本文主要关于数据结构,数据结构是指数据存储的组织方式。大致上分为线性表、栈(Stack)、队列、树(tree)、图(Map)。
具体涉及算法如下:
dfs
463.岛屿的周长
695.岛屿的最大面积
200.岛屿的数量 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 class Solution {private : void dfs (vector <vector <char >>& grid, int r, int c) int nr = grid.size(); int nc = grid[0 ].size(); grid[r][c] = '0' ; if (r - 1 >= 0 && grid[r-1 ][c] == '1' ) dfs(grid, r - 1 , c); if (r + 1 < nr && grid[r+1 ][c] == '1' ) dfs(grid, r + 1 , c); if (c - 1 >= 0 && grid[r][c-1 ] == '1' ) dfs(grid, r, c - 1 ); if (c + 1 < nc && grid[r][c+1 ] == '1' ) dfs(grid, r, c + 1 ); } public : int numIslands (vector <vector <char >>& grid) int nr = grid.size(); if (!nr) return 0 ; int nc = grid[0 ].size(); int num_islands = 0 ; for (int r = 0 ; r < nr; ++r) { for (int c = 0 ; c < nc; ++c) { if (grid[r][c] == '1' ) { ++num_islands; dfs(grid, r, c); } } } return num_islands; } };
694.不同岛屿的数量
305.岛屿数量II
773. 滑动谜题
链表
24. 两两交换链表中的节点
25. K 个一组翻转链表
92. 反转链表 II
160. 相交链表
2.两数之和
剑指 Offer 24. 反转链表
面试题 02.05. 链表求和
动态规划
二分
排序数组,平方后,数组当中有多少不同的数字(相同算一个)
一个数据先递增再递减,找出数组不重复的个数,比如 [1, 3, 9, 1],结果为3,不能使用额外空间,复杂度o(n)
递增数组,找出和为k的数对
给出一个数组nums,一个值k,找出数组中的两个下标 i,j 使得 nums[i] + nums[j] = k
滑动窗口
3.无重复字符的最长子串
字符串的排列
排序
插入排序
冒泡排序
快速排序
三路快排
归并排序
sum问题
两数之和
三数之和
nSum
大数之和
栈
71.简化路径
哈希表及Union-Find
128.最长连续序列
一个无序数组,从小到大找到第一个缺的数,比如[8 2 4 3 6 9 7 11 12],第一个缺的就是5
31.下一个排列
55.跳跃游戏
AB两个排序数组,原地合并数组。(A当中穿插一些无效数字怎么处理?)
树
手撕二叉树操作
剑指 Offer 68 - I. 二叉搜索树的最近公共祖先
剑指 Offer 68 - II. 二叉树的最近公共祖先
337. 打家劫舍 III
100.相同的树
前中后非递归遍历及递归遍历
剑指 Offer 54. 二叉搜索树的第k大节点
222. 完全二叉树的节点个数
257. 二叉树的所有路径
129. 求根到叶子节点数字之和
最小路径和
124. 二叉树中的最大路径和
112.路径总和
113.路径总和 II
剑指 Offer 07. 重建二叉树
手撕算法相关
手撕lru
手撕memcpy、strcpy、strnpy、strlen、strstr、strcat、strcmp
手撕智能指针
手撕kmp
手撕单例
手撕堆
手撕两种线程安全的单例模式
scoped_ptr autpo_ptr unique_ptr
shared_ptr
首先看一下什么是排列,什么是组合?
排列和组合的本质区别是:决策的顺序对结果有没有影响?
你一听排列,首先想到的就是排队,你站队头和站队尾那是两种排列;
例如 3 2 1 和 1 2 3 是两种排列
3!*2! *1!
