这篇文章主要记述编译原理以及链接的一些知识点。
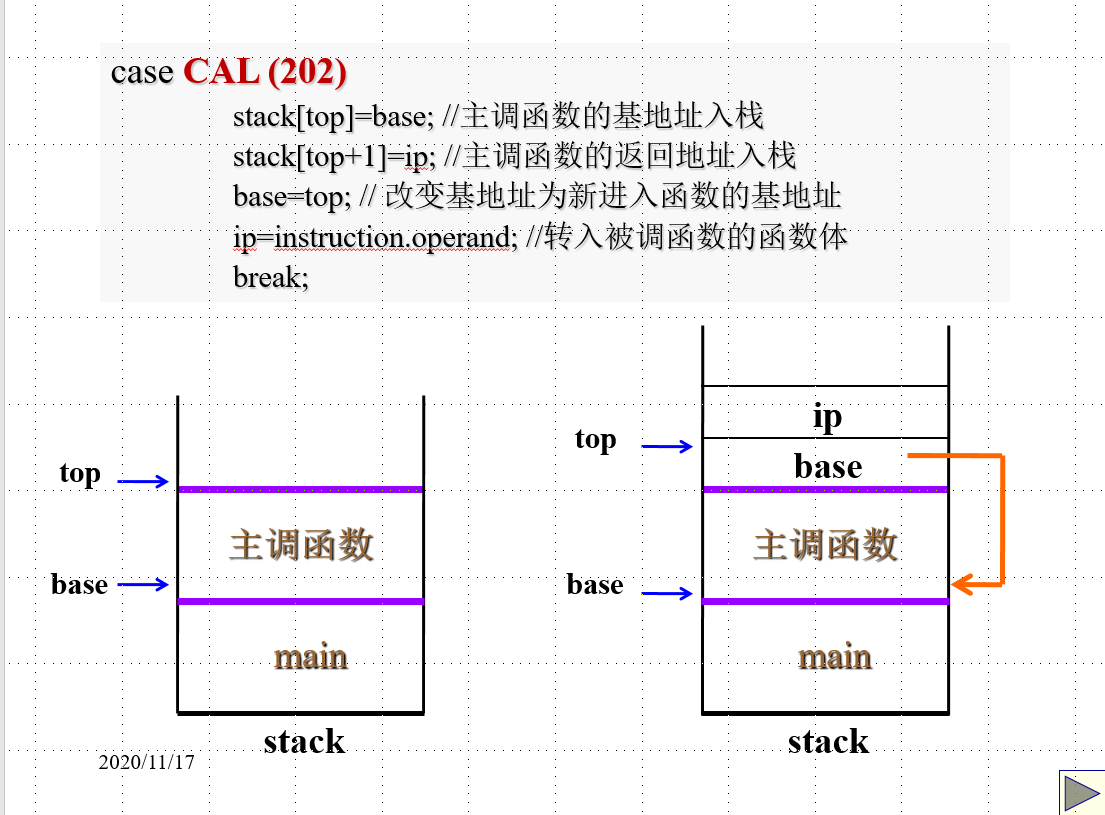
调用一个函数时,先把自己的基地址入栈,防止从函数退出时找不到主调函数的基地址,这样的话一些偏移就不好计算了;
接着还要把函数返回后要执行的下一条指令的地址要入栈;
比如:ip 就会保存 printf 的地址,为了从 add 函数返回之后能执行 printf !
1 | int main(){ |
链接原理
在编译的过程中,如果所有的代码都写到一个单独的文件里,由于编译器以文件为单位进行编译,所以可以一次性的拿到所有的函数,那么就可以就地处理所有的符号,显然这是编译器最喜闻乐见的事情。但是由于有外部库和工程组织的需要,不可能所有的代码都在同一个文件里,编译器是用来满足开发人员的需要的,不是反过来。所以编译器要想办法解决不同文件之间的链接问题。
编译器在编译一个文件的时候,会生成一个段的划分。这个划分通常名字大同小异(当然可以通过写link脚本改变段的命名和排布),但是.text, .data这种常用的代码段和数据段基本没有人会有其他想法。每个文件编译的时候生成了同样的.text段,链接器用来处理多个编译单元的(也就是.o文件),将这些文件链接在一起的时候,链接器的主要工作就是将同样的段进行合并。这个操作看起来简单,但是不断.o文件互相调用的情况该怎么解决呢?例如A文件调用了B文件的test函数,在编译A的时候看不到B中test函数的定义,那么这个A里面的B的test函数的地址该如何填充?链接器在进行链接的时候又该如何修正?
