这篇文章主要记述了STL和一些C++的知识点。

函数指针
1 | int maxValue (int a, int b) { |
而这段代码编译后生成的CPU指令存储在代码区,而这段代码其实是可以获取其地址的(只能是在编译时获取的吧,在运行时获取感觉不太现实啊),而其地址就是函数名,我们可以使用指针存储这个函数的地址——函数指针。
函数指针其实就是一种特殊的指针——指向一个函数的指针。在很多高级语言中,它的思想是很重要的,尤其是它的“回调函数”,所以理解它是很有必要的。
函数指针定义与使用
任何变量定义都包含三部分: 变量类型 + 变量名 = 初值,那么定义一个函数指针,首先我们需要知道要定义一个什么样的函数指针(指针类型),那么问题来了,函数的类型又是什么呢?我们继续分析这段代码:
1 | int maxValue (int a, int b) { |
这个函数的类型是有两个整型参数,返回值是个整型。对应的函数指针类型:
1 | int (*) (int a, int b); |
对应的函数指针定义:
1 | int (*p)(int x, int y); |
参数名可以去掉,并且通常都是去掉的。这样指针p就可以保存函数类型为两个整型参数,返回值是整型的函数地址了。
1 | int (*p)(int, int); |
通过函数指针调用函数:
1 | int (*p)(int, int) = NULL; |
回调函数
上述内容是函数指针的基础用法,然而我们可以看得出来,直接使用函数maxValue岂不是更方便?没错,其实函数指针更重要的意义在于函数回调,而上述内容只是一个铺垫。
举个例子:
现在我们有这样一个需求:实现一个函数,将一个整形数组中比50大的打印在控制台,我们可能这样实现:
1 | void compareNumberFunction(int *numberArray, int count, int compareNumber) { |
这样实现是没有问题的,然而现在我们又有这样一个需求:实现一个函数,将一个整形数组中比50小的打印在控制台。”What the fuck!”
然而回到现实,这种需求是不可避免的,你可能想过复制粘贴,更改一下判断条件,然而作为开发者,我们要未雨绸缪,要考虑到将来可能添加更多类似的需求,那么你将会有大量的重复代码,使你的项目变得臃肿,所以这个时候我们需要冷静下来思考,其实这两个需求很多代码都是相同的,只要更改一下判断条件即可,而判断条件我们如何变得更加灵活呢?这时候我们就用到回调函数的知识了,我们可以定义一个函数,这个函数需要两个int型参数,函数内部实现代码是将两个整形数字做比较,将比较结果的bool值作为函数的返回值返回出来,以大于被比较数字的情况为例:
1 | BOOL compareGreater(int number, int compareNumber) { |
同理,小于被比较的数字函数定义如下:
1 | BOOL compareLess(int number, int compareNumber) { |
接下来,我们可以将这个函数作为compareNumberFunction的一个参数进行传递(没错,函数可以作为参数),那么我们就需要一个函数指针获取函数的地址,从而在compareNumberFunction内部进行对函数的调用,于是,compareNumberFunction函数的定义变成了这样:
1 | void compareNumberFunction(int *numberArray, int count, int compareNumber, BOOL (*p)(int, int)) { |
具体使用时代吗如下:
1 | int main() { |
根据上述案例,我们可以得出结论:函数回调本质为函数指针作为函数参数,函数调用时传入函数地址,这使我们的代码变得更加灵活,可复用性更强。
函数指针作为函数返回值
没错,既然函数指针可以作为参数,自然也可以作为返回值。再接着上案例。
需求:定义一个函数,通过传入功能的名称获取到对应的函数。
| 功能名(name) | 调用函数(function) |
|---|---|
| “max” | maxValue() |
| “min” | minValue() |
当前我们需要定义一个叫做findFunction的函数,这个函数传入一个字符串之后会返回一个 int (*)(int, int)类型的函数指针,那么我们这个函数的声明是不是可以写成这样呢?