而组合对顺序无感,所以你站队头站队尾都是一种组合;
例如 3 2 1 和 1 2 3 是一种组合
(3!* 2! * 1!) / (3 * 2)
“排列”类型问题和“子集、组合”问题不同在于:“排列”问题使用used数组来标识选择列表,而“子集、组合”问题则使用start参数
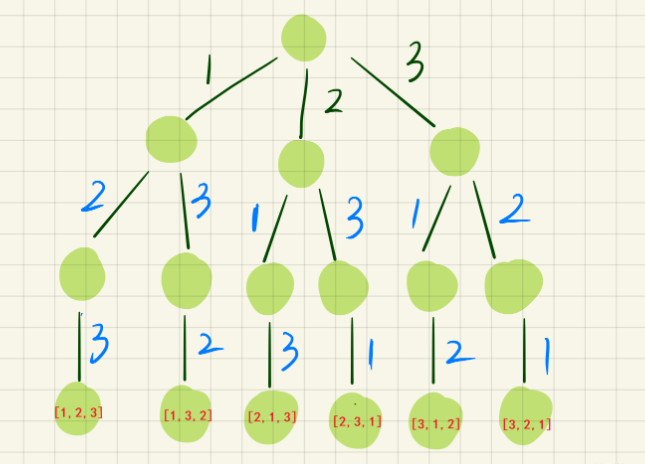
排列类问题 给定一个 没有重复 数字的序列,返回其所有可能的全排列。
首先,我们固定1,然后只有2、3可选:如果选2,那就只剩3可选,得出结果[1,2,3];如果选3,那就只剩2可选,得出结果[1,3,2]。再来,如果固定2,那么只有1,3可选:如果选1,那就只剩3,得出结果[2,1,3]…..
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 void backtrack (vector <int >& nums,vector <bool >&used,vector <int >& path) if (path.size()==nums.size()) { res.push_back(path); return ; } for (int i=0 ;i<nums.size();i++) { if (!used[i]) { path.push_back(nums[i]); used[i]=true ; backtrack(nums,used,path); used[i]=false ; path.pop_back(); } } } 作者:show-me-the-code-2 链接:https: 来源:力扣(LeetCode) 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
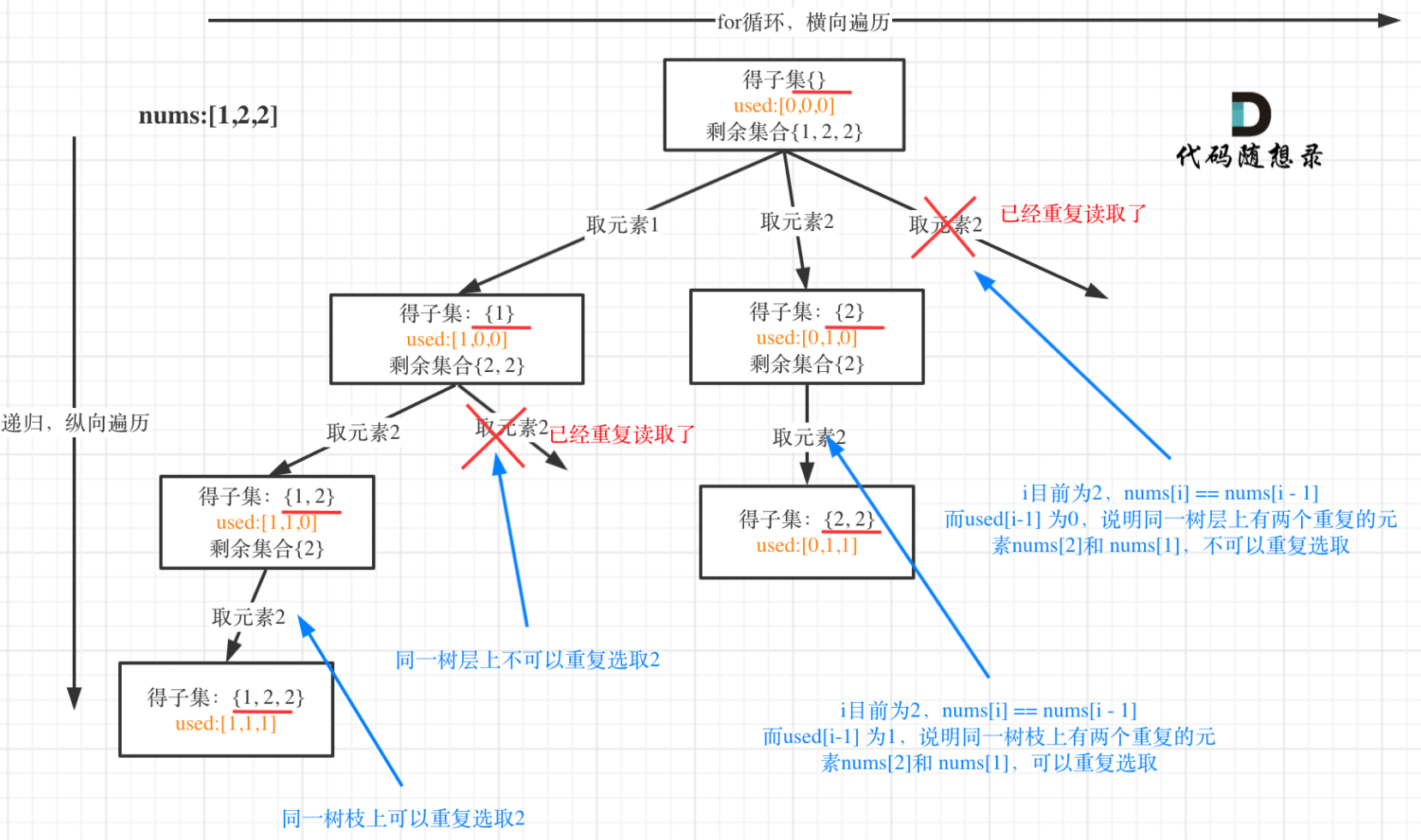
给定一个可包含重复数字 的序列,返回所有不重复 的全排列。
有了前面“子集、组合”问题的判重经验,同样首先要对题目中给出的nums数组排序,让重复的元素并列排在一起,在
if(i>start&&nums[i] == nums[i-1]),基础上修改为if(i>0&&nums[i]==nums[i-1]&&!used[i-1]),语义为:当i可以选第一个元素之后的元素时(因为如果i=0,即只有一个元素,哪来的重复?有重复即说明起码有两个元素或以上,i>0),然后判断当前元素是否和上一个元素相同?如果相同,再判断上一个元素是否能用?如果三个条件都满足,那么该分支一定是重复的,应该剪去
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 void backtrack (vector <int >& nums,vector <bool >&used,vector <int >& path) if (path.size()==nums.size()) { res.push_back(path); return ; } for (int i=0 ;i<nums.size();i++) { if (!used[i]) { if (i>0 &&nums[i]==nums[i-1 ]&&!used[i-1 ]) continue ; path.push_back(nums[i]); used[i]=true ; backtrack(nums,used,path); used[i]=false ; path.pop_back(); } } } 作者:show-me-the-code-2 链接:https: 来源:力扣(LeetCode) 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
组合类问题 正好最近在担任组合数学的助教,刷的题目很多都跟组合有关。遂总结一下:
77.给定两个整数 n 和 k,返回 1 … n 中所有可能的 k 个数的组合。
