- 2020秋招提前批
- C/C++相关开发
- 拿到腾讯、华为等offer
间隙锁
前面谈到行锁是针对一条记录进行加锁。当对一个范围内的记录加锁的时候,我们称之为间隙锁。
当使用范围条件索引数据时,InnoDB 会对符合条件的数据索引项加锁。对于键值在条件范围内但并不存在的记录,叫做“间隙(GAP)”,InnoDB 也会对这个“间隙”加锁,这就是间隙锁。间隙锁和行锁合称(Next-Key锁)。
如果表中只有 11 条记录,其 id 的值分别是 1,2,…,10,11 下面的 SQL:
Select * from table_gap where id > 10 for update;
这是一个范围条件的检索,InnoDB 不仅会对符合条件的 id 值为 10 的记录加锁,会对 id 大于 10 的“间隙”加锁,即使大于 10 的记录不存在,例如 12,13。
InnoDB 使用间隙锁的目的:
- 一方面是为了防止幻读。对于上例,如果不使用间隙锁,其他事务插入了 id 大于 10 的任何记录,本事务再次执行 select 语句,就会发生幻读。
- 另一方面,也是为了满足恢复和复制的需要。
d unique_guard
互斥锁保证了线程间的同步,但是却将并行操作变成了串行操作,这对性能有很大的影响,所以我们要尽可能的减小锁定的区域,也就是使用细粒度锁。
这一点lock_guard做的不好,不够灵活,lock_guard只能保证在析构的时候执行解锁操作,lock_guard本身并没有提供加锁和解锁的接口,但是有些时候会有这种需求。看下面的例子。
计算机网络
1.三次握手
2.第二次握手回复丢失会怎样
3.第三次握手丢失会怎样
4.介绍拥塞控制的慢启动过程
5.刚开始时拥塞窗口多大
6.慢启动什么时候结束,标志是啥?
7.慢启动的阈值如何确定的?
(第二次握手的时候协商的)这里没准备到
8.拥塞避免,阈值多大,怎么确定的。后续的阶段是怎样的?
9.poll和epoll区别
拥塞窗口 我写的
Cwnd = congestion window
Cwnd 为什么是指数增加?
开始的时候拥塞窗口是1,发一个数据包等ACK回来 cwnd++即2,这个时候可以发送两个包,发送间隔几乎没有, 对方回的ACK到达发送方几乎是同时到达的.一个RTT来回,cwnd就翻倍,cwnd++,cwnd++即4了.如此下去,cwnd是指数增加.
慢启动什么时候结束?
达到ssthresh后结束
ssthresh值如何设定?
这里查了一圈没找到是怎么设定的,面试官说是在第二次握手的时候协商确定的
一般来说
ssthresh的大小是65535字节。
3.10 晚7点 腾讯 视频面 约50min
1.自我介绍
2.进程线程
3.进程通信方式
4.软,硬链接
5.虚拟内存
6.swap (不知道)
7.僵尸进程(只听说过)
8.三次握手
9交换机路由器区别 工作方式
10.tcpudp区别
11.滑动窗口
12.https 加密过程(只知道大概)
13.链表插入时间复杂度
14.hashmap实现(这里语言没组织好,说的磕磕绊绊也没说完全)
15.avl树旋转调整原理,只需要分情况画图说明
16很多数,怎么取最小的前100个
8、查看访问前十个ip地址
1 | awk '{print $1}' |sort|uniq -c|sort -nr |head -10 access_log |
阿里
语言
什么是指针
什么是野指针和悬空指针
指针和引用的区别
传值和传指针的区别
C++ 11 新特性
inline 实现原理
知道哪些设计模式
C++ 类的初始化顺序
怎么实现 malloc 和 free 方法
define 和 const 的区别
构造函数可以申明为 virtual 的形式吗,如果声明会发生什么
深拷贝和浅拷贝
计算机网络
tcp 三次握手和四次挥手
ip 协议的作用
socket() 套接字有哪些
套接字有3种类型:流式套接字(SOCK_STREAM)、数据包套接字(SOCK_DGRAM)和原始套接字。流式套接字可以提供可靠的、面向连接的通信流。如果通过流式套接字发送了顺序的数据:1、2。那么数据到达远程时候的顺序也是1、2。流式套接字可用于Telnet远程连接、WWW服务等需要使数据顺序传递的应用,它使用TCP协议保证数据传输的可靠性。流式套接字的工作原理如图18.9所示,我们将网络中的两台主机分别作为服务器和客户机看待。
数据包套接字定义了一种无连接的服务,数据通过相互独立的报文进行传输,是无序的,并且不保证可靠性。数据包套接字使用者数据包协议UDP,数据只是简单地传送到对方。数据包套接字的工作原理如图18.10所示。
原始套接字允许对低层协议如IP或ICMP直接访问,主要用于新的网络协议实现的测试等。原始套接字主要用于一些协议的开发,可以进行比较底层的操作。它功能强大,但是没有上面介绍的两种套接字使用方便,一般的程序也涉及不到原始套接字。
http 和 https 的区别
select,poll,epoll的区别
tcp 和 udp 的区别
拥塞控制的算法
拥塞控制和流量控制的区别
高并发服务器客户端主动关闭连接和服务端主动关闭连接的区别
HTTP1.X 和 HTTP2.X 的区别
HTTP3 了解吗
数据结构
堆和栈有什么区别
vector 的扩容原理
resize() 和 reserve() 的区别
std::vector的reserve和resize的区别
\1. reserve: 分配空间,更改capacity但不改变size
\2. resize: 分配空间,更改capacity也改变size
map 的底层是怎么实现的
map 和 unordered_map的区别
unordered_map 支持并发读取吗,如果要实现一个支持并发读取的 unordered_map 得话要怎么实现
解决哈希冲突 的方法有哪些
什么是智能指针
什么是跳表
遍历二叉树的方式
map 容器如果 key 是类对象,对类有什么要求
vector 和 list 的区别
数据库
什么是索引
索引是关系数据库中对某一列或多个列的值进行预排序的数据结构。通过使用索引,可以让数据库系统不必扫描整个表,而是直接定位到符合条件的记录
Mysql 的 B+ 树是什么样的一个索引
B+ 树和 B 树有什么性能上的区别
数据库的并发安全是怎么做到的
事务的属性
事务的原子性怎么保证的
为了实现原子性,需要通过日志:
redo:redo log是指在回放日志的时候把已经COMMIT的事务重做一遍,对于没有commit的事务按照abort处理,不进行任何操作。
undo:undo log是把所有没有COMMIT的事务回滚到事务开始前的状态,系统崩溃时,可能有些事务还没有COMMIT,在系统恢复时,这些没有COMMIT的事务就需要借助undo log来进行回滚。
事务的提交过程
事务的隔离性怎么做到的
MVCC 是什么
数据库的隔离级别
1、数据库事务的属性-ACID(四个英文单词的首写字母):
1)原子性(Atomicity)
所谓原子性就是将一组操作作为一个操作单元,是原子操作,即要么全部执行,要么全部不执行。
2)一致性(Consistency)
事务的一致性指的是在一个事务执行之前和执行之后数据库都必须处于一致性状态。如果事务成功地完成,那么系统中所有变化将正确地应用,系统处于有效状态。如果在事务中出现错误,那么系统中的所有变化将自动地回滚,系统返回到原始状态。
3)隔离性(Isolation)
隔离性指并发的事务是相互隔离的。即一个事务内部的操作及正在操作的数据必须封锁起来,不被其它企图进行修改的事务看到。
4)持久性(Durability)
持久性是指一个事务一旦被提交,它对数据库中数据的改变就是永久性的,接下来的其他操作和数据库故障不应该对其有任何影响。即一旦一个事务提交,DBMS(Database Management System)保证它对数据库中数据的改变应该是永久性的,持久性通过数据库备份和恢复来保证。
2、在关系型数据库中,事务的隔离性分为四个隔离级别,在解读这四个级别前先介绍几个关于读数据的概念。
1)脏读(Dirty Reads):所谓脏读就是对脏数据(Drity Data)的读取,而脏数据所指的就是未提交的数据。也就是说,一个事务正在对一条记录做修改,在这个事务完成并提交之前,这条数据是处于待定状态的(可能提交也可能回滚),这时,第二个事务来读取这条没有提交的数据,并据此做进一步的处理,就会产生未提交的数据依赖关系。这种现象被称为脏读。
2)不可重复读(Non-Repeatable Reads):一个事务先后读取同一条记录,但两次读取的数据不同,我们称之为不可重复读。也就是说,这个事务在两次读取之间该数据被其它事务所修改。
3)幻读(Phantom Reads):一个事务按相同的查询条件重新读取以前检索过的数据,却发现其他事务插入了满足其查询条件的新数据,这种现象就称为幻读。
3、事务四个隔离级别对比:
1)未提交读(Read Uncommitted):SELECT语句以非锁定方式被执行,所以有可能读到脏数据,隔离级别最低。
2)提交读(Read Committed):只能读取到已经提交的数据。即解决了脏读,但未解决不可重复读。
3)可重复读(Repeated Read):在同一个事务内的查询都是事务开始时刻一致的,InnoDB的默认级别。在SQL标准中,该隔离级别消除了不可重复读,但是还存在幻读。
4)串行读(Serializable):完全的串行化读,所有SELECT语句都被隐式的转换成SELECT … LOCK IN SHARE MODE,即读取使用表级共享锁,读写相互都会阻塞。隔离级别最高。
什么是幻读
R级别 会不会有幻读
mysql 的查询过程
操作系统
多线程什么时候需要同步
什么是缺页异常,什么情况下会缺页异常
进程间的通信机制
什么是共享内存
什么是线程安全,实现线程安全的机制
内核态线程的原理
什么是同步和异步
cpu的流水线机制
缓存一致性协议
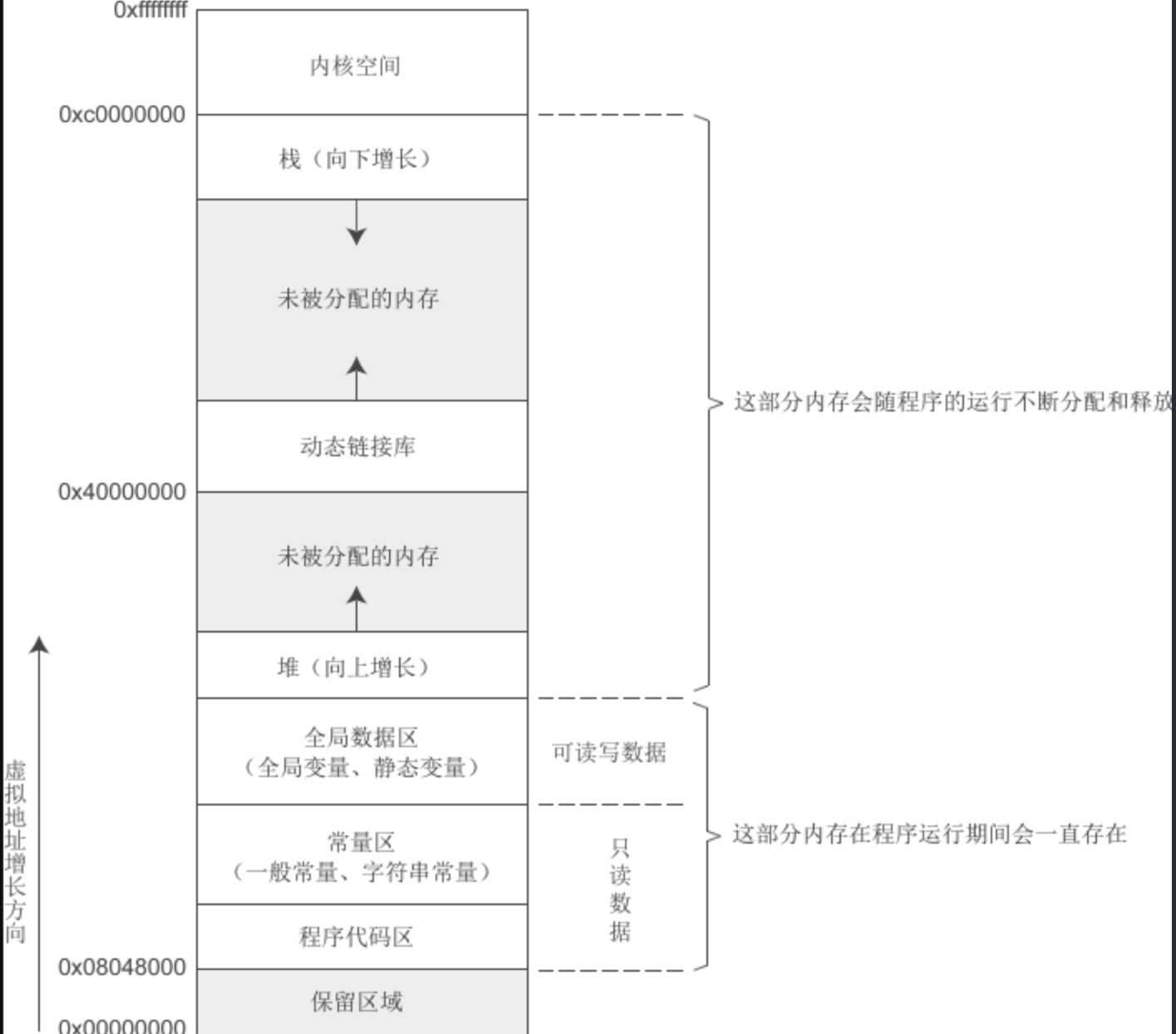
程序通过一个地址读取一个变量的过程
一个进程的地址空间分为几段
可执行文件的文件格式
编译和链接的过程
互斥锁和信号量的区别
自旋锁和乐观锁
怎么在用户空间实现一个定时器
进程优先级和cpu任务调度策略
死锁发生的必要条件
什么是内存泄漏,如何定位内存泄漏
除了 RAII 机制还有什么方法可以避免内存泄漏
多线程下载比单线程快的原因
什么是分布式
内存池的作用
用户态和内核态的理解
硬中断和软中断
算法
堆排序的实现原理
二叉树中所有距离为k的节点
前k个高频元素
前k个高频单词
n个有序小文件,合并成有序的一个文件
用数组实现队列
实现快速排序
最长公共子序列
实现一个strcpy函数,考虑内存覆盖(源串可以被修改,保证复制的目的子串正确),实现多个字节同时拷贝(4字节或者8字节)
环形链表 II
归并排序的实现原理
合并k个升序链表
完全二叉树的节点个数
访问所有节点的最短路径
作者:陈乐乐
链接:https://leetcode-cn.com/circle/discuss/GZPHPo/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
阿里块存储实习2021-02-19
着重问项目
mysql 如何创建聚簇索引?
create clusterindex
编译链接流程
装饰器 python
struct 内存对齐怎么一回事
从理论上来讲,我们可以从任一字节位置处开始读取,但是实际的计算机系统对基本类型数据在内存中存放的位置有限制,它们会要求这些数据的首地址的值是某个数k(通常它为4或8)的倍数,这就是所谓的内存对齐。
尽管内存是以字节为单位,但是大部分处理器并不是按字节块来存取内存的.它一般会以双字节,四字节,8字节,16字节甚至32字节为单位来存取内存,我们将上述这些存取单位称为内存存取粒度.