1 | int (*)(int, int) findFunction(char *); |
这看起来很符合我们的理解,然而,这并不正确,编译器无法识别两个完全并行的包含形参的括号(int, int)和(char *),真正的形式其实是这样:
1 | int (*findFunction(char *))(int, int); |
这种声明从外观上看更像是脸滚键盘出来的结果,现在让我们来逐步的分析一下这个声明的组成步骤:
1 | findFunction 是一个标识符 |
最终代码演变成了这样:
1 | // 重定义函数指针类型 |
到了这里,函数指针的基础内容已经结束了,有的同学还有可能困惑,为什么我要以函数去获取函数呢,直接使用maxValue和minValue不就好了么,其实在以后的编程过程中,很有可能maxValue和minValue被封装了起来,类的外部是不能直接使用的,那么我们就需要这种方式,如果你学习了Objective-C你会发现,所有的方法调用的实现原理都是如此。
仿函数
explicit关键字
在C++中,explicit关键字用来修饰类的构造函数,被修饰的构造函数的类,不能发生相应的隐式类型转换,只能以显示的方式进行类型转换。
注意事项:
1、explicit关键字只能用于类内部的构造函数声明上;
2、explicit关键字作用于单个参数(或者除了第一个参数外其余参数都有缺省值的多参构造函数)的构造函数;
restrict 关键字
restrict 是 C 的关键字(出现于 C99 标准),用在指针声明中,C++ 的标准中没有 restrict ,但是现代的主流编译器都保留了对 restrict 的支持,如 VC++, GCC, Clang, Icc 等,不同编译器的书写形式或许不同,可能是 restrict, restrict, __restrict 等.
restrict 的含义是由编程者向编译器声明,在这个指针的生命周期中,只有这个指针本身或者直接由它产生的指针(如 ptr + 1)能够用来访问该指针指向的对象.他的作用是限制指针别名,帮助编译器做优化.如果该指针与另外一个指针指向同一对象,那么结果是未定义的.
例如在下列代码中
1 | int add (int* a, int* b) |
这个函数直观的作用便是将 a 和 b 指向的 int 对象赋值为 10 和 12, 然后返回他们两个的和,可以看出最后 return *a + *b 这条语句中是不需要的访问内存单元的,a 中一定是 10, b 中一定是 12, 所以编译器可以在这里做优化直接返回 22.
但是如果 a 和 b 指向的是同一个 int 对象呢? 这时编译器就不应该做优化,实际上编译器的优化策略是保守的,当无法判断这里能不能优化时,便不做优化,所以可得如下汇编代码,这已经是编译器在已知信息下所能做的最好的优化,优化等级是 -O3
1 | add(int*, int*): |
但是如果加上 restrict 修饰(编译器 GCC),代码如下
1 | int add (int* __restrict__ a, int* __restrict__ b) |
编译器已经得知 a, b 两指针不会指向同一单元(此点应由编程者保证),所以在这里会减少一次内存的访问,可以得到如下的汇编代码
1 | add(int*, int*): |
可见少了一条内存访问的指令
void *
指向void的指针是“通用”指针类型;
可以将void *转换为任何其他指针类型,而无需显式强制转换。