示例:
输入: n = 4, k = 2
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 class Solution {private : vector <vector <int >> result; vector <int > path; void backtracking (int n, int k, int startIndex) if (path.size() == k) { result.push_back(path); return ; } for (int i = startIndex; i <= n; i++) { path.push_back(i); backtracking(n, k, i + 1 ); path.pop_back(); } } public : vector <vector <int >> combine(int n, int k) { backtracking(n, k, 1 ); return result; } };
剪枝优化
在遍历的过程中如下代码 :
for (int i = startIndex; i <= n; i++)
来举一个例子,n = 4, k = 4的话,那么从2开始的遍历都没有意义了。
已经选择的元素个数:path.size();
要选择的元素个数 : k - path.size();
在集合n中开始选择的起始位置 : n - (k - path.size());
因为起始位置是从1开始的,而且代码里是n <= 起始位置,所以 集合n中开始选择的起始位置 : n - (k - path.size()) + 1;
所以优化之后是:
for (int i = startIndex; i <= n - (k - path.size()) + 1; i++)
39.给定一个无重复元素的数组 candidates 和一个目标数 target ,找出 candidates 中所有可以使数字和为 target 的组合。
candidates 中的数字可以无限制重复被选取。
输入:candidates = [2,3,6,7], target = 7,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 class Solution {private : vector <vector <int >> result; vector <int > path; void backtracking (vector <int >& candidates, int target, int sum, int startIndex) if (sum > target) { return ; } if (sum == target) { result.push_back(path); return ; } for (int i = startIndex; i < candidates.size(); i++) { sum += candidates[i]; path.push_back(candidates[i]); backtracking(candidates, target, sum, i); sum -= candidates[i]; path.pop_back(); } } public : vector <vector <int >> combinationSum(vector <int >& candidates, int target) { backtracking(candidates, target, 0 , 0 ); return result; } };
手写:子集
很多同学在去重的问题上想不明白,其实很多题解也没有讲清楚,反正代码是能过的,感觉是那么回事,稀里糊涂的先把题目过了。
这个去重为什么很难理解呢,所谓去重,其实就是使用过的元素不能重复选取。 这么一说好像很简单!
