这篇文章记述了关于C++输入输出的知识点。
Linux 多线程多进程文件读写
文件的写入也是如此,拿到offet,调用实际的写入方法,最后更新offset。到此为止一个文件的读和写的大体过程我们是清楚了,很显然上述的过程并不是原子的,无论是文件的读还是写,都至少有两个步骤,一个是拿offset,另外一个则是实际的读和写。并且在整个过程中并没有看到加锁的动作,那么第一个问题就得到了解决。对于第二个问题我们可以简要的分析下,假如有两个线程,第一个线程拿到offset是1,然后开始写入,在写入的过程中,第二个线程也去拿offset,因为对于一个文件来说多个线程是共享同一个struct file结构,因此拿到的offset仍然是1,这个时候线程1写结束,更新offset,然后线程2开始写。最后的结果显而易见,线程2覆盖了线程1的数据,通过分析可知,多线程写文件不是原子的,会产生数据覆盖。但是否会产生数据错乱,也就是数据交叉写入了?其实这种情况是不会发生的,至于为什么请看下面这段代码:
1 | ssize_t generic_file_aio_write(struct kiocb *iocb, const struct iovec *iov, |
所以并不会产生数据错乱,只会存在数据覆盖的问题,既然如此我们在实际的进行文件读写的时候是否需要进行加锁呢? 加锁的确是可以解决问题的,但是在这里未免有点牛刀杀鸡的感觉,好在OS给我们提供了原子写入的方法,第一种就是在打开文件的时候添加O_APPEND标志,通过O_APPEND标志将获取文件的offset和文件写入放在一起用锁进行了保护,使得这两步是原子的,具体代码可以看上面代码中的__generic_file_aio_write函数。
1 | ssize_t __generic_file_aio_write(struct kiocb *iocb, const struct iovec *iov, |
最后一个问题是多个进程写同一个文件是否会造成文件写错乱,直观来说是多进程写文件不是原子的,这是很显而易见的,因为每个进程都拥有一个struct file对象,是独立的,并且都拥有独立的文件offset,所以很显然这会导致上文中说到的数据覆盖的情况,但是否会导致数据错乱呢?,答案是不会,虽然struct file对象是独立的,但是struct inode是共享的(相同的文件无论打开多少次都只有一个struct inode对象),文件的最后写入其实是先要写入到页缓存中,而页缓存和struct inode是一一对应的关系,在实际文件写入之前会加锁,而这个锁就是属于struct inode对象(见上文中的mutex_lock(&inode->i_mutex))的,所有无论有多少个进程或者线程,只要是对同一个文件写数据,拿到的都是同一把锁,是线程安全的,所以也不会出现数据写错乱的情况。
write:不会出现数据交叉的情况,而且父子进程交替执行写入。
从上面小节的测试过程可以发现,两个非亲缘关系的进程同时写一个文件时,会出现数据混乱的情况,但是两个进程写入的数据没有覆盖。
这是因为这两个进程表项中指向的对应的两个文件表项对应的当前文件偏移量是不一致的,但是由于打开文件时是使用append追加的方式,使得进程指向的文件表项中的当前文件偏移量都等于当前文件中所有数据的总长度。这就是为什么写入的数据会出现错乱,但是不会出现覆盖(偏移量不一致)的原因。
注意:内核write函数在写入时是原子操作,所以两个进程会有一个竞争关系,最终只会由某个进程写入数据。
为什么fwrite会出问题? ,因为有buf,所以就会有问题?,这块还没有讲解清楚哦,还是需要分析下的,另外write为什么不会错乱? 分析不够到位啊,我之前也写过一篇文章分析过这个问题,http://blog.csdn.net/zhangyifei216/article/details/76653746,fwrite的问题说白了其实就是用户态buf,会缓存多次写入,然后再一次性调用底层的write,所以给你的错觉就是多次写入之间交叉了(个人理解)
从文本读取数据C++
包含头文件#include
逐词读取
逐行读取
ifstream filestream("text.txt");
if (filestream.is_open()) {
}
Cin
在理解 cin 功能时,不得不提标准输入缓冲区。当我们从键盘输入字符串的时候需要敲一下回车键才能够将这个字符串送入到缓冲区中,那么敲入的这个回车键(\r)会被转换为一个换行符(\n),这个换行符也会被存储在 cin 的缓冲区中并且被当成一个字符来计算!比如我们在键盘上敲下了 123456 这个字符串,然后敲一下回车键(\r)将这个字符串送入了缓冲区中,那么此时缓冲区中的字节个数是 7 ,而不是 6。