现在考虑4字节存取粒度的处理器取int类型变量(32位系统),该处理器只能从地址为4的倍数的内存开始读取数据。
假如没有内存对齐机制,数据可以任意存放,现在一个int变量存放在从地址1开始的联系四个字节地址中,该处理器去取数据时,要先从0地址开始读取第一个4字节块,剔除不想要的字节(0地址),然后从地址4开始读取下一个4字节块,同样剔除不要的数据(5,6,7地址),最后留下的两块数据合并放入寄存器.这需要做很多工作.
epoll 两种触发方式
Linux 服务器和一台数据库服务器失去连接如何排查?
索引的好处与坏处
加强数据结构和算法
合并两个有序链表
线程和进程的区别
一面加面02-26
首先介绍项目:嫌弃介绍的太浅,没讲清楚难点,自己做了什么,比其他人的产品相比没有数据量化说明精度提高了
我于是给他详细的介绍了项目所用的几种方案,他听不懂了
接着问数据库的LRU替换器,问它的一个大概的读命中和什么时候写盘的逻辑?
我们说读一个页面,是根据一个页面ID来进行读取的,调用的函数是FetchPageImpl,如果该页面存在就返回该页面在内存中的地址,并且将该页面pin(粘)住,也就是从LRU替换链上摘下来,因为有人在使用该页面了哇!如果该页面不存在就有空闲地方还好,没有空闲地方的话就得从LRU替换链上选取最后一个页面进行替换,然后从磁盘上读进来。
至于什么时候写盘?是在被LRU替换器替换出去的时候会刷盘。
接着开始问数据库的并发控制,这块被很多人问到了,但是这块的实验还没做明白,特此总结一下吧:
接着开始问STL中list的empty()和size()区别是什么?时间复杂度是什么?看过源码没有?
建议使用 empty() 成员方法。理由很简单,无论是哪种容器,只要其模板类中提供了 empty() 成员方法,使用此方法都可以保证在 O(1) 时间复杂度内完成对“容器是否为空”的判断;但对于 list 容器来说,使用 size() 成员方法判断“容器是否为空”,可能要消耗 O(n) 的时间复杂度。
注意,这个结论不仅适用于 vector、deque 和 list 容器,后续还会讲解更多容器的用法,该结论也依然适用。
那么,为什么 list 容器这么特殊呢?这和 list 模板类提供了独有的 splice() 成员方法有关。
做一个大胆的设想,假设我们自己就是 list 容器的设计者。从始至终,我们的目标都是让 list 成为标准容器,并被广泛使用,因此打造“高效率的 list”成为我们奋斗的目标。
在实现 list 容器的过程中我们发现,用户经常需要知道当前 list 容器中存有多少个元素,于是我们想让 size() 成员方法的执行效率达到 O(1)。为了实现这个目的,我们必须重新设计 list,使它总能以最快的效率知道自己含有多少个元素。
要想令 size() 的执行效率达到 O(1),最直接的实现方式是:在 list 模板类中设置一个专门用于统计存储元素数量的 size 变量,其位于所有成员方法的外部。与此同时,在每一个可用来为容器添加或删除元素的成员方法中,添加对 size 变量值的更新操作。由此,size() 成员方法只需返回 size 这个变量即可(时间复杂度为 O(1))。
不仅如此,由于 list 容器底层采用的是链式存储结构(也就是链表),该结构最大的特点就是,某一链表中存有元素的节点,无需经过拷贝就可以直接链接到其它链表中,且整个过程只需要消耗 O(1) 的时间复杂度。考虑到很多用户之所以选用 list 容器,就是看中了其底层存储结构的这一特性。因此,作为 list 容器设计者的我们,自然也想将 splice() 方法的时间复杂度设计为 O(1)。
这里就产生了一个矛盾,即如果将 size() 设计为 O(1) 时间复杂度,则由于 splice() 成员方法会修改 list 容器存储元素的个数,因此该方法中就需要添加更新 size 变量的代码(更新方式无疑是通过遍历链表来实现),这也就意味着 splice() 成员方法的执行效率将无法达到 O(1);反之,如果将 splice() 成员方法的执行效率提高到 O(1),则 size() 成员方法将无法实现 O(1) 的时间复杂度。
也就是说,list 容器中的 size() 和 splice() 总有一个要做出让步,即只能实现其中一个方法的执行效率达到 O(1)。
值得一提的是,不同版本的 STL 标准库,其底层解决此冲突的抉择是不同的。以本教程所用的 C++ STL 标准模板库为例,其选择将 splice() 成员方法的执行效率达到 O(1),而 size() 成员方法的执行效率为 O(n)。当然,有些版本的 STL 标准库中,选择将 size() 方法的执行效率设计为 O(1)。
但不论怎样,选用 empty() 判断容器是否为空,效率总是最高的。所以,如果程序中需要判断当前容器是否为空,应优先考虑使用 empty()。
然后开始考察结构体内存对齐,对于32位机器,char int short 占多少字节?64位机器呢?
这块需要深刻理解内存对齐做了什么?对于32位机器来说,它每一次读会读4个字节的数据,那你一个char才占1个字节,每次我想读它还得把剩下的3个字节剔除掉挺费劲的,不如就让它占4个字节,如果是两个char挨在一起呢?就可以把这两个char放在一起凑成4个字节,可不是让它每个人都是4个字节哈。
实际上,由于存储变量时地址对齐的要求,编译器在编译程序时会遵循两条原则:一、结构体变量中成员的偏移量必须是成员大小的整数倍(0被认为是任何数的整数倍) 二、结构体大小必须是所有成员大小的整数倍。
先让我们看四个重要的基本概念:
1.数据类型自身的对齐值:
对于char型数据,其自身对齐值为1,对于short型为2,对于int,float,double类型,其自身对齐值为4,单位字节。
2.结构体或者类的自身对齐值:其成员中自身对齐值最大的那个值。
3.指定对齐值:#pragma pack (value)时的指定对齐值value。
4.数据成员、结构体和类的有效对齐值:自身对齐值和指定对齐值中小的那个值。
这块我的分析是32位机器中int占4字节,char也会占4字节,short也会占4个字节,所以一共是12个字节。后来我又程序跑了一下确实是正确的;
64位机器我给的答案是24字节,结果就大错特错了。因为64位机器下int还是4个字节大小,所以按照最长对齐原则就还是12,但是如果改成 char double short 的话按照最长对齐原则会按double的8字节进行对齐,结果就是24了,后期程序验证也是正确的。
接着开始考察指针和引用
我最先答的是引用是一个变量的别名,它是一个常量指针 const * 右定向嘛!指向的东西一经初始化就修改不了了,我擦,这块好像答错了,左定值右定向指的其实是const在 * 的左右,我给弄反了,所以它应该是一个 * const 指针常量 指针是一个常量。本来这个口诀记的时候是根据const的规律记得,结果给忘了。不应该啊
第二个是引用不能为空,但是指针可以为空,且引用必须在声明的时候就初始化
接着开始考察线程池,这个也是被很多人问到的
我先说的是传统的手写线程池,就是pthread_create(&tid, attr, func, args).然后detach掉,这里detach是为了为了和主线程分离,为什么要分离?因为默认主线程是joinable,等待子线程运行完毕之后回收部分资源,如果子线程不完毕,主线程会阻塞在这里等子线程完毕。那么在网络线程池这里就存在问题了,因为主线程还要忙着接收客户端连接呢!所以把子线程设置为分离之后让子线程自己释放资源去吧!
然后就是生产者消费者模型往上套:有一个任务队列和一个条件变量,初始的时候由于任务队列没有东西,所以会阻塞在条件变量sem的wait上,一旦有生产者往里放东西了,任务队列就有任务了,条件变量就会唤醒阻塞在上面的线程,为了避免虚假唤醒,这里会注意一下队列是否为空。还要注意线程往任务队列里写的时候记得要加互斥锁。
有一个面试官会问如果任务队列满了以后,生产者会怎么做呢?
我看了一下代码如果任务队列满了以后会返回false,就是不往里放了;面试官不太满意
对于一般的生产快于消费的情况。当队列已满时,我们并不希望有任何任务被忽略或得不到执行,此时生产者可以等待片刻再提交任务,更好的做法是,把生产者阻塞在提交任务的方法上,待队列未满时继续提交任务,这样就没有浪费的空转时间了。
1 |
|
1 |
|
最后就是三次握手四次挥手,见我答得太6所以就刁难我三次握手之后进入什么状态,eatablished
客户端第一个FIN发完进入FIN_Wait1状态,收到服务端第一个ack之后进入FIN_wait2状态,收到FIN之后进入time_wait状态
服务端第一个FIN发完进入LAST_ACK状态
这两个我全没在意,结果他就直接让我做题,结果做题时写的较慢,很遗憾收到了面试官的鄙视
最后他让我好好总结项目,量化数据,基础知识要理解透,刷题要快且写出来没有异常。估计大概率是凉凉了。
阿里云弹性云计算2021-02-10
判断二叉搜索树
二面是主管面
阿里oceanbase数据库
直接发了两道题,一道是括号最长匹配,一道是动态规划
动态规划我写不出来,他让我用暴力写
1 | // 总体要求 |
0221 已投简历lixia.yqlixia.yq@antfin.com
阿里钉钉
0222 投简历
阿里后台珀熙推荐02-22
0222 直接微信发给简历
0226 晚上9点半开始面试,一上来就是智能指针
接着就问stl的vector扩容原理
vector有一个capacity值,插入值后发现超过这个值之后就得开辟新的大的存储区域,并且将原来的元素拷贝过去,再将原来的元素删除
对比可以发现采用采用成倍方式扩容,可以保证常数的时间复杂度,而增加指定大小的容量只能达到O(n)的时间复杂度,因此,使用成倍的方式扩容。
采用1.5的好处是经过几次扩容之后可以重用之前的存储空间

字节
语言
const 关键字的使用场景
static 关键字的使用场景
explict 关键字的使用场景
volatile 关键字的使用场景
什么是多态
虚函数的实现原理
构造函数可以是虚函数吗
析构函数可以是虚函数吗,应用场景
智能指针有哪些,实现原理以及用法
什么是模板特化
new 和 malloc 区别
C++ 内存空间布局
如何限制对象只能在堆上创建
如何限制对象只能在栈上创建
如何让类不能被继承
什么是单例模式,工厂模式
C++ auto 类型推导的原理
泛型编程如何实现的
指针和引用的区别
计算机网络
三次握手和四次挥手
TIME_CLOSE 和 TIME_WAIT 的状态和意义
TCP 如何保证可靠传输
流量控制和拥塞控制
CRC 循环校验的算法
如何使用 UDP 实现可靠传输
为什么不能是两次握手
SYN FLOOD 是什么
HTTPs 和 HTTP 的区别
HTTPS 的原理,客户端为什么信任第三方证书
HTTP 方法了解哪些
HTTP 异常状态码知道哪些
HTTP 长连接短连接使用场景是什么
Arp 攻击
NAT 原理
DNS 服务器与提供内容的服务器的区别
怎么实现 DNS 劫持
对称加密和非对称的区别,非对称加密有哪些
AES 的过程
安全攻击有哪些
DDOS 有哪些,如何防范
数据结构
vector 底层实现
如何控制 vector 的内存分配
map, hashmap 底层实现
map 的 key 如果是结构体需要注意什么问题
注意重载一下 小于大于 符号
hash冲突如何解决
数据库
mysql 索引
B 和 B+ 区别
Redis 的数据结构
Redis持久化
AOF 重写
一致性 Hash
Redis 集群哈希槽
Redis 集群高可用
Redis KEY 过期策略
数据库注入的过程,如何防范
操作系统
进程和线程的区别
进程间的通讯方式
进程切换的上下文细节
进程切换要保存CPU上下文,切换内核栈、切换虚拟地址空间
线程切换没有虚拟地址空间的切换
线程切换的上下文细节
CPU 的最小调度单位
多线程同步、多进程通信方式
操作系统的栈和堆的区别
用户态和内核态的区别
用户态和内核态切换的代价
从用户态切换到内核态,需要通过系统调用的方式。该过程也是有CPU上下文切换的:切换时,先保存CPU寄存器中用户态的指令位置,再重新更新为内核指令的位置。当系统调用结束时,CPU寄存器恢复到原来保存的用户态。一次系统调用,发生了两次CPU上下文切换。
进程切换主要损耗:
- 指的是CPU寄存器需要保存和加载(单纯切换寄存器影响倒不是特别大)
- TLB(TLB是一种高速缓存,内存管理硬件使用它来改善虚拟地址到物理地址的转换速度)实例需要重新加载-这个对性能影响非常大不说,整个进程的执行都会停止
- CPU 的pipeline需要刷掉(cpu 汇编代码优化-汇编代码转换成机器指令由硬件直接实现这一步速度是很快的)
- 调度器进行线程调度
fork 的过程
内存置换算法
什么是虚拟内存,作用
Select,poll,epoll的区别
epoll 的 LT 和 ET 的区别
什么情况下会发生缺页中断,具体流程
如何判断逻辑地址是否已经映射在物理地址上了
页表所在的位置
环形缓冲区的好处
动态链接和静态链接
怎么查看端口号占用情况
算法
反转链表
多线程交替打印
实现单例模式
最小栈
给定几十万个ip集合,判断任意一个ip是否属于这个集合
给定一个字符串,判断该字符串是否是环等的(字符串首位相连,如果能找到一个位置,从这个位置顺时针得到的字符串和逆时针得到的字符串相等,即为环等)
合并两个排序链表
快排和归并的复杂度分析
排序链表
二叉树中和为某一值的路径
有事洗牌
打家劫舍II
LFU 缓存
乘积最大子数组
车队
用 Rand7() 实现 Rand10()
如何做到均匀的生成随机数
class Solution extends SolBase {
public int rand10() {
while(true) {
int num = (rand7() - 1) * 7 + rand7(); // 等概率生成[1,49]范围的随机数
if(num <= 40) return num % 10 + 1; // 拒绝采样,并返回[1,10]范围的随机数
}
}
}已知 rand_N() 可以等概率的生成[1, N]范围的随机数
那么:
(rand_X() - 1) × Y + rand_Y() ==> 可以等概率的生成[1, X * Y]范围的随机数
即实现了 rand_XY()作者:kkbill
链接:https://leetcode-cn.com/problems/implement-rand10-using-rand7/solution/cong-zui-ji-chu-de-jiang-qi-ru-he-zuo-dao-jun-yun-/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
大整数加法
三数之和
k个不同整数的子数组
快速查找 IP
最小的k个数
二叉搜索树的第k大节点
数组中的重复数字
XML 格式解析
有序数组找到第一个小于0的数和第一个大于0的数
实现一个 string 类
实现一个智能指针
两个排序数组找中位数
无重复字符的最长字串
string 转 float
其他
rebase 和 merge 用法(git)
为了 B 站视频加载更快,可以怎么做
作者:陈乐乐
链接:https://leetcode-cn.com/circle/discuss/mSAtnq/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
2021-03-12腾讯IEG一面
函数内 char* str = “abcd”;和 char str[] = {‘a’, ‘b’, ‘c’, ‘d’}有啥区别?