首先可以确定的是A里面在链接发生之前是肯定不能知道B中test的地址的,但是A里面的汇编结果的call指令的目的地址总需要填充个值。这个值就是0,就是在编译A的时候,发现A调用了别人的test函数,编译器会直接在call的A函数的位置填call 0地址,然后同时,在A的目标文件的一个.rel.text和.rel.data。这两个表叫做重定向表,用于在链接的时候组装不同的目标文件,一个是函数重定向,一个是数据重定向。里面存储的信息就是在A的某某偏移位置调用了test函数。当链接发生的时候,链接器查看A的重定向标发现A需要test的地址,然后在B的函数定义中查找test的定义和地址(是A和B的.text合并之后的地址),然后用这个地址去修改A对应的偏移里面的call指令。这样就完成了链接时的重定位。
这个重定位发生在所有的静态链接的时候,包括静态链接库的时候和链接自己的代码文件的时候。
但是我们知道还有一个很常见的应用是动态链接。动态链接的时候,符号的位置要在运行的过程中才会解析。编译的时候分为PIC的编译方式和非PIC的传统编译方式(现在大部分库都是使用PIC的方式)。两个的区别在于能不能在内存中重用库的代码。
非PIC的传统编译方式需要在加载库的时候就重新设置所有的符号。例如liba.so里面调用了libb.so里面的一个函数test,那么按照静态链接的思路liba.so需要暴露一个段里面存放需要重定位的符号(也就是 call test的偏移),在加载libb.so的时候就要立刻解析出liba.so里面的call指令对应的test函数的地址。
这种情况相当于liba.so的.text段的内容在加载的时候被修改了。也就是说liba.so的.text的位置在不同的程序里面是不一样的(因为libb.so在不同的进程不一定在同样的位置)。所以liba.so在内存中不能复用,也就是每个进程都要在内存中加载一份liba.so的.text,liba.so使用了多少次就需要加载多少份。
这样有问题吗?除了内存里有多份liba.so外,并没有什么问题。有一个特点是加载的时候需要解析全部的符号,即使没有用到的,这样加载的速度相对慢一些。
动态链接用到了.rel.dyn和.rel.plt(PLT:过程链接表)。前者是数据重定向,后者是函数重定向。两个段的功能与静态链接的重定向表是一样的。这一切都显得那么轻松。
但是毕竟程序员是追求完美的,针对这两个问题,追求完美的程序员想出了PIC模式。所谓的PIC模式就是位置无关,就是想办法让liba.so的.text在所有使用liba.so的进程之间复用。这样只依赖.rel.dyn和.rel.plt可能就做不到了。因为使用这两个表是需要修改.text段的内容的。所以又添加了.got和.got.plt两个表,同样的,前者对应数据,后者对应函数。这两个段就是PIC的实现方法了。
所谓的PIC就是在编译liba.so的call test函数的时候,不是在test函数的地址位置填充0,而是填充liba.so的.got.plt段的test地址。在编译的时候.got.plt中的test的地址是空的,显然是不能寻址的,但是call test指令却是直接固定的调用.got.plt的表的test函数的(虽然这个函数还不知道在哪定义)。.got.plt相当于一个桩子,call test就是调用了这里的桩子函数。由于.got.plt不是位于.text里面,所以在解析的时候只需要修改.got.plt里面的test的定义地址就可以找到真实的定义,无论libb.so加载到内存的什么位置,都是只需要找到它,然后填充liba.so的.got.plt的test函数条目即可。如此.text就可以实现复用了。第一个问题解决。
第二个问题就是延迟绑定的技术。这个技术是为了防止加载的时候解析所有的符号,而是让用的时候才解析。所需要的技术在应用了PIC之后几乎是现成的。就是.got.plt中的内容不是加载的时候填充,而是用到的时候填充。这一切由运行时的链接器完成(interpreter)。
C编译与运行时栈
1 | int functt(int num) { |
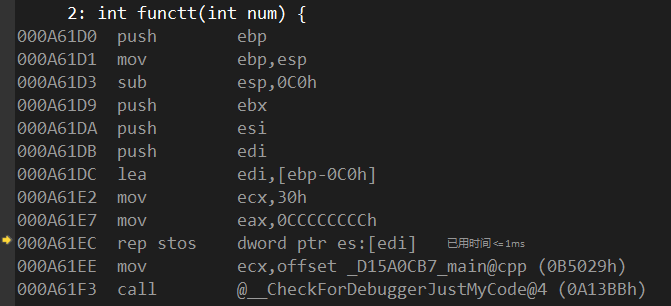
??一旦进入call,先将EBP压栈,因为接下来将把EBP移动到ESP位置,为什么要这么做?