cin 读取数据也是从缓冲区中获取数据,缓冲区为空时,cin 的成员函数会阻塞等待数据的到来,一旦缓冲区中有数据,就触发 cin 的成员函数去读取数据。
使用 cin 从标准输入读取数据时,通常用到的方法有 cin>>、cin.get(),getline(cin,str)
当 cin>> 从缓冲区中读取数据时,若缓冲区中第一个字符是空格、tab或换行这些分隔符时,cin>> 会将其忽略并清除,继续读取下一个字符,若缓冲区为空,则继续等待。
但是如果读取成功,字符后面的分隔符是残留在缓冲区的,cin>> 不做处理。
1 |
|
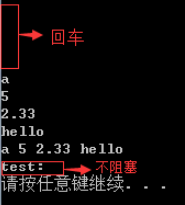
从结果可以看出,cin>> 对缓冲区中的第一个换行符视而不见,采取的措施是忽略清除,继续阻塞等待缓冲区有效数据的到来。但是,getline() 读取数据时,并非像 cin>> 那样忽略第一个换行符,getline() 发现 cin 的缓冲区中有一个残留的换行符,不阻塞请求键盘输入,直接读取,送入目标字符串后,因为读取的内容为空,所以程序中的变量 test 为空串。
cin流在读取数据之后会把回车符之前的字符拿去传递给buf然后将回车符残留在cin流中,所以当getline在读取cin流的时候会第一个读到回车符随之而退出。
解决方法很简单:
可以在getline之前使用cin.ignore()函数来将cin的残留回车符清除
1 |
|
输入:e[回车],输出:
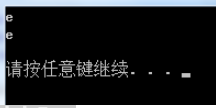
(1)从结果可以看出,cin.get(array,20);读取一行时,遇到换行符时结束读取,但是不对换行符进行处理,换行符仍然残留在输入缓冲区。第二次由cin.get()将换行符读入变量b,打印输入换行符的ASCII码值为10。这也是cin.get()读取一行与使用getline读取一行的区别所在。getline读取一行字符时,默认遇到’\n’时终止,并且将’\n’直接从输入缓冲区中删除掉,不会影响下面的输入处理。
版权声明:本文为CSDN博主「Dablelv」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/K346K346/article/details/48213811
1 | 在你写getline()函数之前,一定有使用过了回车了吧 |
1 |
|
题目描述
计算一系列数的和
输入描述:
1 | 输入数据有多组, 每行表示一组输入数据。 |
输出描述:
1 | 每组数据输出求和的结果 |
1 |
|
1 |
|
对输入的字符串进行排序后输出
输入描述:
1 | 输入有两行,第一行n |
输出描述:
1 | 输出一行排序后的字符串,空格隔开,无结尾空格 |
1 |
|
链接:https://ac.nowcoder.com/acm/contest/320/I
来源:牛客网
题目描述
对输入的字符串进行排序后输出
输入描述:
1 | 多个测试用例,每个测试用例一行。 |
输出描述:
1 | 对于每组测试用例,输出一行排序过的字符串,每个字符串通过空格隔开 |
1 |
|
find函数
1 | find(_In_z_ const _Elem* const _Ptr, const size_type _Off = 0) |
for (int j=0;j<TIMES;j++)
{
getline(cin, OPERATOR_STYLE);
int IDX;
if (OPERATOR_STYLE.find("PUSH") != OPERATOR_STYLE.npos)
{
IDX = OPERATOR_STYLE.find(" ");
int x = stoi(OPERATOR_STYLE.substr(IDX + 1));
q1.push(x);
}substr函数
1 | string substr (size_t pos = 0, size_t len = npos) const; |
string str(“12345asdf”);
string strTmp1= str.substr(1); //获得字符串str中 从第1位开始到结束的字符串,strTmp1值为:”2345asdf”
string strTmp2 = str.substr(1,5); //获得字符串s中 从第1位开始的长度为5的字符串,strTmp1值为:”2345a”