第一个是存放在常量区的,第二个是存放在栈上的;我回答的时候说的是存放在全局变量区的,然后第一个后面会有一个’\0’;
首先再复习一下C语言运行布局,底下是只读的代码区和常量区,其次才是可读写的全局数据区,所以我答错了,至于最后有没有截止符呢?
后来我又去VS中测试了一下啊;
2
3
4
所以需要改成 const char* str;所以存放在常量区的内容不能随便进行修改啊
str[5] = '\0'
我说的是正确的啦
解释static、const、mutable、volatile关键字
static 修饰全局变量、函数:防止命名冲突,全局变量区,作用域在本文件内
局部变量:全局变量区,
static 修饰类成员:全局变量区,类的所有对象共享
修饰类的成员函数:为类的全部对象服务。
mutable:
事实上,
mutable是用来修饰一个const示例的部分可变的数据成员的。如果要说得更清晰一点,就是说mutable的出现,将 C++ 中的const的概念分成了两种。
- 二进制层面的
const,也就是「绝对的」常量,在任何情况下都不可修改(除非用const_cast)。- 引入
mutable之后,C++ 可以有逻辑层面的const,也就是对一个常量实例来说,从外部观察,它是常量而不可修改;但是内部可以有非常量的状态。当然,所谓的「逻辑
const」,在 C++ 标准中并没有这一称呼。这只是为了方便理解,而创造出来的名词。显而易见,
mutable只能用来修饰类的数据成员;而被mutable修饰的数据成员,可以在const成员函数中修改。这里举一个例子,展现这类情形。
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
public:
//...
std::string lookup(const std::string& key) const
{
if (key == last_key_) {
return last_value_;
}
std::string value{this->lookupInternal(key)};
last_key_ = key;
last_value_ = value;
return value;
}
private:
mutable std::string last_key_
mutable std::string last_value_;
};这里,我们呈现了一个哈希表的部分实现。显然,对哈希表的查询操作,在逻辑上不应该修改哈希表本身。因此,
HashTable::lookup是一个const成员函数。在HashTable::lookup中,我们使用了last_key_和last_value_实现了一个简单的「缓存」逻辑。当传入的key与前次查询的last_key_一致时,直接返回last_value_;否则,则返回实际查询得到的value并更新last_key_和last_value_。volatile:
我说的有点模棱两可,中间又混杂进寄存器的概念,他反问我一个CPU核有一套寄存器还是共享一套寄存器
每个核都有自己独立的一套寄存器,每个线程运行在一个核上,只能操作当前核的寄存器,核之间相对独立,经过逻辑封装过后对开发者不可见。
这个关键字其实是想去掉编译器的优化,让CPU每次都去内存中去取,而不是偷懒每次去从cache、寄存器里去取,这样的话在多线程环境中可以做到及时的更新值。
time_wait
接下来是面试中最关键的部分了:网络
四次握手中,不能说客户端和服务端,而是要说主动关闭方和被动关闭方;接着就是time_wait状态了
1、防止最后主动关闭方的ACK报文在传输中丢了,服务端没收到ACK会超时重传FIN,结果客户端给人家关了,会给服务器返回一个RST报文,服务器接收到RST报文,
面试官觉得发RST没啥毛病啊?收到RST服务端退出不就完了吗?我一时语塞
2、防止客户端立即重用刚刚的地址端口号发送数据,和某个还没到达服务端的残余报文一起被发给服务端产生错误。
面试官觉得发就发了呗,都是发给同一个服务器,还反问我这样的话是两个客户端连一个服务器还是一个客户端连两个服务器,我又愣住了,这种模棱两可的问题我立即就答错了。实际上是一个客户端连两个服务器。
#define do {} while(0);
如果你是C++程序员,我有理由相信你用过,或者接触过,至少听说过MFC, 在MFC的afx.h文件里面, 你会发现很多宏定义都是用了do…while(0)或do…while(false), 比如说:
#define AFXASSUME(cond) do { bool __afx_condVal=!!(cond); ASSERT(__afx_condVal); __analysis_assume(__afx_condVal); } while(0)
粗看我们就会觉得很奇怪,既然循环里面只执行了一次,我要这个看似多余的do…while(0)有什么意义呢?
当然有!
为了看起来更清晰,这里用一个简单点的宏来演示:
#define SAFE_DELETE(p) do{ delete p; p = NULL} while(0)
假设这里去掉do…while(0),
#define SAFE_DELETE(p) delete p; p = NULL;
那么以下代码:
if(NULL != p) SAFE_DELETE(p)
else …do sth…
就有两个问题,
- 因为if分支后有两个语句,else分支没有对应的if,编译失败
- 假设没有else, SAFE_DELETE中的第二个语句无论if测试是否通过,会永远执行。
你可能发现,为了避免这两个问题,我不一定要用这个令人费解的do…while, 我直接用{}括起来就可以了
#define SAFE_DELETE(p) { delete p; p = NULL;}
的确,这样的话上面的问题是不存在了,但是我想对于C++程序员来讲,在每个语句后面加分号是一种约定俗成的习惯,这样的话,以下代码:
if(NULL != p) SAFE_DELETE(p);
else …do sth…
其else分支就无法通过编译了(原因同上),所以采用do…while(0)是做好的选择了。也许你会说,我们代码的习惯是在每个判断后面加上{}, 就不会有这种问题了,也就不需要do…while了,如:
if(…)
{
}
else
{
}
诚然,这是一个好的,应该提倡的编程习惯,但一般这样的宏都是作为library的一部分出现的,而对于一个library的作者,他所要做的就是让其库具有通用性,强壮性,因此他不能有任何对库的使用者的假设,如其编码规范,技术水平等。
智能指针
多线程
socket
说一下select poll epoll 的区别
read
8、top k
9、在默认情况下,当调用close关闭socke的使用,close会立即返回,但是,如果send buffer中还有数据,系统会试着先把send buffer中的数据发送出去,然后close才返回.
SO_LINGER选项则是用来修改这种默认操作的.于SO_LINGER相关联的一个结构体如下:
1 | struct linger { |

一般来说,一个端口释放后会等待两分钟之后才能再被使用,SO_REUSEADDR是让端口释放后立即就可以被再次使用。
Q:编写 TCP/SOCK_STREAM 服务程序时,SO_REUSEADDR到底什么意思?
A:这个套接字选项通知内核,如果端口忙,但TCP状态位于 TIME_WAIT ,可以重用端口。如果端口忙,而TCP状态位于其他状态,重用端口时依旧得到一个错误信息,指明”地址已经使用中”。如果你的服务程序停止后想立即重启,而新套接字依旧使用同一端口,此时SO_REUSEADDR 选项非常有用。必须意识到,此时任何非期望数据到达,都可能导致服务程序反应混乱,不过这只是一种可能,事实上很不可能。
一个套接字由相关五元组构成,协议、本地地址、本地端口、远程地址、远程端口。SO_REUSEADDR 仅仅表示可以重用本地本地地址、本地端口,整个相关五元组还是唯一确定的。所以,重启后的服务程序有可能收到非期望数据。必须慎重使用SO_REUSEADDR 选项。
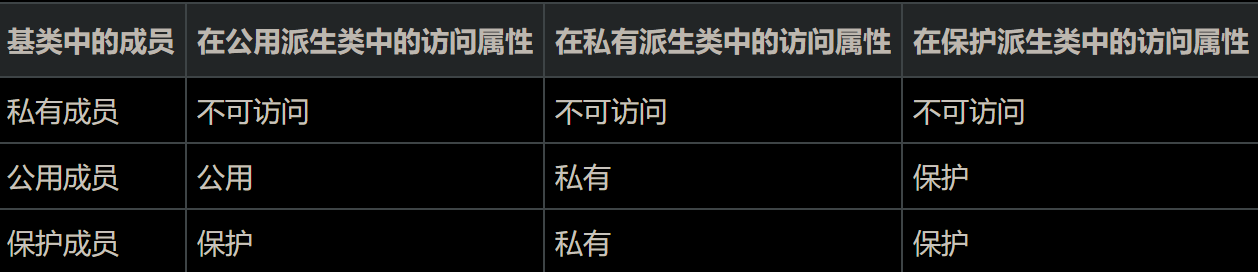
为什么继承之后子类会有父类的成员,但是却不可以访问?
因为那是父类的私有成员,构造的时候是先构造父类,然后再构造子类。
C++的保护有啥用?
保护基类的所有成员在派生类中都被保护起来,类外不能访问,其公用成员和保护成员可以被其派生类的成员函数访问。
C++友元有啥用?
借助友元(friend),可以使得其他类中的成员函数以及全局范围内的函数访问当前类的 private 成员。
友元函数
在当前类以外定义的、不属于当前类的函数也可以在类中声明,但要在前面加 friend 关键字,这样就构成了友元函数。友元函数可以是不属于任何类的非成员函数,也可以是其他类的成员函数。
友元函数可以访问当前类中的所有成员,包括 public、protected、private 属性的。
C++的类的构造顺序?
怎么利用虚函数表找到虚函数的地址?
- 首先在编译时虚函数表就已经生成了:先拷贝一份父类的虚函数表,如果子类重写了虚函数就覆盖掉父类的。至于怎么根据虚函数名找到虚函数地址,应该是有一个映射表的。
虚继承是怎么一回事?太麻烦了这个问题。
手撕代码
快速排序
计算机网络
\1. TCP是什么?可靠连接怎么体现?接收端没收到报文时发送端如何重传?TCP建立连接的过程?
\2. UDP是什么?与TCP的区别?适用场景?