都知道组合问题可以抽象为树形结构,那么“使用过”在这个树形结构上是有两个维度的,一个维度是同一树枝上使用过,一个维度是同一树层上使用过。没有理解这两个层面上的“使用过” 是造成大家没有彻底理解去重的根本原因。
那么问题来了,我们是要同一树层上使用过,还是统一树枝上使用过呢?
回看一下题目,元素在同一个组合内是可以重复的,怎么重复都没事,但两个组合不能相同。
所以我们要去重的是同一树层上的“使用过”,同一树枝上的都是一个组合里的元素,不用去重。
剧透一下,后期要讲解的排列问题里去重也是这个套路,所以理解“树层去重”和“树枝去重”非常重要。
用示例中的[1, 2, 2] 来举例,如图所示: (注意去重需要先对集合排序)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 class Solution {public : vector <int > path; vector <vector <int >> result; void backtrack (vector <int >& nums, vector <bool >& used, int startIndex) result.push_back(path); for (int i = startIndex; i < nums.size(); ++i) { if (i > 0 && nums[i] == nums[i - 1 ] && used[i - 1 ] == false ) { continue ; } path.push_back(nums[i]); used[i] = true ; backtrack(nums, used, i + 1 ); used[i] = false ; path.pop_back(); } } vector <vector <int >> subsetsWithDup(vector <int >& nums) { path.clear(); result.clear(); vector <bool > used (nums.size(), false ) sort(nums.begin(), nums.end()); backtrack(nums, used, 0 ); return result; } };
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 class Solution {public : TreeNode* recoverFromPreorder (string S) { stack <TreeNode*> path; int pos = 0 ; while (pos < S.size()) { int level = 0 ; while (S[pos] == '-' ) { ++level; ++pos; } int value = 0 ; while (pos < S.size() && isdigit (S[pos])) { value = value * 10 + (S[pos] - '0' ); ++pos; } TreeNode* node = new TreeNode(value); if (level == path.size()) { if (!path.empty()) { path.top()->left = node; } } else { while (level != path.size()) { path.pop(); } path.top()->right = node; } path.push(node); } while (path.size() > 1 ) { path.pop(); } return path.top(); } };
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 class Solution {public : TreeNode* recoverFromPreorder (string str) { stack <TreeNode*> treeStack; TreeNode* root = nullptr ; int index = 0 ; int levl = 0 ; while (index < str.length()) { if (str[index] == '-' ) { levl++; index++; continue ; } int val = 0 ; while (index < str.length() && str[index] != '-' ) { val = val * 10 + (str[index] - '0' ); index++; } while (levl < treeStack.size() && treeStack.size() > 0 ) { treeStack.pop(); } TreeNode* tempNode = new TreeNode(val); if (treeStack.size() <= 0 ) { root = tempNode; treeStack.push(root); } else if (treeStack.top()->left == NULL ) { treeStack.top()->left = tempNode; treeStack.push(treeStack.top()->left); } else if (treeStack.top()->right == NULL ) { treeStack.top()->right = tempNode; treeStack.push(treeStack.top()->right); } levl = 0 ; } return root; } };
最长重复子数组记住,子序列默认不连续,子数组默认连续 注意子数组和子序列的区别 如果是子序列的话 递推公式就是 : dp[i][j] = max(dp[i-1][j-1]+(A[i-1] == B[j-1]?1:0),dp[i-1][j],dp[i][j-1]) 三个里面挑最大