SplitString
1 | void SplitString(const string &s, vector<string> &v, const string &c) |
对输入的字符串进行排序后输出
输入描述:
多个测试用例,每个测试用例一行。
每行通过,隔开,有n个字符,n<100
1 | a,c,bb |
输出描述:
对于每组用例输出一行排序后的字符串,用’,’隔开,无结尾空格
1 | a,bb,c |
1 |
|
C语言
strcmp
#include <string.h>
int strcmp(const char *s1, const char *s2);
功能: 用来比较两个字符串
参数: s1、s2为两个进行比较的字符串
返回值: 若s1、s2字符串相等,则返回零;若s1大于s2,则返回大于零的数;否则,则返回小于零的数。
说明: strcmp()函数是根据ACSII码的值来比较两个字符串的;strcmp()函数首先将s1字符串的第一个字符值减去s2第一个字符,若差值为零则继续比较下去;若差值不为零,则返回差值。
直到出现不同的字符或遇’\0’为止。
字符串截取
strncpy函数是拷贝N个字符到另一个字符数组中的库函数
1 | char dest[4] = {0}; |
C++ string 成员函数 length() size() 和 strlen() 的区别
1、sizeof()是运算符,在编译期间就计算好了,所以对于字符串来说会统计到‘\0’的个数。(这都是早期落后的C故意设计的–字符串后面加一个\0,之后先进的length等函数都不用统计\0的个数了)
2、size()、length()是c++中string的类的方法,只有string类的对象才可以用该方法,而字符串数组不可用,size()是由于string 毕竟也是一个容器,容器会为了统一都有一个size()函数,size()与length()完全等同,遇到空字符不会被截断,可以返回字符串真实长度
3、而strlen、strcpy等源于C语言的字符串处理函数库,需要include<string.h>,同时也只有字符串数组才可以用,
strlen()遇到空字符会截断,从而无法返回字符串真实长度
strlen同样也可以用于C++的string。但是需要用c_str()将C++ string转换为char*类型。
The length of a C string is determined by the terminating null-character: A C string is as long as the number of characters between the beginning of the string and the terminating null character (without including the terminating null character itself).
This should not be confused with the size of the array that holds the string. For example:
defines an array of characters with a size of 100
chars, but the C string with which mystr has been initialized has a length of only 11 characters. Therefore, whilesizeof(mystr)evaluates to100,strlen(mystr)returns11.
sizeof stris 7 - five bytes for the “Hello” text, plus the explicit NUL terminator, plus the implicit NUL terminator.
strlen(str)is 5 - the five “Hello” bytes only.The key here is that the implicit nul terminator is always added - even if the string literal just happens to end with
\0. Of course,strlenjust stops at the first\0- it can’t tell the difference.