call指令实际动作是push eip;mov eip,4111D6h连续两条指令.
ret指令实际动作是pop eip
我们总结一下:每次调用别的函数时,先将EIP指针入栈–然后将EBP入栈
1 | case CAL: |
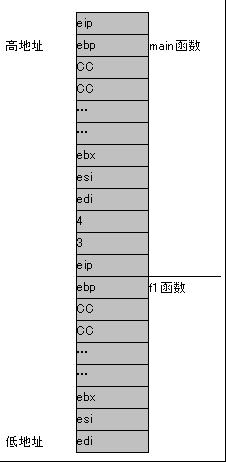
This is an reference-style link
??为什么要将ESP往下移动192(0C0 Hex)个字节?
–他们说是为该函数留出临时存储区!192Bytes存储int数据(4Bytes)也只不过是48个int。当我们试图去分配一个50个元素的局部变量时看看会发生什么?
1 | int functt(int num) { |
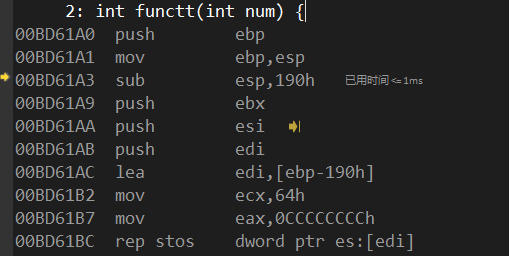
ESP往低地址移动了190H=400Bytes,看来就是多留出一块局部变量的存储区域出来。
从lea指令到rep这条指令作用就是把为局部变量分配的内存空间填充CC数据。Stos将eax中数据放入es:[edi]中,同时edi增加4个字节。Rep使指令重复执行ecx次数。
动态链接库
1 | / 根目录 |
一个问题
No rule to make target ‘/usr/lib/x86_64-linux-gnu/libGL.so’
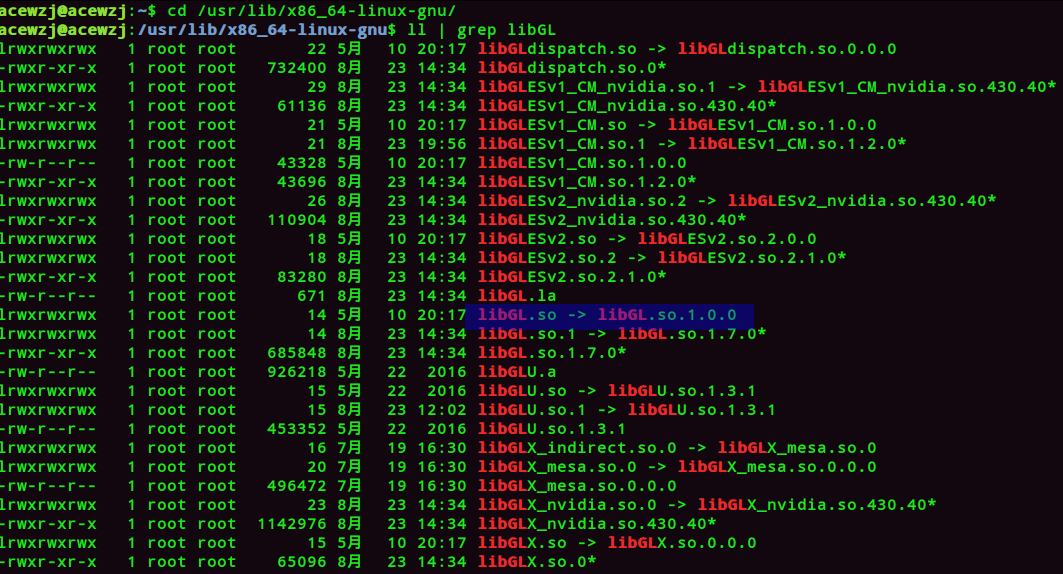
在编译Ogre的时候make install出现了这个问题,这里发现我的libGL.so指向了libGL.so.1.0.0,这是怎么一回事呢?
搜索libGL.so文件路径: 比如,本机中路径为:/usr/lib/libGL.so
建立symlink: sudo ln -s /usr/lib/libGL.so.1 /usr/lib/x86_64-linux-gnu/libGL.so (之所以链接到libGL.so.1而不是libGL.so可能是为了便于区分)
如果出现错误: ln: failed to create symbolic link ‘/usr/lib/x86_64-linux-gnu/libGL.so’ : File exists
则删除已有链接: sudo rm /usr/lib/x86_64-linux-gnu/libGL.so
重新执行步骤2建立symlink
为什么要使用动态链接库?