您不能解引用void *或对其进行指针运算; 您必须先将其转换为指向完整数据类型的指针
1 | int thread_params = 5; |
向上/下强制转换
将派生类引用或指针转换为基类引用或指针被称为向上强制转换。
将基类引用或指针转换为派生类引用或指针被称为向下强制转换。
如果不使用显示类型转换,向下强制转换是不允许的,因为is-a关系是不可逆的。
比如香蕉是水果,但是水果不是香蕉。派生类香蕉可以新增数据成员,因此这些数据成员不能应用于基类水果,比如香蕉中有黄色,但是不是所有水果都是黄色的。
STL
STL有六种序列容器类型:
- 1 Vector:相当于一个数组,在内存中分配一块连续的内存空间进行存储;STL内部实现时首先分配一个非常大的内存空间预备进行存储(可以通过capacity()函数返回其大小)
- 2 List:双向链表
- 3 Deque:双端队列
人们习惯上把程序员分三个等级,知其然,知其所以然,造其所以然
hash
hash也称散列,哈希。基本原理就是将任意长度的输入变成固定长度的输出。这个映射的规则就是哈希算法,而原始数据经过映射形成的二进制字符串就是哈希值。开发中的MD5和SHA都是历史悠久的哈希算法。
1 | echo md5("This is a test md5!"); |
hash的优点
1 不能从hash值反向推导出原始的数据
2 输入数据的微小变化会得到完全不同的hash值,相同的数据会得到相同的值
3 哈希算法的执行效率要高效,长的文本也能快速的计算出哈希值
4 哈希算法的冲突概率要小
由于哈希的原理就是将输入空间的值映射成hash空间内,而hash值的空间远小于输入的空间,根据鸽笼原理,一定会存在不同的输入被映射成相同输出的情况。
hash碰撞的解决方案
前面提到了哈希算法是一定会有碰撞的,那么如果我们遇到了hash冲突需要解决的时候该怎么处理呢?常用的方法就是 链地址法和开放地址法。
开放地址法就是构造一个M的数组保存N个键值对(M>N)。我们需要依靠数组中的空位解决碰撞冲突。基于这种策略的所以方法统称为“开放地址法”。线性探测法,就是比较常见的一种实现方式。它的核心思想是当冲突发生时,顺序查看表的下一个单元,直到找到一个空单元或查遍全表。只要散列表足够大,空的散列地址总能找到。
Array
就是个数组,不能扩充。
Vector
vector的增长是2倍2倍的扩充容量(capacity),注意这里不是在原来的基础上成长:它是在另外的地方找一个两倍的空间然后一个一个元素搬过去。。。。。。所以vector的size是元素的数量,但是capacity却是扩充 的2的倍数。补充:容器的data指的是在内存中首元素的地址。
vector初始化:
vector
vector
1 | int aa[8] = {9,6,2,8,4,3,7,5}; |
vector 要删除中间某个元素的时候不要直接用 erase,可以将其置换到最后面然后进行pop_back
List
list与vector不同,它是采用的环状双向链表
某些容器(如list)自带sort,这个要比全局的sort要快


c++中箭头运算符->,相当于把解引用和成员访问符两个操作符结合在一起,换句话说,
p->func()和(*p).func()所表示的意思一样。
地址->一个东西 ite去解引用了ite这个地址
&(ite)又取回来这个地址
std::list::splice 详解
splice 方法将 list 的元素进行拼接合并,原理是改变结点指针的指向,属于常数的复杂度。这个方法是 std::list 特有的,它不需要复制拷贝,直接对同类型的 list 中的节点的指针进行操作。