输入:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 class Solution {public : int findLength (vector <int >& A, vector <int >& B) int n = A.size(), m = B.size(); vector <vector <int >> dp(n + 1 , vector <int >(m + 1 , 0 )); int ans = 0 ; for (int i = 1 ; i <= n; ++i) { for (int j = 1 ; j <= m; ++j) { dp[i][j] = A[i-1 ] == B[j-1 ] ? dp[i - 1 ][j - 1 ] + 1 : 0 ; ans = max(ans, dp[i][j]); } } return ans; } }; ------------ class Solution {public : int findLength (vector <int >& A, vector <int >& B) int n = A.size(), m = B.size(); vector <vector <int >> dp(n + 1 , vector <int >(m + 1 , 0 )); int ans = 0 ; for (int i = 0 ; i < n; ++i) { for (int j = 0 ; j < m; ++j) { dp[i+1 ][j+1 ] = A[i] == B[j] ? dp[i][j] + 1 : 0 ; ans = max(ans, dp[i+1 ][j+1 ]); } } return ans; } };
二叉树C++ 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 #include <iostream> using namespace std;typedef struct BinaryTree { BinaryTree *Lchild; BinaryTree *Rchild; int data; }BinaryTree; int Construct (BinaryTree **T) int ch; cin >> ch; if (ch == -1 ) { *T = NULL ; return 0 ; } else { *T = (BinaryTree *)malloc (sizeof if (T == NULL ) cout << "malloc failed!" << endl; else { (*T)->data = ch; cout << "请输入" << ch << "的左子节点:" << endl; Construct (&((*T)->Lchild)); Construct (&((*T)->Rchild)); } } } int main (int argc, char **argv) cout << "BinaryTree Construct Stage..." << endl; BinaryTree *Btree; cout << "请输入二叉树第一个节点的值,-1代表叶子节点..." << endl; Construct (&Btree); return 0 ; }
BTree本来是一个指向BinaryTree的指针,
因为有小伙伴问了,可否在构建二叉树传入的参数为一级地址。上述的方法是一定要传二级参数的,但是这里给出一个传一级参数的方法,小伙伴也可以通过对比两种方法,对二叉树的构建和传参方式有更深的理解。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 struct TreeNode* Create () { int val; scanf ("%d" , &val); struct TreeNode * root =malloc (sizeof (struct TreeNode*)); if (val <= 0 ) { return NULL ; } if (!root) { printf ("创建失败\n" ); } if (val > 0 ) { root->val = val; root->left = Create(); root->right = Create(); } return root; }
手写:字符串的排列 腾讯 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 class Solution {public : bool checkInclusion (string s1, string s2) int n = s1.length(), m = s2.length(); if (n > m) { return false ; } vector <int > cnt1 (26 ) , cnt2 (26 ) for (int i = 0 ; i < n; ++i) { ++cnt1[s1[i] - 'a' ]; ++cnt2[s2[i] - 'a' ]; } if (cnt1 == cnt2) { return true ; } for (int i = n; i < m; ++i) { ++cnt2[s2[i] - 'a' ]; --cnt2[s2[i - n] - 'a' ]; if (cnt1 == cnt2) { return true ; } } return false ; } };
手写: rand5实现rand3和rand8 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 int Rand3 () int x; do { x = Rand5(); } while (x >= 3 ); return x; } int Rand5 () int x; do { x = Rand3() * 3 + Rand3(); } while (x >= 5 ); return x; } int Rand7 () int x; do { x = Rand5() * 5 + Rand5(); } while (x >= 21 ); return x % 7 ; } int rand_10 () int x = 0 ; do { x = 7 * (rand7() - 1 ) + rand7(); }while (x > 40 ); return x % 10 + 1 ; }
手写:判断回文链表 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 class Solution {public : bool isPalindrome (ListNode* head) ListNode* fast = head; ListNode* slow = head; if (head == nullptr ) return true ; while (fast->next != nullptr && fast->next->next != nullptr ){ slow = slow->next; fast = fast->next->next; } ListNode* after = slow->next; ListNode* prev = NULL ; while (after != nullptr ){ ListNode* temp = after->next; after->next = prev; prev = after; after = temp; } while (prev != nullptr ){ if (head->val == prev->val){ head = head->next; prev = prev->next; } else return false ; } return true ; } };