–《鸟哥的私房菜》中提及:动态函数库在编译的时候,在程序里面只有一个“指向”(Pointer)的位置而已,也就是说,动态函数库的内容并没有被整合到可执行文件中,而是当可执行文件要使用到函数库的时候程序才会读取函数库来使用。由于可执行文件中仅仅具有指向动态函数库所在的指标而已,并不包含函数库的内容,所以它的文件比较小一点。以下摘自APUE:
如何将动态函数库加载到高速缓存中呢?
– 1.首先,我们必须在/etc/ld.so.conf 文件夹里面写下想要读入高速缓存当中的动态函数库所在的目录,注意是目录而不是文件。
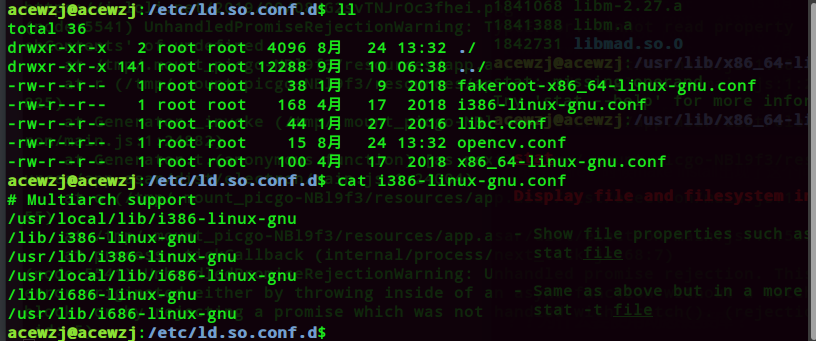
2.接下来利用ldconfig这个可执行文件将/etc/ld.so.conf.d的数据读入缓存中;
3.同时也将数据记录一份在/etc/ld.so.cache 这个文件当中。
Tips:可以使用ldconfig -p指令查看函数库内容(ld.so.cache)
CMakeLists.txt
1 | cmake_minimum_required(VERSION 3.5)# 规定最低版本 |
find_package原理
首先明确一点,cmake本身不提供任何搜索库的便捷方法,所有搜索库并给变量赋值的操作必须由cmake代码完成,比如下面将要提到的FindXXX.cmake和XXXConfig.cmake。只不过,库的作者通常会提供这两个文件,以方便使用者调用。
find_package采用两种模式搜索库:
Module模式:搜索CMAKE_MODULE_PATH指定路径下的FindXXX.cmake文件,执行该文件从而找到XXX库。其中,具体查找库并给XXX_INCLUDE_DIRS和XXX_LIBRARIES两个变量赋值的操作由FindXXX.cmake模块完成。
Config模式:搜索XXX_DIR指定路径下的XXXConfig.cmake文件,执行该文件从而找到XXX库。其中具体查找库并给XXX_INCLUDE_DIRS和XXX_LIBRARIES两个变量赋值的操作由XXXConfig.cmake模块完成。
两种模式看起来似乎差不多,不过cmake默认采取Module模式,如果Module模式未找到库,才会采取Config模式。如果XXX_DIR路径下找不到XXXConfig.cmake文件,则会找/usr/local/lib/cmake/XXX/中的XXXConfig.cmake文件。总之,Config模式是一个备选策略。通常,库安装时会拷贝一份XXXConfig.cmake到系统目录中,因此在没有显式指定搜索路径时也可以顺利找到。
在我遇到的问题中,由于Caffe安装时没有安装到系统目录,因此无法自动找到CaffeConfig.cmake,我在CMakeLists.txt最前面添加了一句话之后就可以了。
set(Caffe_DIR /home/wjg/projects/caffe/build) #添加CaffeConfig.cmake的搜索路径
add_definitions
代码中通过宏 USE_MACRO 作为区分.
...
#ifdef USE_MACRO
...
#endif
我们可以通过在项目中的CMakeLists.txt 中添加如下代码控制代码的开启和关闭.
1 | + OPTION(USE_MACRO |
关于Windows下与Linux下文件编码格式的讨论
跨平台的程序从GitHub 上下载下来导入到 visual studio 经常报莫名奇怪的错误,经查发现是文件编码的问题。接下来详细记录一下这个问题:
首先,怎么查看Windows 下一个文件的编码格式呢?