list 容器底层实现是一个带头结点的双向链表 double linked list。由于 list 每个节点是单独的,所以 list 在随机插入和随机删除都是 O (1) 的复杂度。在 list 中移动数据或者两个 list 之间移动数据的时候,直接把节点摘下来,接入到新的位置就可以了,非常高效。
splice 方法有三种声明 / 作用 / 复杂度:
- entire list:
1
void splice ( iterator pos, list& other );
- 将 list `other` 中的元素全都移到 caller container 的 position 处
- **复杂度: Constant**- single element:
1
void splice ( iterator pos, list& other, iterator it );
- 仅将 list `other` 中的由迭代器 it 指向的元素移到 caller container 的 position 处
- **复杂度: Constant**- element range:
1
void splice ( iterator pos, list& other, iterator first, iterator last );
- list `other` 的迭代器区间 $[\mathrm {first}, \mathrm {last})$ 中的元素移动到 caller container 的 position 处
- **复杂度: Constant if `other` refers to the same object as `\*this`, otherwise linear in `std::distance(first, last)`.** [1](https://cakebytheoceanluo.github.io/2020/04/19/std-list-splice/#fn1)caller container := 调用者容器
由此可见,这个方法总是将 list other 中元素移动 (剪切) 到 caller container 中。
Deque
分段连续,类似于二维指针:由一个指针指向一个缓冲区


这里:node指向deque的控制大脑,first指向某一段的开头,last指向某一段的结尾,前闭后开区间,cur指向当前的这一段里面的节点。当走到头时,会由node进行段的切换;
控制中心是一个vector。如果你想在前面插入的话,且前面空间不够了,你依旧也是需要开辟一个2倍原来空间的控制中心区域一个一个的拷贝构造一下。但是它很狡猾的拷贝到2倍区域的中段来,这样可以让首尾控制中心的扩充更为均衡一些;
start与finish指向的是deque中所有元素的首跟尾;



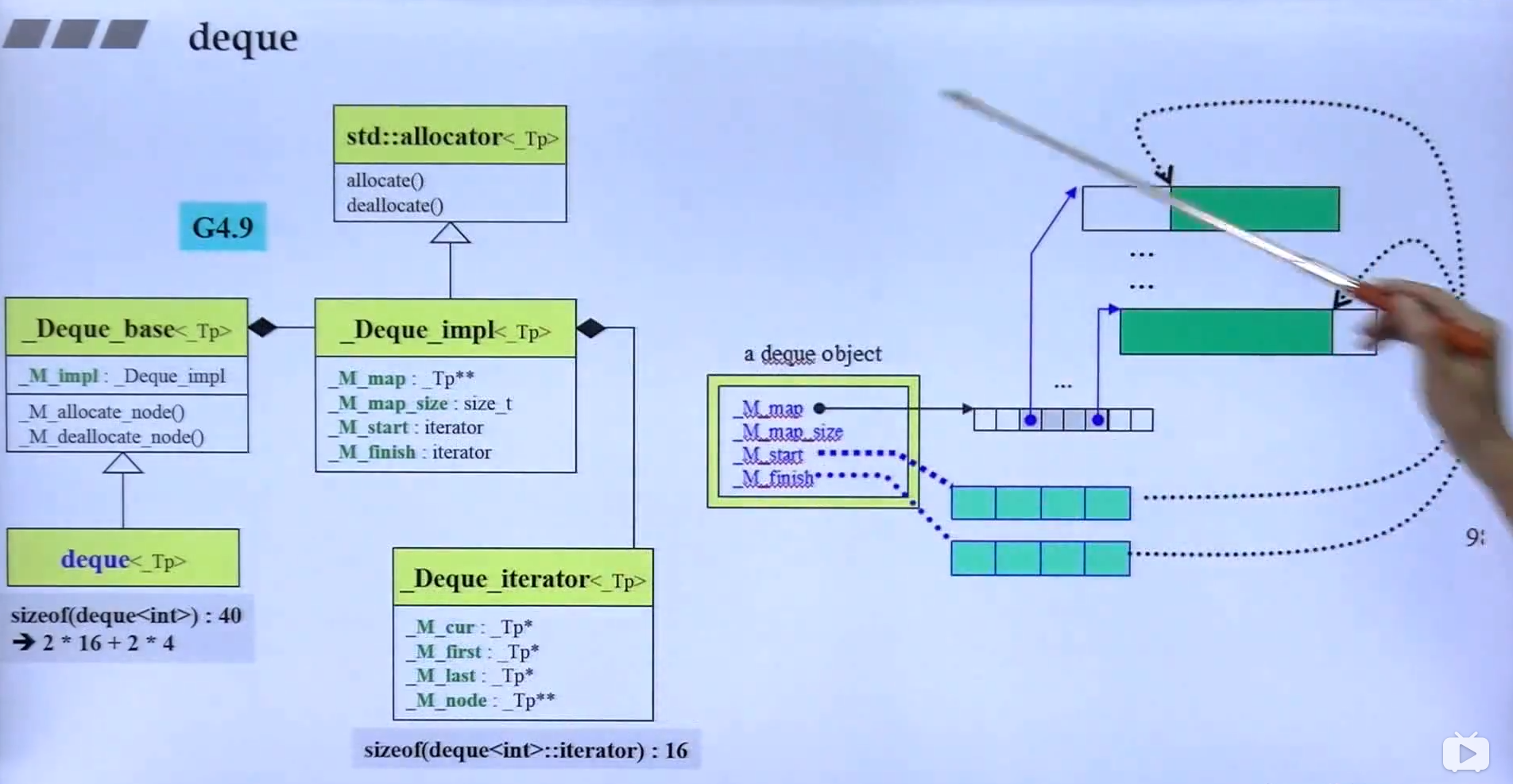


Map
multimap<key,value>//multi允许重复
snprintf(buf,10,”%d”,rand());//如果格式化后的字符串长度 >= size,则只将其中的(size-1)个字符复制到str中,并给其后添加一个字符串结束符(‘\0’),返回值为欲写入的字符串长度
1 |
|
c.insert(pair<long,string>(i,buf))
- multimap不可以用[作Insertion,map却可以,注意重复与不重复.