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 class Solution {public : int findMin (vector <int >& nums) int low = 0 ; int high = nums.size() - 1 ; while (low < high) { int pivot = low + (high - low) / 2 ; if (nums[pivot] < nums[high]) { high = pivot; } else { low = pivot + 1 ; } } return nums[low]; } }; while (low < high){ int mid = (high+low)/2 ; if (nums[mid] < nums[high]) { high = mid; } else { low = mid+1 ; } } return nums[low];
199周赛
房间中有 n 个灯泡,编号从 0 到 n-1 ,自左向右排成一行。最开始的时候,所有的灯泡都是 关 着的。
请你设法使得灯泡的开关状态和 target 描述的状态一致,其中 target[i] 等于 1 第 i 个灯泡是开着的,等于 0 意味着第 i 个灯是关着的。
有一个开关可以用于翻转灯泡的状态,翻转操作定义如下:
选择当前配置下的任意一个灯泡(下标为 i )
返回达成 target 描述的状态所需的 最少 翻转次数。
聪明人一眼就看出这是找规律,可惜我不是聪明人!这道题就是找相邻两个字符不相同的个数,开头如果有0的话需要把开头这些0去除掉。
1 2 3 4 5 6 7 8 9 10 11 输入:target = "10111" 输出:3 解释:初始配置 "00000". 从第 3 个灯泡(下标为 2)开始翻转 "00000" -> "00111" 从第 1 个灯泡(下标为 0)开始翻转 "00111" -> "11000" 从第 2 个灯泡(下标为 1)开始翻转 "11000" -> "10111" 至少需要翻转 3 次才能达成 target 描述的状态 输入:target = "001011101" 输出:5
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 class Solution {public : int minFlips (string target) int count = 1 ; int i = 0 ; while (i < target.size() && target[i] == '0' ){ i++; } if (i == target.size()) return 0 ; for (; i < target.size() - 1 ; ++i){ if (target[i] != target[i+1 ] ){ count++; } } return count; } };
来看看大佬的做法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 class Solution {public : int minFlips (string target) int cur = 0 , ans = 0 ; for (char c : target) { int d = c - '0' ; if ((d ^ cur) == 1 ) { cur ^= 1 ; ans++; } } return ans; } };
手写:二叉搜索树和双向链表 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 class Solution {public : Node* treeToDoublyList (Node* root) { if (root == nullptr ) return nullptr ; dfs(root); head->left = pre; pre->right = head; return head; } private : Node *pre, *head; void dfs (Node* cur) if (cur == nullptr ) return ; dfs(cur->left); if (pre != nullptr ) pre->right = cur; else head = cur; cur->left = pre; pre = cur; dfs(cur->right); } }; 作者:jyd 链接:https: 来源:力扣(LeetCode) 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
前序遍历和中序遍历恢复二叉树 输入某二叉树的前序遍历和中序遍历的结果,请重建出该二叉树。假设输入的前序遍历和中序遍历的结果中都不含重复的数字。例如输入前序遍历序列{1,2,4,7,3,5,6,8}和中序遍历序列{4,7,2,1,5,3,8,6},则重建二叉树并返回。
手写:二叉树最近父节点 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 class Solution {public : unordered_map <TreeNode*, TreeNode*> fa; unordered_map <TreeNode*, bool > vis; TreeNode* lowestCommonAncestor (TreeNode* root, TreeNode* p, TreeNode* q) { fa[root] = nullptr ; dfs(root); while (p != nullptr ) { vis[p] = true ; p = fa[p]; } while (q != nullptr ) { if (vis[q]) return q; q = fa[q]; } return nullptr ; } void dfs (TreeNode* root) if (root == nullptr ) return ; fa[root->left] = root; fa[root->right] = root; dfs(root->left); dfs(root->right); } };
