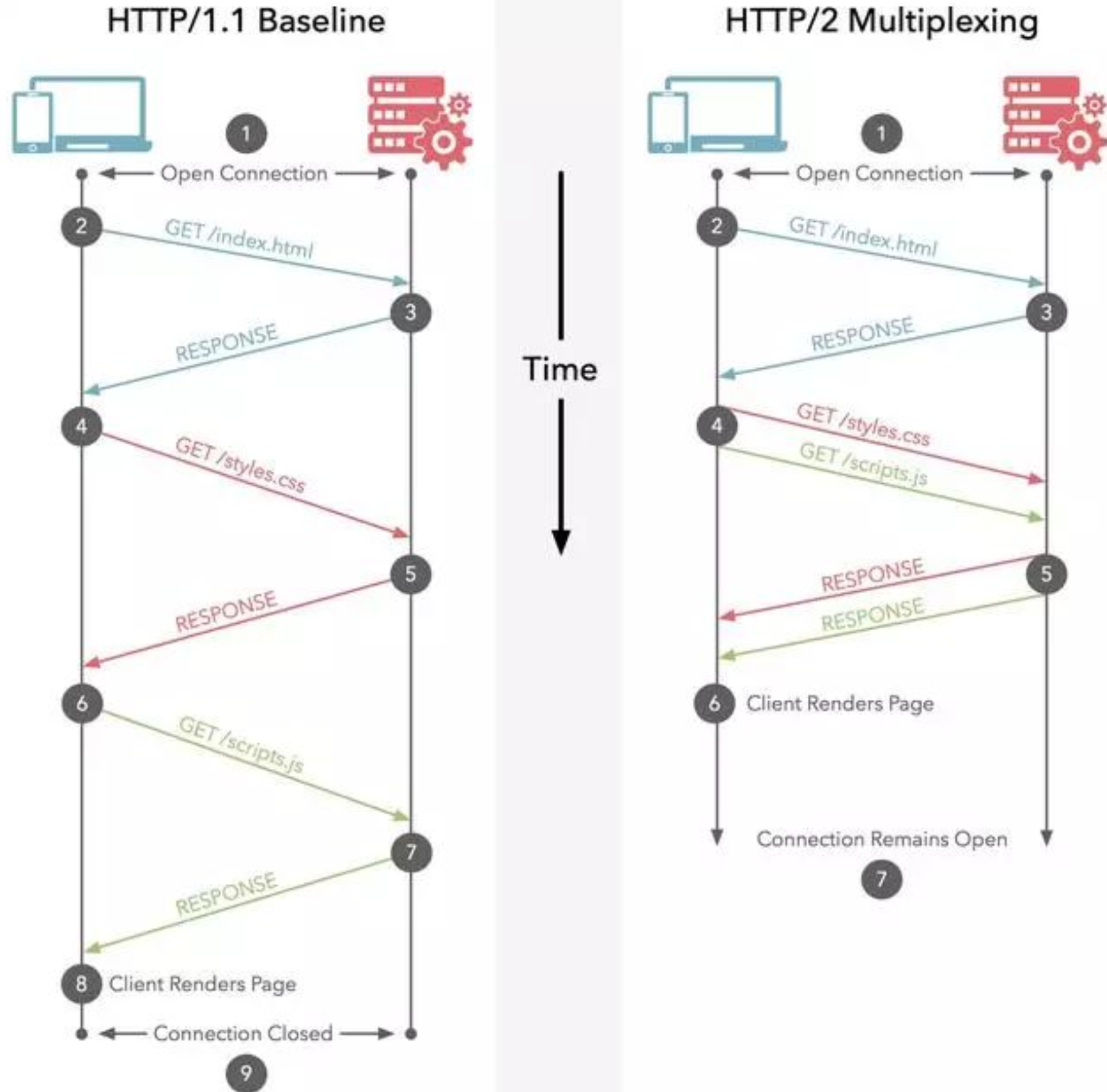
整个访问流程第一次请求index.html页面,之后浏览器会去请求style.css和scripts.js的文件。左边的图是顺序加载两个个文件的,右边则是并行加载两个文件。
我们知道HTTP底层其实依赖的是TCP协议,那问题是在同一个连接里面同时发生两个请求响应着是怎么做到的?
首先你要知道,TCP连接相当于两根管道(一个用于服务器到客户端,一个用于客户端到服务器),管道里面数据传输是通过字节码传输,传输是有序的,每个字节都是一个一个来传输。
例如客户端要向服务器发送Hello、World两个单词,只能是先发送Hello再发送World,没办法同时发送这两个单词。不然服务器收到的可能就是HWeolrllod(注意是穿插着发过去了,但是顺序还是不会乱)。这样服务器就懵b了。
接上面的问题,能否同时发送Hello和World两个单词能,当然也是可以的,可以将数据拆成包,给每个包打上标签。发的时候是这样的①H ②W ①e ②o ①l ②r ①l ②l ①o ②d。这样到了服务器,服务器根据标签把两个单词区分开来。实际的发送效果如下图:
区别二:首部压缩
为什么要压缩?在 HTTP/1 中,HTTP 请求和响应都是由「状态行、请求 / 响应头部、消息主体」三部分组成。一般而言,消息主体都会经过 gzip 压缩,或者本身传输的就是压缩过后的二进制文件(例如图片、音频),但状态行和头部却没有经过任何压缩,直接以纯文本传输。
随着 Web 功能越来越复杂,每个页面产生的请求数也越来越多,导致消耗在头部的流量越来越多,尤其是每次都要传输 UserAgent、Cookie 这类不会频繁变动的内容,完全是一种浪费。
使用HAPCK算法对header数据进行压缩,使数据体积变小,传输更快
区别三:HTTP2支持服务器推送
服务端推送是一种在客户端请求之前发送数据的机制。当代网页使用了许多资源:HTML、样式表、脚本、图片等等。在HTTP/1.x中这些资源每一个都必须明确地请求。这可能是一个很慢的过程。浏览器从获取HTML开始,然后在它解析和评估页面的时候,增量地获取更多的资源。因为服务器必须等待浏览器做每一个请求,网络经常是空闲的和未充分使用的。
为了改善延迟,HTTP/2引入了server push,它允许服务端推送资源给浏览器,在浏览器明确地请求之前。一个服务器经常知道一个页面需要很多附加资源,在它响应浏览器第一个请求的时候,可以开始推送这些资源。这允许服务端去完全充分地利用一个可能空闲的网络,改善页面加载时间。
http1.0
仅支持保持短暂的TCP链接
不追踪ip
http1.1
支持长连接
纯文本报头
增加了更多的请求头和响应头
连接数过多 容易队首阻塞 且串行传输
http2.0
多路复用,并行请求
二进制报头 数据帧
对报头压缩,降低开销
服务器主动推送,减少请求延迟
默认使用加密 增加伪头字段
就当每天做面试题了 每天巩固提升一下