很简单,就是用记事本打开并点击另存为就可以看到文件是什么格式了
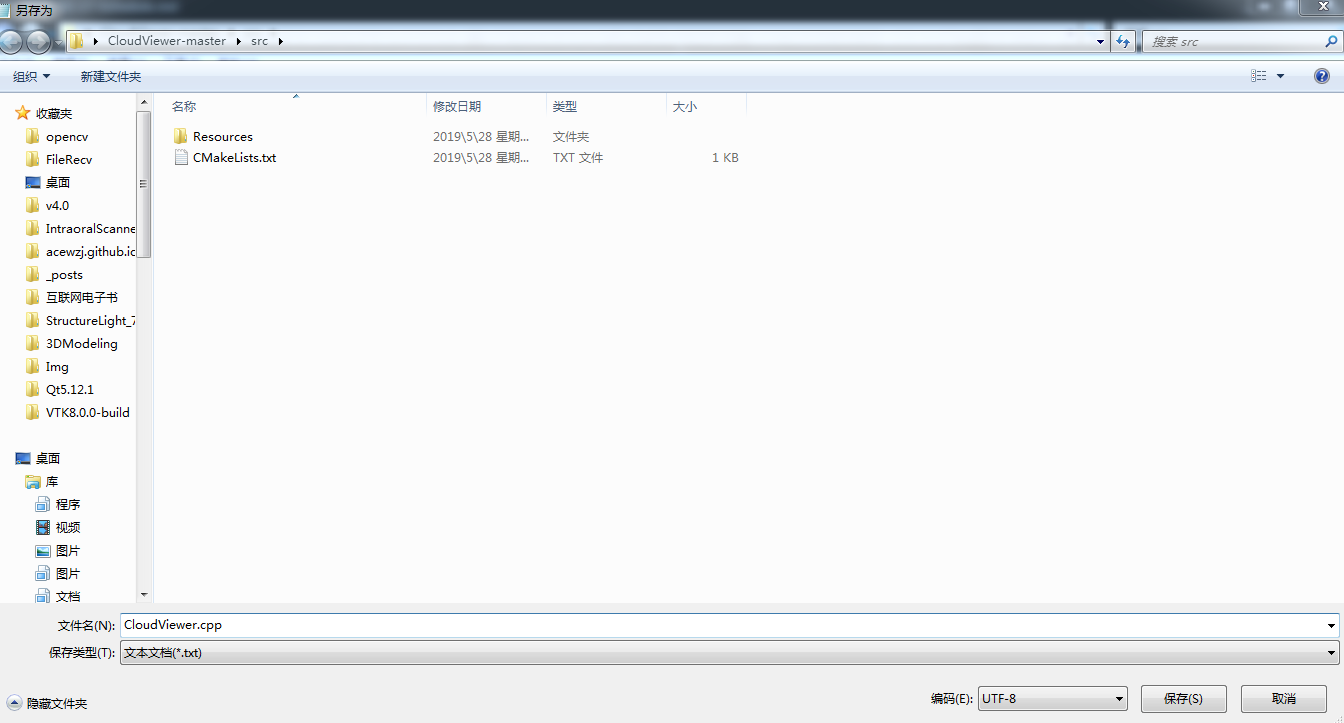
上图中源文件是UTF-8的格式。而我们打开一个正常不乱码的文件查看发现是ANSI格式。不同的国家和地区制定了不同的标准,由此产生了 GB2312、GBK、GB18030、Big5、Shift_JIS 等各自的编码标准。这些使用多个字节来代表一个字符的各种汉字延伸编码方式,称为 ANSI 编码。在简体中文Windows操作系统中,ANSI 编码代表 GB2312编码;在繁体中文Windows操作系统中,ANSI编码代表Big5;
UTF-8 最大的一个特点,就是它是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。
UTF-8 的编码规则很简单,只有二条:
1)对于单字节的符号,字节的第一位设为0,后面7位为这个符号的 Unicode 码。因此对于英语字母,UTF-8 编码和 ASCII 码是相同的。
2)对于n字节的符号(n > 1),第一个字节的前n位都设为1,第n + 1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的 Unicode 码。
下表总结了编码规则,字母x表示可用编码的位。
1 | Unicode符号范围 | UTF-8编码方式 |
跟据上表,解读 UTF-8 编码非常简单。如果一个字节的第一位是0,则这个字节单独就是一个字符;如果第一位是1,则连续有多少个1,就表示当前字符占用多少个字节。
我们下载了VS 中的御用插件 ForceUTF-8