操作系统
\1. 进程间通信、进程调度、进程和线程的区别
\2. 内存空间 堆空间、栈空间
数据库
\1. 索引
\2. 事务
设计模式
说出几种设计模式 随便选一种介绍 单例模式如果有两个线程都创建单例对象怎么做
进程间通信的方式通常分为管道、系统 IPC、套接字三种,其中管道有无名管道、命名管道,系统 IPC 有消息队列、信号、共享内存
无名管道的本质是在内核缓冲区的环形队列,每次读取数据后缓冲区都会移动,并且无名管道只能在有亲缘关系的进程间使用
命名管道则以文件的形式存在,由于有一个路径名,使用没有亲缘关系的进程间也可以使用命名管道
消息队列是存放在内核中的消息链表,具有特定的格式,支持多种数据类型,且允许多个进程进行读写
信号是软件层次上对中断机制的一种模拟,是一种异步通信方式,并且信号可以在用户空间进程和内核之间直接交互
共享内存顾名思义就是两个进行对同一块内存进行读写,是最快的 IPC 形式,但不适合大量的数据传输
Socket 是对 TCP/IP 协议族的封装,不仅可以用于本机上的进程间通信,更多的被用于网络通信中
生成子类的虚函数表需要经过一下步骤
将父类的虚函数表拷贝
将子类中重写的虚函数覆盖掉父类中的虚函数
如果有新增加的虚函数则放到表的最后
Linux 的 IO 多路复用机制中有 select、poll、epoll 三种,
select 和 poll 的时间复杂度都是 O(n),因为他们都是在对IO列表进行轮询,不同点在于 select 能监视的文件描述符有上限,一般为 1024,当然这个是在 Linux 内核中进行的宏定义,是可以修改的,而 poll 是基于链表来存储的,所以没有这个上限。
而 epoll 是基于事件驱动的,所以不需要轮询,epoll 会把事件和每一个IO流对应起来。并且 epoll 是通过一块共享内存来实现内核空间和用户空间的通信的,比起 select 和 poll 的大量数据拷贝效率更高。
不过 lect 的优点在于兼容不同的操作系统,而 poll 和 epoll 都只能在 linux 上使用。作者:weak chicken
链接:https://leetcode-cn.com/circle/discuss/zIxrWn/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
构造函数的调用顺序是,在构造子类对象时,要先调用父类的构造函数,此时编译器只“看到了”父类,并不知道后面是否后还有继承者,它初始化父类对象的虚表指针,该虚表指针指向父类的虚表。当执行子类的构造函数时,子类对象的虚表指针被初始化,指向自身的虚表。
虚继承与虚基类
虚继承:在继承定义中包含了virtual关键字的继承关系;
虚基类:在虚继承体系中的通过virtual继承而来的基类;需要注意的是:
class CSubClass : public virtual CBase {};其中CBase称之为CSubClass 的虚基类,而不是CBase就是个虚基类,因为CBase还可以不不是虚继承体系 中的基类。
虚继承是为了解决菱形继承带来的二义性问题
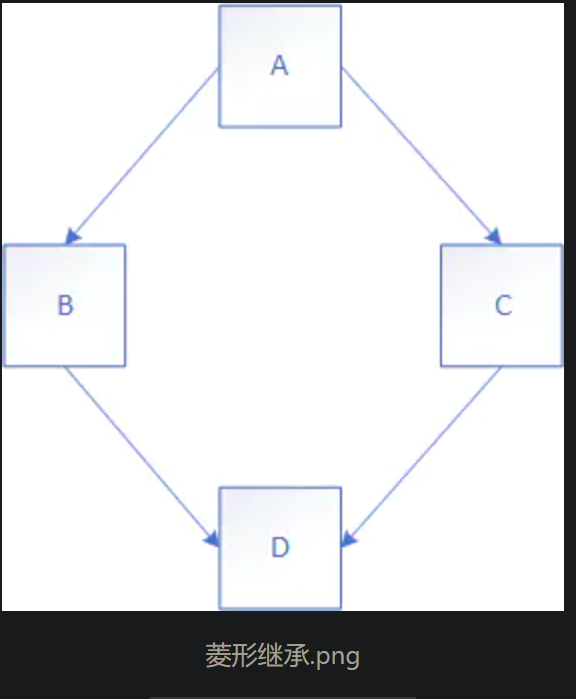
类 A 派生出类 B 和类 C,类 D 继承自类 B 和类 C,这个时候类 A 中的成员变量和成员函数继承到类 D 中变成了两份,一份来自 A–>B–>D 这条路径,另一份来自 A–>C–>D 这条路径。
在一个派生类中保留间接基类的多份同名成员,虽然可以在不同的成员变量中分别存放不同的数据,但大多数情况下这是多余的:因为保留多份成员变量不仅占用较多的存储空间,还容易产生命名冲突。假如类 A 有一个成员变量 a,那么在类 D 中直接访问 a 就会产生歧义,编译器不知道它究竟来自 A –>B–>D 这条路径,还是来自 A–>C–>D 这条路径。
虚继承的目的是让某个类做出声明,承诺愿意共享它的基类。其中,这个被共享的基类就称为虚基类(Virtual Base Class),本例中的 A 就是一个虚基类。在这种机制下,不论虚基类在继承体系中出现了多少次,在派生类中都只包含一份虚基类的成员。
实际上为了实现虚继承引入了类似虚函数表指针的vbptr,vbptr 指的是虚基类表指针(virtual base table pointer),该指针指向了一个虚基类表(virtual table),虚表中记录了虚基类与本类的偏移地址;通过偏移地址,这样就找到了虚基类成员,而虚继承也不用像普通多继承那样维持着公共基类(虚基类)的两份同样的拷贝,节省了存储空间。
问:类的内存布局是什么样的?考虑有虚函数、多继承、虚继承几种情况。(提问概率:★★★★★)
https://blog.csdn.net/lixungogogo/article/details/51123182
简单总结一下就是类只有成员变量占用内存(静态成员不占类内部内存,函数不占内存)。如果有虚函数,每个类对象都会有一个虚函数指针Vptr(占用一个指针大小的内存),vptr指向一个虚函数表,表里面记录了各项标记virtual的函数,子类如果覆盖父类虚函数,对应虚表位置的虚函数会被子类的替换。如果是虚继承,还会有虚基类表记录当前对象相对虚基类的偏移,以及一个虚基类指针指向这个虚基类表。
虚表在编译完成时大小与布局就被决定了,加载时其内存位置也就被确定了。
虚函数指针和构造函数体那个先被构造?
无继承时:
1、分配内存
2、初始化列表之前赋值虚表指针
3、列表初始化
4、执行构造函数体
有继承时:
1、分配内存
2、基类构造过程(按照无继承来)
3、初始化子类虚表指针
4、子类列表初始化
5、执行子类构造函数体
因此,将虚表指针的赋值过程应该放置在初始化列表之前,这是为了防止在初始化列表出现调用虚函数的情况!!!
在普通的函数当中调用虚函数和在构造函数当中调用虚函数有什么区别?
\2. c++语言了解多少?
\3. c++语言的多态你是怎么理解的?设计意义??
\4. 总结概括一下多态是在做什么??(大佬高屋建瓴的给我总结了一番)
\5. STL用的多不多,STL源码剖析看过没有?
\6. STL function有个特点,他的接口都是iterator,但是在用的时候传入容器的iterator或者说传入数据的指针都可以work这个背后的机理是什么?
\7. 同一份代码传递不同的东西但是都可以work,原因是什么?
\8. 模板当中对类型操作的思考。。
\9. 现在假设有一个程序,编译好的,编译没有错误,但是运行的时候报错,报的错是你正在调用一个纯虚函数,请问这里面导致这个错误的原因可能是什么?
\10. 根据c++内部原理推理这个问题
\11. 子类在调用构造函数的时候 父类的构造过程
\12. 描述一下,子类构造的时候,整个构造的过程,先怎么样,再怎么样,说清楚
\13. 是先构造父类的虚表指针还是先构造父类的成员?
\14. 虚表指针是什么时候设进去的? 虚表指针是由构造函数初始化的
\15. 在构造函数当中一部分是初始化列表一部分是在花括弧里面,你能说一下这些的顺序是什么么?差别是什么 和this指针的顺序
类成员是按照它们在类里被声明的顺序进行初始化的,和它们在成员初始化列表中列出的顺序没一点关系。
this本来就不存在实际对象内存中,所有对象都要先分配内存才能构造、初始化,而内存分配后this的值其实就已经能够确定了,而不是“对象构造完毕”才“生成”。
1 | class C : public B { |
- 在<参数列表>中,对象还没有开始构造
- 在<初始化列表>开始执行前,对象地址已经确定,对象还没有开始构造
- 在<初始化列表>中,对象进行构造(初始化基类B和数据成员member_)
- 在<构造函数体>开始执行前,对象已经构造完毕
所以,
- (在<参数列表>中,不可能使用this,不过这个与本题无关)
- 在<初始化列表>中,可以使用this获取对象地址,但尽量不要调用this的成员函数或访问this的数据成员。
- 在<构造函数体>中,既可以使用this获取对象地址,又可以调用this的成员函数或访问数据成员。
- 需要注意的一点是,在<构造函数体>中调用this的虚函数,会使用当前类C的实现(或基类B的实现,如果C没有重载它的话),不会使用派生类D的实现。原因很简单,因为C的构造函数执行时,D还没有构造完毕。
作者:鸡贼轩主
链接:https://www.zhihu.com/question/279734963/answer/411687739
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
\16. 初始化列表的写法和顺序有没有什么关系?
\18. IO多路复用那部分你是怎么去抽象这个事情的?怎么去实现业务逻辑和核心逻辑的区分是怎么去组织这个代码?
\19. 怎么保证你epoll的代码可以尽量的被复用呢?
1.虚函数表是全局共享的元素,即全局仅有一个.
2.虚函数表类似一个数组,类对象中存储vptr指针,指向虚函数表.即虚函数表不是函数,不是程序代码,不肯能存储在代码段.
3.虚函数表存储虚函数的地址,即虚函数表的元素是指向类成员函数的指针,而类中虚函数的个数在编译时期可以确定,即虚函数表的大小可以确定,即大小是在编译时期确定的,不必动态分配内存空间存储虚函数表,所以不再堆中.
socket close()和shutdown()区别
shutdown是一种优雅地单方向或者双方向关闭socket的方法。 而close则立即双方向强制关闭socket并释放相关资源。
如果有多个进程共享一个socket,shutdown影响所有进程,而close只影响本进程。
数据库范式
1、一范式:保证属性的原子性,不可再分;
2、二范式:保证主键的唯一性,2NF是对记录的**唯一性**,要求记录有唯一标识,即实体的唯一性,即不存在部分依赖;
表:学号、课程号、姓名、学分;
这个表明显说明了两个事务:学生信息, 课程信息;由于非主键字段必须依赖主键,这里学分依赖课程号,姓名依赖与学号,所以不符合二范式。
3、3NF是对字段的**冗余性**,要求任何字段不能由其他字段派生出来,它要求字段没有冗余,即不存在传递依赖;
表: 学号, 姓名, 年龄, 学院名称, 学院电话
因为存在依赖传递: (学号) → (学生)→(所在学院) → (学院电话) 。
腾讯
语言
C 和 C++ 的特点与区别
C++ 的多态是如何实现的
C++ 的虚函数是如何实现的
C++ 的内存管理
C++ 11 有哪些新特性
可变参数模板的作用
malloc 的原理
智能指针有哪几种
如何解决智能指针循环依赖的问题
STL 中 Vector,List 和 Map 的底层原理
inline 的作用
struct 和 union 的区别
static 关键字的用法
C++ 中如何避免拷贝
指针和引用的区别
如何让 .h 文件不被重复引用
怎么防止内存泄漏
new 的作用
delete 和 delete[] 的区别
网络
三次握手和四次挥手的流程
为什么要三次握手,两次握手可以吗
https 的建立连接过程
状态码 301 和 302 的区别
select,epoll,和 poll 的区别
ET 和 LT 的区别
OSI 和 TCP/IP 协议之间的对应关系
ARP 协议的原理和过程
滑动窗口协议的原理和过程
流量控制和拥塞控制的区别
TIME_WAIT 的作用
TCP 和 UDP 的区别
TCP 如何保证可靠性
SYN Flood 攻击
如何使用 udp 实现可靠性
数据库
redis 的主从复制怎么做的
redis 支持的数据类型
什么是 redis 持久化
redis 有哪几种持久化方式,优缺点是什么
redis 有哪些架构模式
MySQL 中 myisam 与 innodb 的区别
MyISAM与InnoDB的区别是什么?