OOP:&GP:Generic Programming
Object-Oriented-Programming
GP 可以使得两个团队可以专注于闭门造车
OOP相当于菜谱(数据相当于原材料,方法相当于烹饪步骤)
标准库用的全局的::sort排序需要的是RandomAccessIterator,随机的迭代器,而list不能随意的像数组那样一下子蹦5个单元,所以List不能使用全局的::sort排序。
Template
类模板与函数模板


类模板如果不进行
但是函数模板就不一样了,因为编译器可以进行类型推导,从r1那个Stone r1就可以推出T的类型,进而重载Stone类的<操作符。
1 | template<class T>和下面相同 |
泛化与特化
- 类模板中我可以通过T来形成各种各样的类的蓝图。但是如果你是一种特定的类型比如int,我可以提供给你一种更为有效的做法,这就叫做特化。
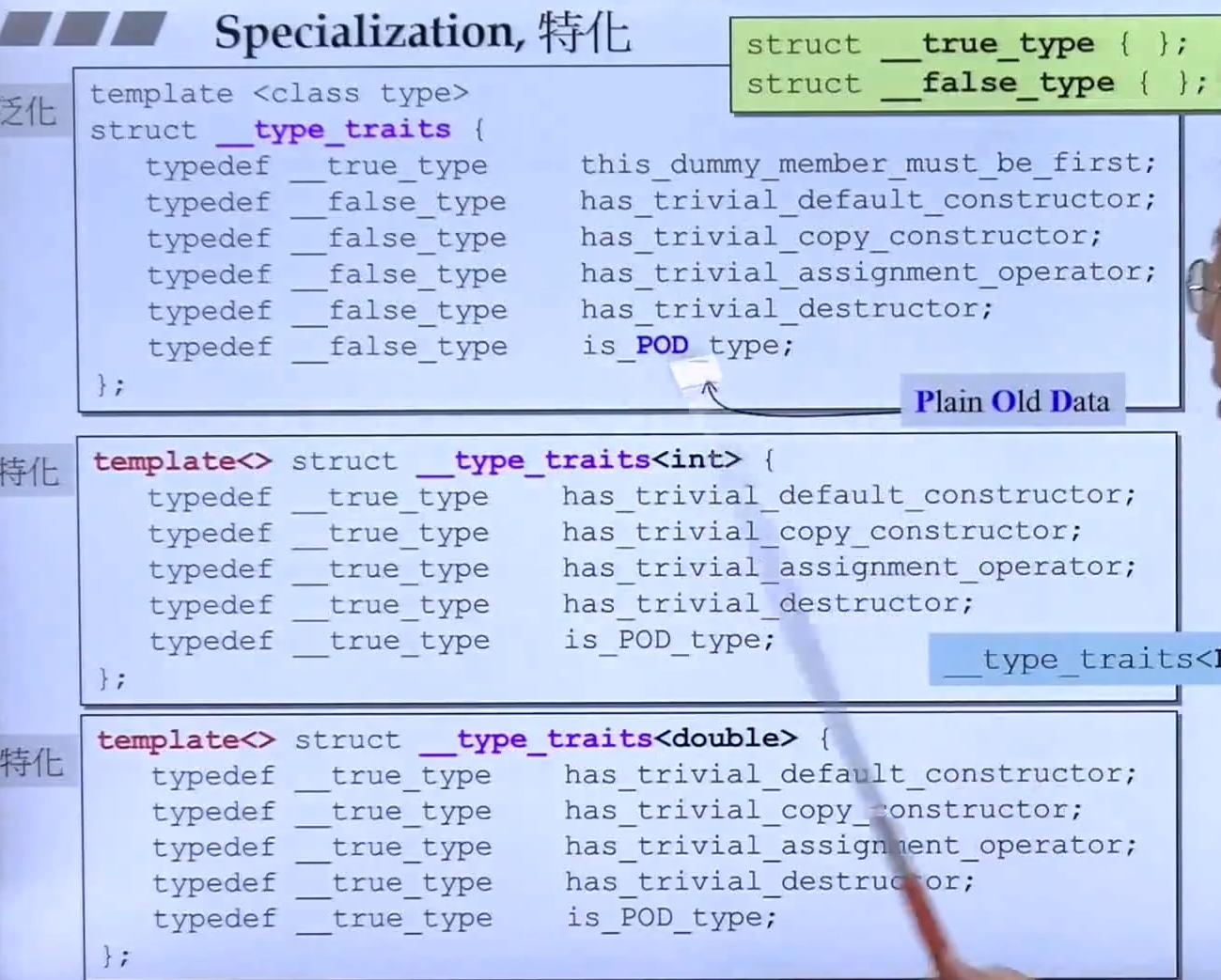
template<>有时候是__STL_TEMPLATE_NULL
以上是FULL 特化,还有偏特化 Partial Specialization

traits 萃取
萃取,特征,一种人为制造的萃取机器:我丢给它一些东西,它可以萃取出我想要的特征
STL 中,容器和算法是分开的,两者之间靠的是迭代器进行连接。算法是如何从迭代器中知道元素的类型的呢?靠的就是萃取。。。
简单来说,如果我们封装了一个算法,这个算法可能会由于输入数据类型的不同导致算法内部处理逻辑的不同(比如说传入的是int类型我们做一种操作,而传入的是double类型我们将进行另外一种操作),而我们并不想由于这种原因修改算法的封装时,Traits就派上用场了,它可以帮我们很方便的实现功能,而又不破坏函数的封装。
迭代器所指对象的类型,称为该迭代器的 value_type。我们来简单模拟一个迭代器 traits classes 的实现。
1 | // 主模板 不使用模板参数列表--》 my_iterator_traits<Iter T> |
my_iterator_traits 其实就是个类模板,其中包含一个类型的声明。有上面 typename 的基础,相信大家不难理解 typedef typename IterT::value_type value_type; 的含义:将迭代器的value_type 通过 typedef 为 value_type。
为什么要在typedef后面加上typename关键字?