strlen(“aaa.txt\n”)长度为8,它只会碰到\0(十进制0)截断,空格(十进制32)换行符\n(十进制10)不会进行截断,而且最后的\0不会计入长度。

转载自http://blog.chinaunix.net/uid-27105712-id-3270102.html
在Linux 开发中,有几个关系到性能的东西,技术人员非常关注:进程,CPU,MEM,网络IO,磁盘IO。本篇文件打算详细全面,深入浅出。剖析文件IO的细节。从多个角度探索如何提高IO性能。本文尽量用通俗易懂的视角去阐述。不copy内核代码。
阐述之前,要先有个大视角,让我们站在万米高空,鸟瞰我们的文件IO,它们设计是分层的,分层有2个好处,一是架构清晰,二是解耦。让我们看一下下面这张图。
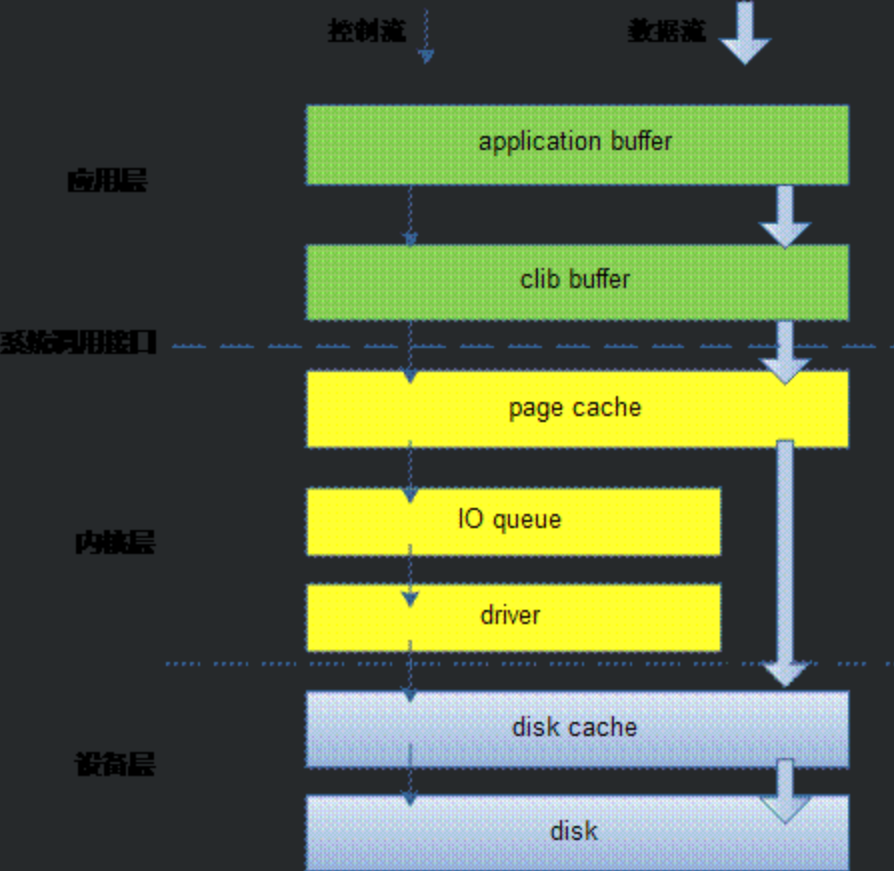
- 穿越各层写文件方式
程序的最终目的是要把数据写到磁盘上, 但是系统从通用性和性能角度,尽量提供一个折中的方案来保证这些。让我们来看一个最常用的写文件典型example,也是路径最长的IO。
1 | { |
这里malloc的buf对于图层中的application buffer,即应用程序的buffer;调用fwrite后,把数据从application buffer 拷贝到了 CLib buffer,即C库标准IObuffer。fwrite返回后,数据还在CLib buffer,如果这时候进程core掉。这些数据会丢失。没有写到磁盘介质上。当调用fclose的时候,fclose调用会把这些数据刷新到磁盘介质上。除了fclose方法外,还有一个主动刷新操作fflush 函数,不过fflush函数只是把数据从CLib buffer 拷贝到page cache 中,并没有刷新到磁盘上,从page cache刷新到磁盘上可以通过调用fsync函数完成。
从上面类子看到,一个常用的fwrite函数过程,基本上历经千辛万苦,数据经过多次copy,才到达目的地。有人心生疑问,这样会提高性能吗,反而会降低性能吧。这个问题先放一放。有人说,我不想通过fwrite+fflush这样组合,我想直接写到page cache。这就是我们常见的文件IO调用read/write函数。这些函数基本上是一个函数对应着一个系统调用,如sys_read/sys_write. 调用write函数,是直接通过系统调用把数据从应用层拷贝到内核层,从application buffer 拷贝到 page cache 中。
系统调用,write会触发用户态/内核态切换?是的。那有没有办法避免这些消耗。这时候该mmap出场了,mmap把page cache 地址空间映射到用户空间,应用程序像操作应用层内存一样,写文件。省去了系统调用开销。
那如果继续刨根问底,如果想绕过page cache,直接把数据送到磁盘设备上怎么办。通过open文件带上O_DIRECT参数,这是write该文件。就是直接写到设备上。
如果继续较劲,直接写扇区有没有办法。这就是所谓的RAW设备写,绕开了文件系统,直接写扇区,想fdsik,dd,cpio之类的工具就是这一类操作。