1、 存储结构
MyISAM:每个MyISAM在磁盘上存储成三个文件。第一个文件的名字以表的名字开始,扩展名指出文件类型。.frm文件存储表定义。数据文件的扩展名为.MYD (MYData)。索引文件的扩展名是.MYI (MYIndex)。
InnoDB:所有的表都保存在同一个数据文件中(也可能是多个文件,或者是独立的表空间文件),InnoDB表的大小只受限于操作系统文件的大小,一般为2GB。2、 存储空间
MyISAM:可被压缩,存储空间较小。支持三种不同的存储格式:静态表(默认,但是注意数据末尾不能有空格,会被去掉)、动态表、压缩表。
InnoDB:需要更多的内存和存储,它会在主内存中建立其专用的缓冲池用于高速缓冲数据和索引。3、 可移植性、备份及恢复
MyISAM:数据是以文件的形式存储,所以在跨平台的数据转移中会很方便。在备份和恢复时可单独针对某个表进行操作。
InnoDB:免费的方案可以是拷贝数据文件、备份 binlog,或者用 mysqldump,在数据量达到几十G的时候就相对痛苦了。4、 事务支持
MyISAM:强调的是性能,每次查询具有原子性,其执行数度比InnoDB类型更快,但是不提供事务支持。
InnoDB:提供事务支持事务,外部键等高级数据库功能。 具有事务(commit)、回滚(rollback)和崩溃修复能力(crash recovery capabilities)的事务安全(transaction-safe (ACID compliant))型表。5、 AUTO_INCREMENT
MyISAM:可以和其他字段一起建立联合索引。引擎的自动增长列必须是索引,如果是组合索引,自动增长可以不是第一列,他可以根据前面几列进行排序后递增。
InnoDB:InnoDB中必须包含只有该字段的索引。引擎的自动增长列必须是索引,如果是组合索引也必须是组合索引的第一列。6、 表锁差异
MyISAM:只支持表级锁,用户在操作myisam表时,select,update,delete,insert语句都会给表自动加锁,如果加锁以后的表满足insert并发的情况下,可以在表的尾部插入新的数据。
InnoDB:支持事务和行级锁,是innodb的最大特色。行锁大幅度提高了多用户并发操作的新能。但是InnoDB的行锁,只是在WHERE的主键是有效的,非主键的WHERE都会锁全表的。7、 全文索引
MyISAM:支持 FULLTEXT类型的全文索引
InnoDB:不支持FULLTEXT类型的全文索引,但是innodb可以使用sphinx插件支持全文索引,并且效果更好。8、 表主键
MyISAM:允许没有任何索引和主键的表存在,索引都是保存行的地址。
InnoDB:如果没有设定主键或者非空唯一索引,**就会自动生成一个6字节的主键(用户不可见)**,数据是主索引的一部分,附加索引保存的是主索引的值的数据列。9、 表的具体行数
MyISAM:保存有表的总行数,如果select count() from table;会直接取出出该值。
InnoDB:没有保存表的总行数,如果使用select count() from table;就会遍历整个表,消耗相当大,但是在加了wehre条件后,myisam和innodb处理的方式都一样。10、 CURD操作
MyISAM:如果执行大量的SELECT,MyISAM是更好的选择。
InnoDB:如果你的数据执行大量的INSERT或UPDATE,出于性能方面的考虑,应该使用InnoDB表。DELETE 从性能上InnoDB更优,但DELETE FROM table时,InnoDB不会重新建立表,而是一行一行的删除,在innodb上如果要清空保存有大量数据的表,最好使用truncate table这个命令。11、 外键
MyISAM:不支持
InnoDB:支持
通过上述的分析,基本上可以考虑使用InnoDB来替代MyISAM引擎了,原因是InnoDB自身很多良好的特点,比如事务支持、存储 过程、视图、行级锁定等等,在并发很多的情况下,相信InnoDB的表现肯定要比MyISAM强很多。另外,任何一种表都不是万能的,只用恰当的针对业务类型来选择合适的表类型,才能最大的发挥MySQL的性能优势。如果不是很复杂的Web应用,非关键应用,还是可以继续考虑MyISAM的,这个具体情况可以自己斟酌。存储引擎选择的基本原则
采用MyISAM引擎
- R/W > 100:1 且update相对较少
- 并发不高
- 表数据量小
- 硬件资源有限
采用InnoDB引擎
- R/W比较小,频繁更新大字段
- 表数据量超过1000万,并发高
- 安全性和可用性要求高
采用Memory引擎
- 有足够的内存
- 对数据一致性要求不高,如在线人数和session等应用
- 需要定期归档数据
作者:人在码途
链接:https://www.jianshu.com/p/a957b18ba40d
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
innodb 引擎的 4 大特性
操作系统
进程和线程的区别
进程间的通信方式有哪些
在一台内存为 2G 的机器上,使用 malloc 分配 20G 会发生什么,new 20G 呢
- 首先,malloc和new申请的都是虚拟内存。和物理内存没有直接关系
- 每个进程允许的虚拟内存是4G,如果是20G的话,已经超出了4G这个上限,无法申请。
- new的话,底层实现还是malloc,在分配失败的时候会抛出bad_alloc类型的异常
什么是孤儿进程,僵尸进程,惊群效应
Ubuntu 开机过程中系统做了哪些事情
堆和栈的区别
乐观锁和悲观锁
如何监控进程异常退出
线程怎么将一个全局变量变成私有变量
两个不同的进程同时使用一个端口号有没有问题
1 | 每个进程分别绑定不同的网卡地址的同一端口 |
虚拟内存的原理
算法
数据流的中位数
二叉树的最近公共祖先
编辑距离
最长公共子序列
合并两个排序的链表
删除排序链表的重复元素
二叉树中和为某一值的路径
二叉排序树的第k大节点
数字转换为十六进制数
反转链表
两个栈实现队列
环形链表 II
排序算法的稳定性是什么
x 的平方根
二叉搜索树与双向链表
一个升序再降序的数组,找到最大值
作者:陈乐乐
链接:https://leetcode-cn.com/circle/discuss/5dPCGA/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
网易
语言
写一个常量指针和指针常量
怎么实现单例模式
单例模式和观察者模式的应用场景
reactor 模式
MVC
了解其他开源的 mallic 方式吗
C++ 14 新特性
C++ 20 新特性
什么是右值引用
什么是智能指针,有哪些,以及实现原理
什么是虚函数
怎么定义虚函数
什么是虚函数表
什么是多态
指针和引用的区别
指针的大小
强制类型转换
如何理解 C++ 的面向对象编程
内存对齐的原则
怎么实现模板
指针和 const 的用法
内联函数和宏定义的区别
extern C 的作用
C 和 C++ 的区别
模板特化的概念,为什么特化
模板为什么要特化,因为编译器认为,对于特定的类型,如果你能对某一功能更好的实现,那么就该听你的。
模板分为类模板与函数模板,特化分为全特化与偏特化。全特化就是限定死模板实现的具体类型,偏特化就是如果这个模板有多个类型,那么只限定其中的一部分。
explicit 干什么用的
new与malloc的 区别,delet 和 free 的区别
vector 底层如何实现的,如果内存不够执行什么操作
sizeof(1==1) 在 C 和 C++ 中分别是什么结果
计算机网络
长连接和短连接
怎么在服务端实现长连接
http 和 https 区别,https 加密方式
http 头部包含哪些,keep-alive 和非 keep-alive 区别,对服务器性能有影响吗
怎么知道 http 的报文长度
如果你访问一个网站很慢,怎么排查和解决
域名和 ip 的关系,一个 ip 可以对应多个域名吗
为什么 fidder,charls 能抓到你的包,过程是什么
tcp 三次握手和四次挥手
TIME_WAIT状态会导致什么问题,怎么解决
tcp 如何保证可靠传输
ping ip 的过程
拥塞控制和流量控制
tcp 和 udp 的区别
tcp 粘包问题
tcp 报文包含哪些信息
如果不想让一个人上网,除了MAC地址进行限制之外还能怎么做
私网地址和公网地址之间进行转换:同一个局域网内的两个私网地址,经过转换之后外面看到的一样吗
对称加密和非对称加密的区别
epoll水平触发和边沿触发,底层原理
数据结构
跳表的实现原理
哈希表的具体实现,哈希函数和哈希冲突等
字典树的实现原理
红黑树的定义和解释
二叉树有哪几种遍历方式
map 与 unorder_map 的区别
vector 和普通数组的区别
数据库
MySQL、MongoDB 区别以及适用场景
MySQL 有哪些存储引擎以及它们的区别和适用场景
Redis 有哪些对象,什么情况用什么对象
Redis 中的跳跃表
Redis 和关系型数据库比有什么特点
Redis 中是怎么避免突然断电等数据丢失的问题的
数据库的事务特点
数据库的隔离级别
分表和分区
假如查询的字段不是你分区的字段,如何提高效率
数据放在内存中的数据库有什么隐患
bin
操作系统
linux 内核原理了解哪些
Linux 文件系统
哪些方法可以读取文件内容
共享内存的实现原理
进程怎么进行管理
进程间的通讯方式
进程和线程的区别
系统平均负载如何计算
read 函数详细调用过程
怎么通过 inode 节点的文件偏移量知道读取哪个页
当页缓存未命中时会发生什么
怎么样知道该页的磁盘地址
如何实现内存池
如何检测出现了内存碎片,如何解决
如何检测内存泄漏
实现多线程有哪些方法
多线程的缺点
互斥锁和自旋锁的区别和优点
死锁如何产生
堆和栈的区别和优点
有哪些调度算法
内存溢出有那些因素
异常机制
top 怎么查看线程
Linux下的/var 目录有什么用
意思:linux中/etc是配置文件的目录,/var是储存各种变化的文件。
特点:
/etc的特点:包含了广泛的系统配置文件,这些配置文件几乎包含了系统配置的方方面面,是一个底层的重要项目,通常添加一些次等重要的零碎事物。
/var的特点:包含系统运行时要改变的数据。其中包括每个系统是特定的,即不能够与其他计算机共享的目录。
什么是并行计算
算法
反转链表
合并两个有序链表
快速排序的实现原理
strcpy 函数的实现
链表中的倒数第k个节点
海量 url 去重
二叉树的镜像
最短路径算法 (Dijkstra和floyd算法)
网格中的最短路径
前k个高频元素
作者:陈乐乐
链接:https://leetcode-cn.com/circle/discuss/0BJL7O/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
滴滴
语言
C++的三大特性
指针和引用的区别
什么是多态,多态的实现方式
动态多态和静态多态
虚函数的工作原理
什么是纯虚函数
虚函数表存放的内容
虚表指针和虚函数表的存放位置
构造函数可以是虚函数吗,为什么
析构函数可以是虚函数吗,为什么
什么是智能指针,有哪些,实现原理
怎么避免循环引用
C++内存管理
函数调用机制
C++11 新特性
malloc 底层原理
new 和 malloc 的区别;delete 和 free 的区别
有哪些强制类型转换,使用的区别
什么是函数重载,实现原理
const 关键字的使用
static 关键字的使用
浅拷贝和深拷贝
i++是原子操作吗
C++类对象从编写代码定义到生成可执行文件的全过程描述
类对象的内存分布与生存周期
在C++中,我们所使用的的对象都有严格的生存周期。所谓的对象生存周期是指对象从创建开始到被释放为止的时间。对于静态内存中存储的局部static对象、类static数据成员以及定义在任何函数之外的变量,全局对象(任何函数之外的对象)在程序启动时分配,在程序结束时销毁;对于局部static对象、类static对象在第一次使用前分配内存,在程序结束时销毁。
对于栈内存,用来保存定义在函数内的非static对象。对于局部自动对象,当我们进入其定义所在的程序块时被创建,在离开块时销毁,分配在静态或栈内存中的对象由编译器自动创建和销毁。除了静态内存和栈内存,每个程序还拥有一个内存池。这部分内存被称作自由空间或堆。程序用堆来存储动态分配的对象(程序运行时分配的对象)。动态内存管理是通过一对运算符来完成的:new在动态内存中为对象分配空间并返回一个指向该内存对象的指针;delete接受一个动态对象的指针,销毁该对象,并释放与之关联的内存。
版权声明:本文为CSDN博主「yang20141109」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/yang20141109/article/details/50373396
计算机网络
TCP和UDP 区别
TCP和UDP首部字节数以及其相应的字段含义
TCP如何保证可靠性和有序性
如何使用UDP实现可靠性
三次握手过程
为什么不是四次握手和两次握手?
time_wait为什么等待2msl,time_wait过多怎么解决
简单来说,就是打开系统的TIMEWAIT重用和快速回收。
2
net.ipv4.tcp_tw_recycle = 1 表示开启TCP连接中TIME-WAIT sockets的快速回收,默认为0,表示关闭。
四次挥手过程
抓包的实现原理
Fin_wait2状态
拥塞控制算法
拥塞控制和流量控制的区别
滑动窗口最大值
http 和 https 的区别
了解哪些 http 状态码
数据结构
什么是双链表
二叉搜索树,平衡二叉树,红黑树的区别
B Tree和B+ Tree的区别
map和unordered_map 的区别
数据库
数据库索引的作用,应用场景
ACID 特性
如何优化 SQL 语句
操作系统
进程和线程的区别
什么是协程
进程间通信方式
线程之间的同步方式
socket 本地通信需要通过 TCP/IP 协议栈吗
多线程编程要考虑什么
进程和线程的使用怎么进行选择
线程切换需要消耗资源,怎么高效的切换线程
什么是惊群效应
Linux 虚拟内存方式
Linux 页大小
什么是页表,同一进程的不同线程是否共享页表
32位机和64位机的区别
基本I/O模型
有哪些 IO复用模型
select,poll,epoll 的区别
如何用select实现一个定时器
epoll 高效的原理
epoll数据在内核态和用户态之间是怎么切换的
epoll,水平触发和边缘触发的区别
内核态和用户态的区别
一致性哈希算法
自旋锁和互斥锁区别
什么是内存对齐,为什么需要内存对齐
什么方式可以减少内存碎片
虚拟内存机制
虚拟内存mmap的概念,原理,应用场景,与系统调用比的优缺点
死锁的必要条件
如何避免死锁
银行家算法
算法
快速排序的思想和实现
实现线程安全的单例模式
环形链表
环形链表 II
二叉树和为某一值的路径
根据前序和后序遍历构造二叉树
LFU
LRU
LRU缓存机制
删除链表的重复元素
二叉搜索树
全排列
链表倒数第k个节点
汉诺塔
八皇后
连续子数组的最大和
计算岛屿数量
最大子序和
有效的括号
最长有效括号
二叉树的镜像
N叉树的前序遍历
二叉树的层序遍历
作者:陈乐乐
链接:https://leetcode-cn.com/circle/discuss/9kE1Sc/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
B站
语言
C 和 C++ 的区别
指针和引用的区别
malloc 和 new,free 和 delete 的区别
extern C 的作用
常用的容器有哪些
volatile 关键字的作用
有哪几种强制类型转换以及使用场景
const_cast 将常量指针转化为非常量
static_cast 隐式转换,不太安全
dynamic_cast 是将一个基类对象指针(或引用)转换到继承类指针
reinterpret_cast [重新翻译二进制比特位]是强制类型转换符用来处理无关类型转换的,通常为操作数的位模式提供较低层次的重新解释!但是他仅仅是重新解释了给出的对象的比特模型,并没有进行二进制的转换!
c++11 新特性
C++ 20 新特性
C++ 的三大特性
C++的多态实现原理
什么是虚函数
什么是纯虚函数
虚表指针的大小
虚函数表的存放内容
构造函数可以是虚函数吗
析构函数可以是虚函数吗
一个空类会生成哪些函数
左值和右值
什么是智能指针,有哪几种,作用,实现原理
如何避免循环依赖
unique_ptr 中 std::move() 作用
static 关键字的使用
const 关键字的使用
define 和 online 的区别
面向对象的设计原则
C++ 编译过程
函数调用的具体实现
计算机网络
三次握手和四次挥手
四次挥手为什么要有 close_wait 状态
tcp 长时间不断开连接会不会断连
tcp 超时重传机制
tcp 如何保证可靠传输
TCP 和 UDP 的区别
TCP 报文长度字段设置在哪里
哪些协议是 TCP 的,哪些是 UDP 的
UDP 怎么实现可靠传输
HTTP 请求报文结构
http 和 https 的区别
怎么解决粘包问题
拥塞控制
流量控制
拥塞控制和流量控制的区别
如何判断网络拥塞
GET 和 POST 的区别
cookie 和 session 区别
DNS 的原理
数据结构
什么是跳表
一个两层的跳表查询时可以降低倒多大的复杂度
vector 和 list 的区别
vector 的扩容原理
map 底层实现
map 和 unordered_map 的区别
如何计算循环链表的长度
二叉搜索树和平衡二叉树,红黑树的区别
红黑树删除数据是怎么调整的
什么是哈希表,哈希函数,怎么解决冲突
stl sort 函数的实现
数据库
redis 的数据类型
redis 的缓存删除策略
redis 怎么实现的定期删除
mysql 中使用的锁有哪些?什么时候使用行锁,什么时候会使用表锁
mysql 的 binlog 日志什么时候会使用
undo 日志和 redo 日志分别是干嘛的
事务还没执行完数据库挂了,重启的时候会发生什么
数据库的 MVCC 的实现原理
事务隔离级别
操作系统
操作系统分段、分页
定时器的实现
读写锁
如果读写锁占用很长时间,并且后续还有读者不断占用读锁,这就造成了写者饥饿的问题,怎么解决?