之所以使用 typename 是由于C++默认使用 :: 访问的名字不是类型
原因:
实际上,模板类型在实例化之前,编译器并不知道
vector<T>::size_type是什么东西,事实上一共有三种可能:静态数据成员
静态成员函数
嵌套类型那么此时
typename的作用就在此时体现出来了——定义就不再模棱两可。
typedef创建了存在类型的别名,而typename告诉编译器std::vector<T>::size_type是一个类型而不是一个成员。默认情况下,C++ 语言假定通过作用域运算符访问的名字不是类型。因此,如果我们希望使用一个模板类型参数的类型成员,就必须显式告诉编译器该名字是一个类型。我们通过使用关键字 typename 来实现这一点:
我们来解释 my_iterator_traits<vector
vector
接着,my_iterator_traits<vector
对 double 类型的 vector 迭代器的萃取也是类似的过程。
而 my_iterator_traits<char*>::value_type 则使用 my_iterator_traits 的偏特化版本,直接返回 char 类型。
由此看来,通过 my_iterator_traits ,我们正确萃取出了迭代器所指元素的类型。
总结一下我们设计并实现一个 traits class 的过程:
1)确认若干我们希望将来可取得的类型相关信息,例如,对于上面的迭代器,我们希望取得迭代器所指元素的类型;
2)为该信息选择一个名称,例如,上面我们起名为 value_type;
3)提供一个 template 和一组特化版本(例如,我们上面的 my_iterator_traits),内容包含我们希望支持的类型相关信息。
RB_Tree
关联式容器。红黑树。散列表。
- 红黑树的++操作类似于中序遍历,它是按照元素增大的顺序进行遍历的
- 我们不应该使用红黑树的迭代器进行修改值的操作:因为会破坏严谨的红黑树的平衡
C++编程技巧Tips
定义变量的时候可以不用缩进然后避免在开头集中定义,又方便查找—-侯捷
抽空研究一下快速排序,红黑树
::find是循序查找,
关键字typedef在编译阶段有效,由于是在编译阶段,因此typedef有类型检查的功能。
#define则是宏定义,发生在预处理阶段,也就是编译之前,它只进行简单而机械的字符串替换,而不进行任何检查。
typedef用来定义类型的别名,定义与平台无关的数据类型,与struct的结合使用等。
#define不只是可以为类型取别名,还可以定义常量、变量、编译开关等。
#define没有作用域的限制,只要是之前预定义过的宏,在以后的程序中都可以使用。
而typedef有自己的作用域。
拷贝构造
拷贝构造函数必须以引用的方式传递参数。这是因为,在值传递的方式传递给一个函数的时候,会调用拷贝构造函数生成函数的实参。如果拷贝构造函数的参数仍然是以值的方式,就会无限循环的调用下去,直到函数的栈溢出。
拷贝赋值
首先返回值得是一个引用哈,是为了:p1 = p2 = p3的这种递归赋值的情况;
然后注意形参是一个常量引用,成员函数后面加不加const呢?由于要修改this类的成员变量,所以不能加const
进入函数要先判断this指针的p1 = p1这种情况;
最后要把this类的原指针指向的内存释放一下,防止内存泄露
delete []m_pData; m_pData = nullptr;
1 | CMyString& CMyString::operator = (const CMyString& str) |
注意事项
1、new 关键字创建对象时 对于内置类型:加括号会初始化,不加括号不初始化;对于自定义类型,都会调用默认构造函数,加不加括号没区别。