- IO调用链
列举了上述各种穿透各种cache 层写操作,可以看到系统提供的接口相当丰富,满足你各种写要求。下面通过讲解图一,了解一下文件IO的调用链。
fwrite是系统提供的最上层接口,也是最常用的接口。它在用户进程空间开辟一个buffer,将多次小数据量相邻写操作先缓存起来,合并,最终调用write函数一次性写入(或者将大块数据分解多次write调用)。
Write函数通过调用系统调用接口,将数据从应用层copy到内核层,所以write**会触发内核态**/**用户态切换。当数据到达page cache后,内核并不会立即把数据往下传递。而是返回用户空间。数据什么时候写入硬盘,有内核IO调度决定,所以write**是一个异步调用。这一点和read不同,read调用是先检查page cache里面是否有数据,如果有,就取出来返回用户,如果没有,就同步传递下去并等待有数据,再返回用户,所以read是一个同步过程。当然你也可以把write的异步过程改成同步过程,就是在open文件的时候带上O_SYNC标记。
数据到了page cache后,内核有pdflush线程在不停的检测脏页,判断是否要写回到磁盘中。把需要写回的页提交到IO队列——即IO调度队列。又IO调度队列调度策略调度何时写回。
提到IO调度队列,不得不提一下磁盘结构。这里要讲一下,磁头和电梯一样,尽量走到头再回来,避免来回抢占是跑,磁盘也是单向旋转,不会反复逆时针顺时针转的。从网上copy一个图下来,具体这里就不介绍。
IO队列有2个主要任务。一是合并相邻扇区的,而是排序。合并相信很容易理解,排序就是尽量按照磁盘选择方向和磁头前进方向排序。因为磁头寻道时间是和昂贵的。
这里IO队列和我们常用的分析工具IOStat关系密切。IOStat中rrqm/s wrqm/s表示读写合并个数。avgqu-sz表示平均队列长度。
内核中有多种IO调度算法。当硬盘是SSD时候,没有什么磁道磁头,人家是随机读写的,加上这些调度算法反而画蛇添足。OK,刚好有个调度算法叫noop调度算法,就是什么都不错(合并是做了)。刚好可以用来配置SSD硬盘的系统。
从IO队列出来后,就到了驱动层(当然内核中有更多的细分层,这里忽略掉),驱动层通过DMA,将数据写入磁盘cache。
至于磁盘cache时候写入磁盘介质,那是磁盘控制器自己的事情。如果想要睡个安慰觉,确认要写到磁盘介质上。就调用fsync函数吧。可以确定写到磁盘上了。
- 一致性和安全性
谈完调用细节,再将一下一致性问题和安全问题。既然数据没有到到磁盘介质前,可能处在不同的物理内存cache中,那么如果出现进程死机,内核死,掉电这样事件发生。数据会丢失吗。
当进程死机后:只有数据还处在application cache或CLib cache时候,数据会丢失。数据到了page cache。进程core掉,即使数据还没有到硬盘。数据也不会丢失。当内核core掉后,只要数据没有到达disk cache,数据都会丢失。掉电情况呢,哈哈,这时候神也救不了你,哭吧。
那么一致性呢,如果两个进程或线程同时写,会写乱吗?或A进程写,B进程读,会写脏吗?