自旋锁
乐观锁和悲观锁
select、poll 和 epoll 的区别
为啥 epoll 为啥能突破文件上限大小
水平触发和边缘触发的区别
线程和进程的区别
进程之间的状态转换
如何创建多线程
如何实现线程同步
进程之间的通信方式
什么是协程,什么情况下可以使用协程
了解线程模型吗?用户态的线程怎么和内核态的线程映射的
动态链接和静态链接的区别
如何创建一个守护进程
孤儿进程和僵尸进程
系统是如何检测孤儿进程的
Docker 的优缺点
虚拟内存的实现原理
内存泄漏和内存溢出是指什么,内存溢出有什么危害
算法
二叉树的层序遍历
反转链表
实现 strStr()
快速排序时间复杂度,实现原理
形成三的超大倍数
两数相加
回文链表
二叉树的最近公共祖先
作者:陈乐乐
链接:https://leetcode-cn.com/circle/discuss/h3upVc/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
美团一面凉经
自我介绍
介绍自己做的有成就感的一件事
数据库的行锁底层是怎么实现的
数据库是什么引擎?
智力题:有很多不均匀(长度、粗细不同)的香,每根香都可以燃烧一个小时,如何精准的计算半个小时?(用两根香,一根香两头同时点,另一根香只点燃一头,当第一根香燃烧完毕时,这时候刚好半小时)
问项目:模型的评估的指标?
Linux 命令:看CPU的使用情况top命令
什么是死锁?
手撕代码:判断链表中有没有环?
设计模式 ?简单介绍几个设计模式
http状态码?
tcp三次握手
面经总结
数据库:
聚簇索引和非聚簇索引的区别?使用场景
MySQL数据库的索引有哪些?
什么情况下建议使用索引?
索引的引擎?分别有什么区别
MySQL分页原理
主键索引和辅助索引有什么区别?有什么联系
数据结构:
B+树和B树的区别?优缺点?应用场景
哈希冲突如何解决?
红黑树的特点?
红黑树的左旋右旋?
链表和数组的区别?
操作系统:
IO多路复用的实现方式
BIO 和 NIO 是什么?
进程和线程的区别?
什么是协程?协程的轻量级体现在哪里?
同步和异步的区别?阻塞和非阻塞的区别
计算机网络:
介绍五层模型以及相应的协议?
HTTP和HTTPS的区别?
HTTPS是如何保证安全的?
cookie和session的区别?
Http的状态码?(这里面试官会挑其中的几个问)
线程池
TCP如何实现可靠传输?
浏览器中输入了url到网页显示的完整过程?整个过程涉及到了哪些协议?
C++:
多态是如何实现的?
虚函数和纯虚函数的区别?
虚函数实现的原理?
动态链接和静态链接?二者的区别?
函数指针和指针函数的区别?
vector的底层原理?如何进行容量扩增?
指针和引用的区别?
struct和class的区别?
重载和重写的区别?
面向对象和面向过程的区别?
作者:Crystal
链接:https://leetcode-cn.com/circle/discuss/SdQ4FO/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
学习路线及时间安排
推荐时间为4个月,包括四部分:语言,计算机基础知识,项目基础知识,项目实践。
- 语言
- 推荐学习1个月
- 学习方针:视频为主,书籍为辅。
- 配套视频:C语言,C++语言
- C++ Primer Plus
- 集中学习该书的1~8章,涉及C语言基础语法及指针、结构体的使用。
- C和指针
- 该书全面深入的剖析了指针的概念与使用,是C语言的进阶。
- C++ Primer
- 作为C++查询的工具书,相当于新华词典,里面会涉及C++的很多技术细节,实际工程中用到的并不会太多。平时遇到问题可以查询该书,另外也可以作为面试的参考书。
- STL源码解析
- 涉及C++标准模板库的源码实现,其中vector、map的实现需要重点关注,比如内存分配,底层数据结构等。

- 计算机基础知识
- 推荐学习1个月
- 配套视频:数据结构
- 数据结构
- 视频为主,书籍为辅。看小甲鱼的数据结构,该视频以大话数据结构为蓝本讲解,了解链表,栈,队列,二叉树,哈希表,堆等基础的数据结构。
- 算法
- 推荐直接刷题,先临摹再实战。推荐书籍剑指offer,左程云大神的程序员代码面试指南;刷题网站推荐牛客网。
- 操作系统
- 推荐书籍学习,重点看深入理解计算机系统的6,7,9,10章。主要理解线程,进程,虚拟内存及锁机制。
- 计算机网络
- 推荐书籍学习。主要理解TCP/UDP/HTTP三种协议。其中TCP/UDP以谢希仁老师的计算机网络为主,HTTP以图解HTTP协议为主。
- 设计模式
- 推荐书籍学习,大话设计模式。设计模式可以放在所有知识的最后进行学习。
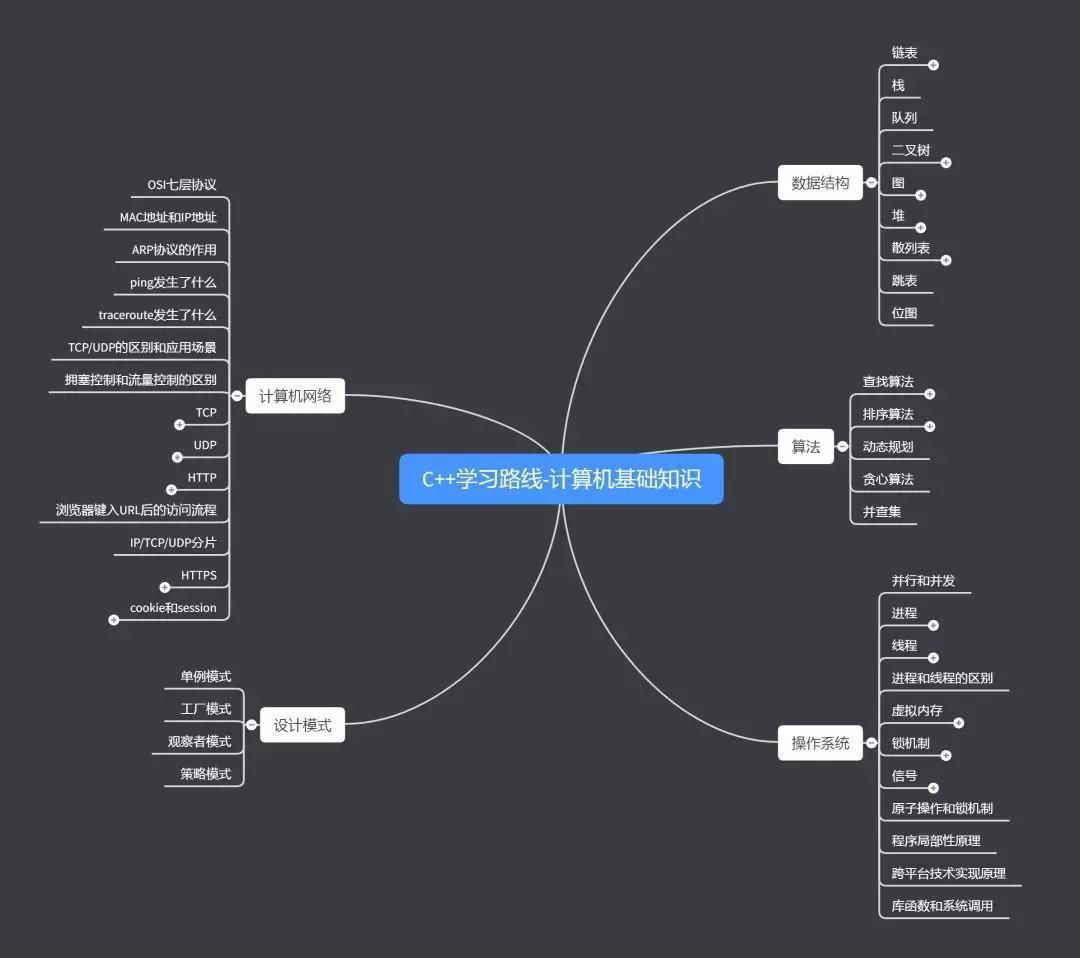
- 项目基础知识
- 推荐学习1个月
- 配套视频:Linux,数据库
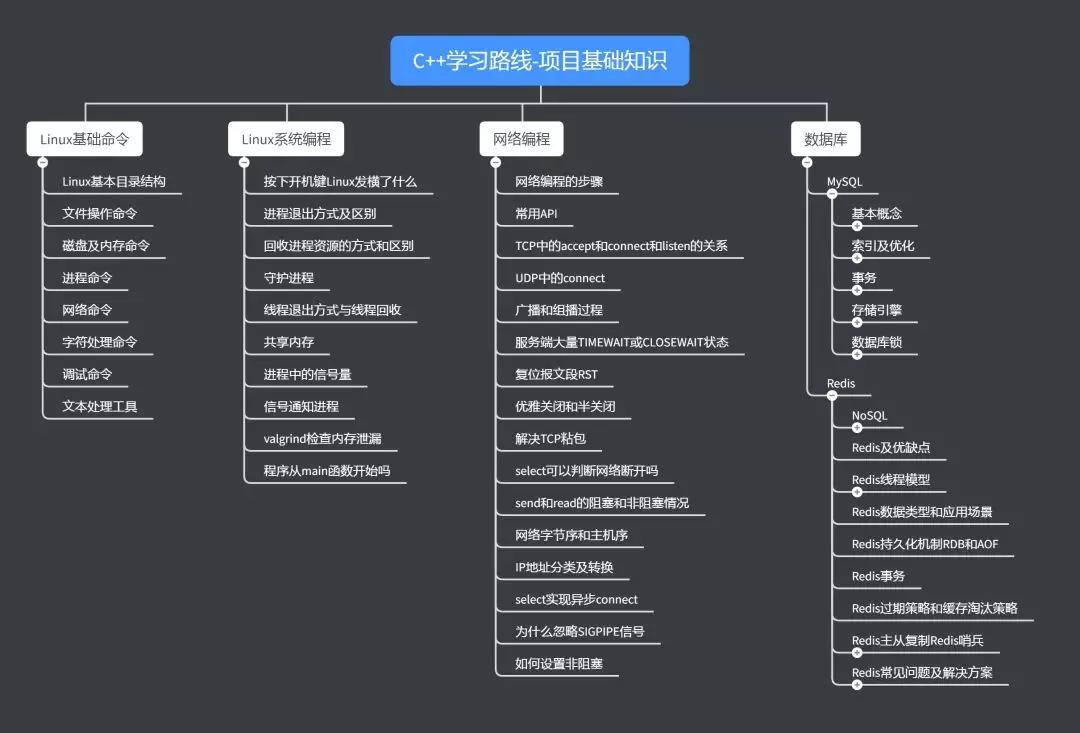
- Linux基本命令
- 该部分主要以看视频为主,记住常用的即可,其余的在实际使用时即用即搜。
- Linux系统编程
- 在Linux下进行编程,会涉及到与系统的交互,内存访问,需要学习Linux系统API用法。
- 网络编程
- 视频为主,书籍为辅。书籍先看tcp/ip网络编程查漏补缺,补齐网络编程基础知识,然后看Linux高性能编程。
- 数据库
- 视频为主,书籍为辅。MySQL和Redis数据库是当前面试的热门,书籍先看MySQL必知必会,再看Redis设计与实现。
- 项目实践
- 项目名称为Linux下C++轻量级Web服务器开发,实现web端用户注册,登录功能,经压力测试可以实现上万的并发连接。(测试机器为Intel i7 7700,16G内存)
- 推荐学习1个月
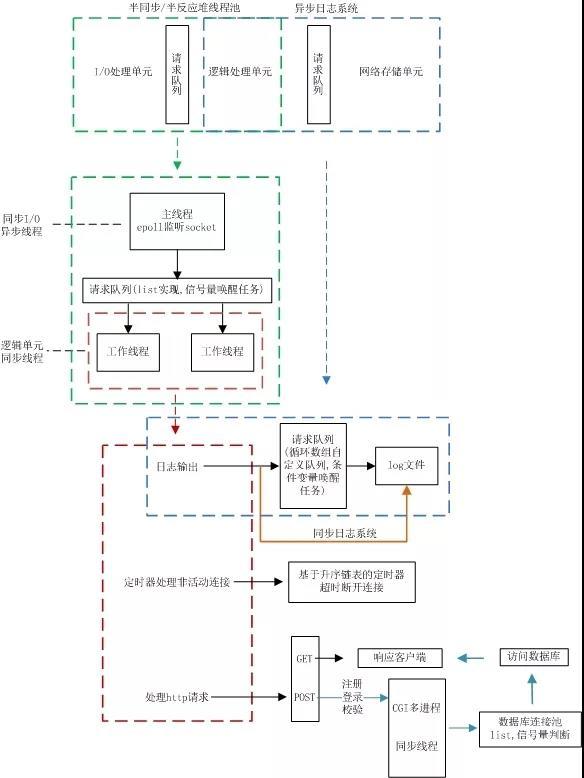
- 线程池
- 涉及线程,锁机制。使用一个工作队列完全解除了主线程和工作线程的耦合关系:主线程往工作队列中插入任务,工作线程通过竞争来取得任务并执行它。
- HTTP请求与响应
- 涉及Linux系统编程,网络编程,TCP和HTTP协议。根据状态转移,通过主从状态机封装了http连接类。其中,主状态机在内部调用从状态机,从状态机将处理状态和数据传给主状态机。
- 注册登录
- 涉及少许网页html知识。实现用户名和密码校验,另外通过html文件设置action实现跳转。
- 定时器
- 涉及Linux系统信号及数据结构的使用。由于非活跃连接占用了连接资源,严重影响服务器的性能,通过实现一个服务器定时器,处理这种非活跃连接,释放连接资源。
- 数据库连接池
- 涉及MySQL数据库。建立数据库连接池,通过重复使用这些已经建立的数据库连接,解决频繁建立连接的缺点,从而提高系统性能。
- 同步/异步日志系统
- 涉及设计模式,自定义阻塞队列。同步/异步日志系统主要涉及了两个模块,一个是日志模块,一个是阻塞队列模块,其中加入阻塞队列模块主要是解决异步写入日志做准备。
- 压力测试
- 阅读Webbench源码,对进程加深理解。通过Webbench创建多个进程,每个进程通过HTTP连接访问服务器,完成压力测试。
相关资料电子书链接:https://pan.baidu.com/s/1dD_F6aG5dIetaks0kIobAg提取码:buim
视频链接:https://pan.baidu.com/s/1tri7oj_R_J4QU__8RjZq7w提取码:emtp
项目Linux下C++轻量级Web服务器https://github.com/qinguoyi/TinyWebServer
知识总结https://github.com/twomonkeyclub/BackEnd
作者:这波有什么问题
链接:https://www.nowcoder.com/discuss/379063?type=all&order=time&pos=&page=1
来源:牛客网
1自我介绍
2实习项目(问的挺详细的),实习学到了哪些东西
3看过哪些c++的书,印象最深的是哪个?具体是什么方面
4除了看书还通过哪些渠道学习c++?有没有喜欢的博主?有没有自己写过博客?
5虚函数的实现原理?
6析构函数有没有必要都设置成虚函数?为什么?
7Socket编程了解过吗?
8网络的知识了解的多吗?说一下tcp连接和释放的过程?
9Vector的底层实现原理?STL容器哪些用的比较多
10map和unorder_map的底层实现和区别?
11哈希表的实现原理?如何解决哈希冲突?哪种方法更好?
12有什么方法可以避免申请的内存忘记被释放?
作者:Buermy
链接:https://www.nowcoder.com/discuss/394076?type=0&order=0&pos=1&page=1
来源:牛客网
一面:电话面
1.自我介绍;
2.你是非科班的,说一下你的自学过程;
3.简单介绍一下你的项目;
4.项目用到了epoll,讲一下epoll的ET模式和LT模式;
5.讲一下epoll的oneshot?
6.惊群效应;
7.有什么想问的吗?
这一面感觉就是简单聊天
二面:视频面
1.介绍一下项目;
2.项目用到了线程池,如何避免多线程的同步错误?
3.线程间的通信机制;
4.项目用到了stl,从源码角度讲一种你熟悉的stl容器的实现?map与unordered_map的底层数据结构与查找复杂度;
5.项目是用Cpp11写的吗?讲一下Cpp11的新特性?
6.讲一下智能指针为何能避免内存泄露?为什么匿名函数能提高程序效率?
7.你的http报文解析是怎么做的?用到了什么数据结构?如果http应答报文大于你设定的写缓冲区怎么处理?
8.既然tcp更可靠,为什么有很多项目还是优先选择udp?udp快在哪里?如何保证udp的可靠性?
9.libevent了解过吗?讲一下libevent的原理;
10.内存对齐;
11.虚函数工作原理;
12.什么时候用模板函数?什么时候用虚函数?
13.Cpp 类对象的内存分布;
14.手撕LRUmap
这一面主要面基础
三面:视频压力面
1.介绍一下你的项目;
2.你写的服务器性能怎么样?
3.服务器压力测试怎么做的?
4.服务器吞吐量?
5.服务器响应时间?
6.如何减少响应时间?
7.如何确定服务器的最大并发连接数?
8.讲一个你做过的一个确实能用的项目;
9.还有什么问题吗?
这一面节奏很快,如果不能很快答出来就立刻跳到下一个问题,而且面试官很严肃
四面:电话hr面
1.做一下自我介绍;
2.你在一年时间内又要做项目又要自学计算机基础又要打比赛,时间是怎么分配的?
3.你是哪里人?未来打算在哪里发展?
4.现在拿到几个offer了?
5.最早能过来实习的时间?实习时长?
6.还有什么要问的吗?
hr小姐姐人很好,感觉放轻松聊天就好了
作者:A1kaid
链接:https://www.nowcoder.com/discuss/395060?type=0&order=0&pos=13&page=1
来源:牛客网
事业群:CSIG 在线教育部
Base:深圳
技术栈:半路出家学了半年的C++、学了一年的Python
个人项目是烂大街的服务器和一个外包🤣
团队项目是两个和数据挖掘相关的项目🤣
电话一面(40min)
项目介绍
小根堆计时器是怎么样的机制
优先队列和map的区别是什么
vector的内部结构
如何避免vector的动态扩容
vector越界访问会怎么样
红黑树的规则
红黑树的增删改查的时间复杂度
往map里面增加或删除元素是怎么实现的
智能指针是自己实现的吗
如何实现智能指针
智能指针的引用计数如何确保线程安全
怎么实现原子操作
RAII机制具体是什么含义
日志系统的相关问题
线程池是怎么使用的
长连接过程中线程一直持有连接对象吗
有用过什么数据库
数据库的字段类型是如何设计的
用的是什么数据库引擎
Innodb和MyISAM的区别
varchar最大长度是多少
varchar如果长度超过了怎么办
Linux常用的命令
压测如何查看在哪里达到瓶颈
有什么问题?
总结:一面的时候挺突然的,所以也没多准备,主要围绕的是简历上的项目来问,中间夹杂着一些基础的询问,所以最终结果也还好,最后询问的时候面试官也肯定了我的C++基础不错,并且说了会有下一面。
视频二面(40min)
自我介绍
有用过部门的产品吗?
讲一讲团队项目?为什么要使用这些算法?算法是如何挑选的
讲讲DBSCAN和KMeans算法的区别,讲一下你理解的DS证据理论
介绍项目
EPOLL和Select的区别
为什么要使用边缘触发模式
EPOLL ET和LT的区别
ET模式下,要遵循哪些规范
Reactor和Proactor模式的区别
如何保证线程安全
请求进入之后是如何处理的
Time-wait状态过多会有什么后果,怎么处理?
长连接和短连接之间是如何处理的
为什么采用小根堆的优先队列作为定时器
对请求报文的解析是自己写的还是调用库,难度在哪
日志系统是如何保证高并发的
日志系统如何保证线程安全
有看过其他开源服务器吗
Nginx的请求处理流程
目前有投什么公司
为什么CVTE刷了你 (HR面刷的- -无语)
头条和腾讯选择哪个
总结:一开始的时候也没想到面试官会问我的团队项目里面的算法内容- -不过好在之前有特地的去看过相关的,所以答的也还算是流畅。可能是因为这个所以整个面试流程下来完全没撕代码?
作者:徐皖辉
链接:https://www.nowcoder.com/discuss/407325
来源:牛客网
4.14日 早上看了下状态已灰…只能等正式批笔试再试试了,大家都加油!
之前被一个师兄坑了,4,1号才在官网投的简历,等了大概一周才有面试机会,结果一面有点凉凉,难受…
1. 自我介绍
2. C++中的智能指针有哪些(shared_ptr,unique_ptr,weak_ptr)
3. shared_ptr指向一个动态数组需要注意什么(我不知道,就猜测性的答了一下,回来百度发现说错了…正确说法是需要注意指定删除函数delete[],默认的delete会导致内存泄露)
4. static关键字定义静态成员数据、函数的作用(对象共享)
5. 静态成员函数能否调用非静态成员函数(不能,生存周期不同,且静态成员函数没有this指针,无法调用,我当时是根据它们在内存的分布来答的,有点混乱…),非静态成员函数调用静态成员函数(只能通过类名调用)
6. int i = 0; i++=6合法吗(不合法,为什么?求个大佬解答,我知道表达式不能赋值);++i=6合法吗(合法,i=6,为什么?)(我当时答反了,我说的++i=6是右值不能赋值,i++=6先赋值再做+1操作,完全错了,面试官只点头说恩…无语了)
7. 编程题1:最长不重复子串(A了,比较简单,有多种方法,我使用hashmap实现的,没要求空间复杂度O(1))
8. 编程题2:将单链表的每k个节点反转(思路简单,我按照链表反转的思路写出来了,但是运行一直有问题,调bug一直没调出来,最后时间差不多,就叫停了)
9. linux命令:修改文件权限(chmod 777 file)
10. linux命令:查看内存或cpu(top)
11. mysql主从复制的方式(1.基于 SQL 语句的复制(statement-based replication, SBR);2.基于行的复制(row-based replication, RBR);3.混合模式复制(mixed-based replication, MBR);4.基于 SQL 语句的方式最古老的方式,也是目前默认的复制方式,后来的两种是 MySQL 5 以后才出现的复制方式)(我说成复制方式(异步复制,全同步复制,半同步复制),方向都错了,真的不太了解的不能乱答,数据库主备这块确实不太熟悉)
12. 一个进程里面的多线程,如果其中一个线程挂掉了,影响其他线程吗(一个线程挂掉,其他线程也挂掉)(比较完整缜密的说法是:1.如果进程不屏蔽 segment fault 信号,一个线程崩溃,所有线程终结。2.如果屏蔽 segment fault 信号,且线程崩溃的位置是线程私有位置(stack),那么其他线程没有问题。3.如果屏蔽 segment fault 信号,且线程崩溃的位置是线程共享位置(heap、全局变量等),那么其他线程也会出现问题。)
可能还有一点比较简单的问题,我不太记得了…历时应该是超过1个小时了。
结束时问了我能实习多长时间,然后就是告知等待后续的通知。
挺凉的,没有把握的问题,回答错了,不应该这么草率的,感觉面试官最讨厌乱答的人,还不如直接说不知道(主要是我觉得我这样orz…)。编程题第二道没做出来,还浪费了好多时间,唉,感觉后面就是问我几个比较简单的来结束面试了。
面试结束后看了个人主页,暂时还没灰,先等等吧,太菜了,真的不行啊!
过来发牛客,求个二面!