文章写到这里,写得太长了,就举出各种各样的例子。讲一下大概判断原则吧。fwrite操作的buffer是在进程私有空间,两个线程读写,肯定需要锁保护的。如果进程,各有各的地址空间。是否要加锁,看应用场景。
write操作如果写大小小于PIPE_BUF(一般是4096),是原子操作,能保证两个进程“AAA”,“BBB”写操作,不会出现“ABAABB”这样的数据交错。O_APPEND 标志能保证每次重新计算pos,写到文件尾的原子性。
数据到了内核层后,内核会加锁,会保证一致性的。
- 性能问题
性能从系统层面和设备层面去分析;磁盘的物理特性从根本上决定了性能。IO的调度策略,系统调用也是致命杀手。
磁盘的寻道时间是相当的慢,平均寻道时间大概是在10ms,也就是是每秒只能100-200次寻道。
磁盘转速也是影响性能的关键,目前最快15000rpm,大概就每秒500转,满打满算,就让磁头不寻道,设想所有的数据连续存放在一个柱面上。大家可以算一下每秒最多可以读多少数据。当然这个是理论值。一般情况下,盘片转太快,磁头感应跟不上,所以需要转几圈才能完全读出磁道内容。
另外设备接口总线传输率是实际速率的上限。
另外有些等密度磁盘,磁盘外围磁道扇区多,线速度快,如果频繁操作的数据放在外围扇区,也能提高性能。
利用多磁盘并发操作,也不失为提高性能的手段。
这里给个业界经验值:机械硬盘顺序写~30MB,顺序读取速率一般~50MB好的可以达到100多M, SSD读达到~400MB,SSD写性能和机械硬盘差不多。
Ps:
O_DIRECT 和 RAW设备最根本的区别是O_DIRECT是基于文件系统的,也就是在应用层来看,其操作对象是文件句柄,内核和文件层来看,其操作是基于inode和数据块,这些概念都是和ext2/3的文件系统相关,写到磁盘上最终是ext3文件。
而RAW设备写是没有文件系统概念,操作的是扇区号,操作对象是扇区,写出来的东西不一定是ext3文件(如果按照ext3规则写就是ext3文件)。
一般基于O_DIRECT来设计优化自己的文件模块,是不满系统的cache和调度策略,自己在应用层实现这些,来制定自己特有的业务特色文件读写。但是写出来的东西是ext3文件,该磁盘卸下来,mount到其他任何linux系统上,都可以查看。
而基于RAW设备的设计系统,一般是不满现有ext3的诸多缺陷,设计自己的文件系统。自己设计文件布局和索引方式。举个极端例子:把整个磁盘做一个文件来写,不要索引。这样没有inode限制,没有文件大小限制,磁盘有多大,文件就能多大。这样的磁盘卸下来,mount到其他linux系统上,是无法识别其数据的。
两者都要通过驱动层读写;在系统引导启动,还处于实模式的时候,可以通过bios接口读写raw设备。
stevenrao 深圳写于2012 年 情人节。献给天下有情码农
文件IO之我见
read函数是怎么实现的?
read 会使用一个参数叫 fd,文件描述符,在内核中通过fd定位到文件打开表项。
这里我有个疑问,内核中一定存在文件打开表项吗?万一第一次打开,内核中肯定是没有这个文件打开表项的哈。其实我们打开文件都会通过open函数查询一个路径,这个时候文件打开表项就已经被加载到内核里了。文件打开表项的内容主要是Inode节点,偏移,访问状态等。
在inode中,通过文件内容偏移量计算出要读取的页;
这个地方也有个疑问,inode节点里存放着以下内容:文件的字节数、拥有者、修改时间、有多少个文件名指向该inode节点、文件数据block的指针数组等。
这里着重说一下这个引用连接数,类似于智能指针的那个原则,有一个文件名该引用数就加一、删除一个文件名就减一,等引用数为0时,OS就会回收该inode节点和其指向的block 区域。这里顺便说一下目录文件的”链接数”。创建目录时,默认会生成两个目录项:”.”和”..”。前者的inode号码就是当前目录的inode号码,等同于当前目录的”硬链接”;后者的inode号码就是当前目录的父目录的inode号码,等同于父目录的”硬链接”。所以,任何一个目录的”硬链接”总数,总是等于2加上它的子目录总数(含隐藏目录)。
通过 inode 找到文件对应的 address_space;
在 address_space 中访问该文件的页缓存树,查找对应的页缓存结点:
- 如果页缓存命中,那么直接返回文件内容;
- 如果页缓存缺失,那么产生一个页缺失异常,创建一个页缓存页,同时通过 inode 找到文件该页的磁盘地址,读取相应的页填充该缓存页;重新进行第 6 步查找页缓存;
文件内容读取成功