作者:王°
链接:https://www.nowcoder.com/discuss/407296?type=2&order=1&pos=10&page=1
来源:牛客网
1.tcp流量控制跟拥塞控制
2.进程通信方式、进程调度方法、进程跟线程区别
3.mysql索引引擎区别,数据库三大范式
4.java内存模型、GC回收算法跟垃圾收集器
5.java接口跟抽象类区别
6.linux 查看进程信息、端口占用命令
7.工厂模式,编码
8.算法题
LRU、求树高,环形链表入环几点
作者:健康成长天线宝宝啊
链接:https://www.nowcoder.com/discuss/147538
来源:牛客网
后台开发包括的知识点很多,包括语言基础,算法,linux编程基础,linux内核,网络,数据库,分布式等等。面面俱到很难,一个领域钻研的很深也很难。我认识的大神里有把C++语言吃的非常透的,也有实验室就是搞分布式的,拿offer都非常轻松。
秋招拿到:
字节跳动后台开发
网易游戏游戏研发
阿里云基础平台开发
华为
腾讯后台开发
我准备应聘的时间从研一的寒假开始,当然自己探索的路上走了不少弯路。
列举一下自己的学习内容中我自己认为对找工作或者对提升自己非常有帮助的一些书或资料,仅供参考~
语言基础,C++语言相关的:
《C++ Primer》,应该算是工具书,但我花了3个月一个字一个字啃完了,现在能记住的没几个了,但是好在全看完就不用看Effective C++了,基本都包含在内了。
《STL源码剖析》,很老的书了,很多内容都过时来了,比如空间配置器,但是面试官还是会问……可以跟面试官讲讲ptmalloc的实现。整本书都是重点。
《深度探索C++对象模型》,虽然基本只会问虚函数的实现,看一篇博客也能应付面试,但是还是建议多看几遍。
《Effective C++:改善程序与设计的55个具体做法》还有more effective C++,建议快速看一下。
STL和对象模型我都看了3遍以上,因为太容易忘了,Effective C++只是快速浏览了一遍,发现基本都包含在Primer里了。
网络,除了本科学过的(《计算机网络 自顶向下方法》),我看了《TCP/IP详解卷1》12-16章,重点是TCP、IP、UDP,其它部分看书太麻烦了,直接从博客里看了。
linux环境编程apue和unp两本是必须的,因为太厚了,看起来还是有点痛苦的,但是不需要全看,而且内容重叠很多。unp卷1前面8章是重点,卷2前面4部分都挺重要的,apue全部,先是要有个概念,自己写代码的时候就知道哪块重要了。
此外,《后台开发:核心技术与应用实践》是腾讯的员工写的,虽然这本书评价比较差,几乎都是抄的博客,但是内容上总结的很好(我觉得就是给校招的同学写的),都是后台开发需要的基础知识的总结,这本书中内容所代表的知识,基本都是腾讯的C++后台开发工程师所必备的基础,可以作为一个复习提纲。
下面的书应该算是提高篇了:
linux内核相关,我买了《深入理解linux内核》发现啃不动,后来看了《linux内核设计与实现》,非常推荐,外加一大堆博客,《深入理解计算机系统》讲的东西比较简单,这个可以作为一个补充,面试官问的很多操作系统相关的问题书中都有涉及。
《Linux多线程服务器端编程》,陈硕的书,讲muduo网络库的,我看了3.4遍,源码也读了3.4遍,收获非常多。前面部分是后台开发的一些经验之谈,对面试也很有用。
《Redis设计与实现》看完感觉也特别好,很值得学习,可以很快就看完。有很多重要的数据结构可以在面试的时候讲出来,比如跳表、redis的 hash表啦~
《深入理解Nginx》我也看了一部分,nginx太经典了,很多面试官也都提到过。
短小精悍的源码还非常推荐leveldb,对照博客把leveldb源码看完不需要多长时间(我花了两个周吧),但是收获非常多。在此基础上还可以了解一下rocksdb。
除此之外,还看过一些其它的书,感觉不值得推荐就不写了。
书是比较系统性的东西,博客通常是总结性的东西,也是对书中内容的一个补充吧。好多东西面试会问到,但是书中很难找到解答,对照着网上的面经搜博客吧。我看了下自己收藏夹里的光是收藏的博客就已经上百篇了,当然还是不能完全覆盖面试官会问到的问题。(这一步是重点啊)
分享一下我自己看过的博客,从手机书签里导出来的,整理了一下:
算法
我只刷了Leetcode上的500多题,但是第一遍不会的题都标记了,后面又刷了很多遍。《剑指offer》这种书不太建议看,很啰嗦,解答也不如LeetCode上的高票解答。直接干刷其实还有点无聊的,每周日上午做一下leetcode的周赛也是个不错的选择,可以当做模拟笔试/面试。另外 Top 100 Liked Questions 可以重点关注一下。
项目
https://github.com/linyacool/WebServer
写了一个静态Web服务器,主要是找实习的时候用的,参考了muduo网络库。
仅供参考!仅供参考!仅供参考!(不要直接拿去面试,你如果自己想做一点东西,有非常多非常多可做的事情,千万不要把github里的描述直接写进简历,结果一问三不知)

海量数据处理 - 10亿个数中找出最大的10000个数(top K问题)
先拿10000个数建堆,然后一次添加剩余元素,如果大于堆顶的数(10000中最小的),将这个数替换堆顶,并调整结构使之仍然是一个最小堆,这样,遍历完后,堆中的10000个数就是所需的最大的10000个。建堆时间复杂度是O(mlogm),算法的时间复杂度为O(nmlogm)(n为10亿,m为10000)。
用构建堆。(找1000个最大的数,构建最小堆)找1000个最小的数构建最大堆
如果你大于老末,那你就可以把老末替换下去。前提是老末位于堆顶上
方法二:分治法 即大数据里最常用的MapReduce。
a、将100亿个数据分为1000个大分区,每个区1000万个数据
b、每个大分区再细分成100个小分区。总共就有1000*100=10万个分区
c、计算每个小分区上最大的1000个数
为什么要找出每个分区上最大的1000个数?举个例子说明,全校高一有100个班,我想找出全校前10名的同学,很傻的办法就是,把高一100个班的同学成绩都取出来,作比较,这个比较数据量太大了。应该很容易想到,班里的第11名,不可能是全校的前10名。也就是说,不是班里的前10名,就不可能是全校的前10名。因此,只需要把每个班里的前10取出来,作比较就行了,这样比较的数据量就大大地减少了。我们要找的是100亿中的最大1000个数,所以每个分区中的第1001个数一定不可能是所有数据中的前1000个。
如果这1亿个书里面有很多重复的数,先通过Hash法,把这1亿个数字去重复,这样如果重复率很高的话,会减少很大的内存用量,从而缩小运算空间,
然后通过分治法或最小堆法查找最大的10000个数。
阿里云
\1. 指针和数组啥区别 内存里怎么访问的 (mov 数组的话基址+offset)
\2. 内存访问一个int 和访问一个int数组啥区别 x86下向量化指令SIMD用过没(见过没写过) arm访存指令 (load/store)
\3. 声明一个数组 在内存里咋样 (推esp)
\4. voliate关键字 (强行写回内存 防止未定义操作)
\5. 结构体 在内存中 怎么存放的(x86下按4字节对齐)为啥 (减少访存次数)
\6. pthread_create
\7. epoll 内核原理。。从网卡收到一个包开始讲起。。(我艹)
\8. 建堆 时间复杂度
\9. malloc sbrk的内存里机制 mmap 文件映射 匿名映射 munmap 为啥munmap能直接释放一段内存 内核怎么实现的 (三句话不离内核 我吐了)
\10. 进程 线程 (进程:通用寄存器+状态寄存器+浮点寄存器+…+整个虚拟地址空间;线程:线程栈+一部分寄存器)
\11. x86 调用寄存器 被调用寄存器 (忘了。。口胡了个ebx ecx被告知了正确答案)
\12. 讲了讲jemalloc结构 为啥jemalloc分配和释放快
\13. gdb 命令 (讲了gdb调试clang) 有没有用gdb调过汇编 (我:gdb还能调汇编???)
\14. git 命令 rebase用过没 git机制 怎么实现的 (讲了个bisect 他也没用过hhhh 正常就clone tag show log push commit fetch pull)
\15. strace ;perf 原理是啥 (不晓得)除了函数统计 微架构相关数据关注过没?(研究过 L1 cache miss)
\16. 算法题
- 说下TCP断开连接(TCP四次挥手,从客户端开始断开连接说的。)close wait 和time wait分别在哪边?啥作用?假如是服务器先断开连接那time wait状态是在服务器那边吗?(我也不清楚,吞吞吐吐说是)
- java 多线程写过没有?线程怎么保证安全?(好像是这么问的,说上锁?? 然后举了个i++自增的例子)
- 红黑树和二分查找复杂度,hash表复杂度,为什么?(O(1),然后说了如果冲突了一般会用拉链法,一个拉链若有N个结点的话,在这个拉链上查找就变成了o(n),然后又问如果是用拉链法的话总体时间复杂度是多少(我开始说O(1),说理由感觉有点懵了,后面说这不是跟拉链长度有关嘛)然后问,拉链要是太长了怎么办(转成树结构),hash表要是太满了如果每一个拉链都特别长呢?(扩容,重新放置元素)还有其他解决冲突的方法没有?(冲突了直接找下一个空闲位置,这个好像叫线性探测法?)
- 进程和线程的区别;同一个进程中的线程共享哪些资源,哪些是独占的。线程是怎么进行切换的。
- 2G内存是怎么运行4g的程序?回答的时候说到,需要用到的页要调入内存,遂问,你怎么知道需要用到哪一页?(我说程序都是顺序存放的,巴拉巴拉,也不知道对不对😂)
- (数据库熟不熟?我说只会一些基本操作)索引是什么(我好像只会说索引的作用是啥,是什么就。。。)
- 有哪些索引?什么是聚簇索引?他的叶子节点和非叶子节点都放了什么?B+树索引有什么特点,好处?为什么不用二叉树?
- 你算法怎么样?(我说我也不知道😂)遂出了这题:加入迈台阶一次可以迈1或2或3步,100阶的台阶有多少种走法?
5211. 概率最大的路径
仅含 1 的子串数
这道题是字节跳动的周赛题,我原先是使用统计出现连续字符的数量,放进一个容器里,然后用等差数列求和的方式来统计的;但是感觉过于复杂,代码如下:
1 | class Solution { |
这个才是比较轻便的做法:
1 | class Solution { |
操作系统
linux的内存管理机制,内存寻址方式,什么叫虚拟内存,内存调页算法,任务调度算法
锁:互斥锁,乐观锁,悲观锁
- 死锁必要条件及避免算法
动态链接和静态链接的区别
静态链接方式:在程序执行之前完成所有的组装工作,生成一个可执行的目标文件(EXE文件)。
动态链接方式:在程序已经为了执行被装入内存之后完成链接工作,并且在内存中一般只保留该编译单元的一份拷贝。
动态链接库的两种链接方法:
(1) 装载时动态链接(Load-time Dynamic Linking):这种用法的前提是在编译之前已经明确知道要调用DLL中的哪几个函数,编译时在目标文件中只保留必要的链接信息,而不含DLL函数的代码;当程序执行时,调用函数的时候利用链接信息加载DLL函数代码并在内存中将其链接入调用程序的执行空间中(全部函数加载进内存),其主要目的是便于代码共享。(动态加载程序,处在加载阶段,主要为了共享代码,共享代码内存)
(2) 运行时动态链接(Run-time Dynamic Linking):这种方式是指在编译之前并不知道将会调用哪些DLL函数,完全是在运行过程中根据需要决定应调用哪个函数,将其加载到内存中(只加载调用的函数进内存),并标识内存地址,其他程序也可以使用该程序,并用LoadLibrary和GetProcAddress动态获得DLL函数的入口地址。(dll在内存中只存在一份,处在运行阶段)
常见的信号、系统如何将一个信号通知到进程
作者:peilin song
链接:https://www.zhihu.com/question/24913599/answer/115102869
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。最近在正好用到这部分内容,刚刚研究过,不算深入,简单说说我的认识吧。
我想先从一些机制和原理开始说,会比较清楚。
信号是一种软件层面上对中断的模拟,而这种软件模拟的信号或者说中断的产生,有三大类:
\1. 硬件异常产生的错误。比如非法访问内存,除数为0…
\2. 外部信号。键盘上的Ctrl-C产生SGINT信号,定时器到期产生SIGALRM…
\3. 显示的请求。 主要是通过Kill函数发送信号给指定进程。在Linux里面每个进程都是按照进程描述符 task_struct 结构创建的,还有一个叫task vector的东西,从名字上就能看出来这是一个数组,这里面保存的是指向每一个进程的指针,即指向每一个task_struct的指针,因此一个Linux系统最大的进程数,取决于task vector这个数组的大小,一般默认是512个。
在进程描述符task_struct里面,其中一项是Signal_Strct,在Signal_Strct这里面有一项list_head的描述符,在这里面有一个sigset_t表,定义了64种信号的所代表的含义。
铺垫了很多,其实主要是为了铺垫64种信号存放的位置。也就是说在每个进程之中,都有存着一个表,里面存着每种信号所代表的含义,而这也是信号机制的根本。
由于信号的触发和发送是随机的,也就是异步的。接收进程是无法预知什么时间,会收到哪个信号的。下面就开始讲下信号的详细发送机制,举例说明,如果有A,B两个进程,A进程接收到出发条件,开始发送信号给B进程,信号并不是直接从进程A发送给进程B,而是要通过内核来进行转发。之所以要通过内核来转发,这样做的目的应该也是为了对进程的管理和安全因素考虑。因为在这些信号当中,SIGSTOP和SIGKILL这两个信号是可以将接收此信号的进程停掉的,而这类信号,肯定是需要有权限才可以发出的,不能够随便哪个程序都可以随便停掉别的进程。
A进程发送的信号消息,其实就是根据上面的那个信号表,根据需要对相应的表项进行设置。内核接受到这个信号消息后,会先检查A进程是否有权限对B进程的信号表对应的项进行设置,如果可以,就会对B进程的信号表进行设置,这里面信号处理有个特点,就是没有排队的机制,也就是说某个信号被设置之后,如果B进程还没有来及进行响应,那么如果后续第二个同样的信号消息过来,就会被阻塞掉,也就是丢弃。
内核对B进程信号设置完成后,就会发送中断请求给B进程,这样B进程就进入到内核态,这个时候进程B根据那个信号表,查找对应的此信号的处理函数,然后设置frame,设置好之后,跳回到用户态执行信号处理函数,处理完成后,再次返回到内核态,再次设置frame,然后再次返回用户态,从中断位置开始继续执行。
这个frame其实就是在用户态和内核态之间跳转的时候,对堆栈现场的压栈保存。
大致的原理就是这么一个过程,在真正使用的时候,就比较简单了,用kill函数发送信号,在接收进程里,通过signal或者signalaction函数调用sighandler,来启动对应的函数处理信号消息。
内核给进程发送信号,是在进程所在的进程表项的信号域设置对应的信号的位。
进程检查信号的时机是:进程即将从内核态返回用户态时。如果进程睡眠了,要看睡眠能不能被中断,如果能被中断则唤醒。
进程有一个链表的数据结构,维护一个未决信号的链表。
信号在进程中注册,其实就是把该信号加入到这个未决信号链表当中。
可靠信号不管链表中是否已经有这个信号了,还是会加进去。不可靠信号,如果链表中已经有这个信号了,就会忽略。
进程处理信号的时机就是从内核态即将返回用户态的时候。
执行用户自定义的信号处理函数的方法很巧妙。把该函数的地址放在用户栈栈顶,进程从内核返回到用户态的时候,先弹出信号处理函数地址,于是就去执行信号处理函数了,然后再弹出,才是返回进入内核时的状态。
被屏蔽的信号,取消屏蔽后还会被检查。
版权声明:本文为CSDN博主「左耳朵猫」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/Nick_666/article/details/78391946linux系统的各类同步机制、linux系统的各类异步机制
如何实现守护进程
标准库函数和系统调用的区别
linux 服务器
- 32位系统一个进程最多有多少堆内存
- 五种I/O 模式:阻塞I/O,非阻塞 I/O,I/O 多路复用,信号驱动 I/O,异步 I/O
- select 模型和 poll 模型,epoll模型
- socket服务端的实现,select和epoll的区别(必问)
- epoll哪些触发模式,有啥区别?
- 用户态和内核态的区别
- linux文件系统:inode,inode存储了哪些东西,目录名,文件名存在哪里
计算机网络
- TCP和UDP区别
- TCP和UDP头部字节定义
- TCP和UDP三次握手和四次挥手状态及消息类型
- time_wait,close_wait状态产生原因,keepalive
- 什么是滑动窗口,超时重传
- 列举你所知道的tcp选项
- connect会阻塞检测及防止,socket什么情况下可读?
- socket什么情况下可读?
- connect会阻塞,怎么解决?(必考必问)
- keepalive是什么?如何使用?
- 长连接和短连接
- UDP中使用connect的好处
- DNS和HTTP协议,HTTP请求方式