求一个字符串中连续出现次数最多的子串 例如字符串“abababc”,最多连续出现的为ab,连续出现三次。要和求一个字符串中的最长重复子串区分开来,还是上面的字符串,那么最长的重复子串为abab。两个题目的解法有些类似,都用到了后缀数组这个数据结构。求一个字符串中连续出现的次数最多的子串,首先生成后缀数组例如上面的字符串为:
1 2 3 4 5 6 7 abababc bababc ababc babc abc bc c
可以看出第一个后缀数组和第三个后缀数组的起始都为ab,第5个后缀数组也为ab。可以看出规律来,一个字符串s,如果第一次出现在后缀数组i的前面,那么如果它重复出现,下一次出现应该在第i+len(s)个后缀数组的前面。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 #include <iostream> #include <cstring> #include <utility> #include <string> #include <vector> using namespace std ;pair <int , string > fun (const string & str) vector <string > subs; int len = str.size(); for (int i = 0 ; i < len; i++) { subs.push_back(str.substr(i)); } int count = 1 ; int maxCount = 1 ; string sub; for (int i = 0 ; i < len; i++) { for (int j = i + 1 ; j < len; j++) { count = 1 ; if (subs[i].substr(0 , j - i) == subs[j].substr(0 , j - i)) { ++count; for (int k = j + j - i; k < len; k += j - i) { if (subs[i].substr(0 , j - i) == subs[k].substr(0 , j - i)) { ++count; } else { break ; } } if (count > maxCount) { maxCount = count; sub = subs[i].substr(0 , j - i); } } } } return make_pair (maxCount, sub); } int main () string str; pair <int , string > rs; while (cin >>str) { rs = fun(str); cout <<rs.second<<":" <<rs.first<<endl ; } return 0 ; }
i 慢指针,j快指针,当j和i不同时,交换i的下一个元素
1 2 3 4 5 6 7 8 9 10 11 12 13 14 class Solution {public : int removeDuplicates (vector <int >& nums) if (nums.size() == 0 ) return 0 ; int i = 0 ; for (int j = 0 ; j < nums.size(); ++j) { if (nums[j] != nums[i]) { i++; swap(nums[i], nums[j]); } } return i + 1 ; } };
手写:两栈实现队列 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 class MyQueue {public : MyQueue() { } void push (int x) A.push(x); } int pop () if (B.empty()) { while (!A.empty()) { B.push(A.top()); A.pop(); } } int ret = B.top(); B.pop(); return ret; } int peek () int ans = this ->pop(); B.push(ans); return ans; } bool empty () return A.empty() && B.empty(); } private : stack <int > A; stack <int > B; };
手写:不含有重复字符的最长子串 给定一个字符串,请你找出其中不含有重复字符的 最长子串 的长度。
示例 1:
输入: “abcabcbb”
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 class Solution {public : int lengthOfLongestSubstring (string s) if (s.size() == 0 ) return 0 ; unordered_set <char > lookup; int maxStr = 0 ; int left = 0 ; for (int i = 0 ; i < s.size(); i++){ while (lookup.find(s[i]) != lookup.end()){ lookup.erase(s[left]); left ++; } maxStr = max(maxStr,i-left+1 ); lookup.insert(s[i]); } return maxStr; } };
手写:最长回文子串 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 class Solution {public : string longestPalindrome (string s) int n = s.size(); vector <vector <int >> dp(n, vector <int >(n)); string ans; for (int l = 0 ; l < n; ++l) { for (int i = 0 ; i + l < n; ++i) { int j = i + l; if (l == 0 ) { dp[i][j] = 1 ; } else if (l == 1 ) { dp[i][j] = (s[i] == s[j]); } else { dp[i][j] = (s[i] == s[j] && dp[i + 1 ][j - 1 ]); } if (dp[i][j] && l + 1 > ans.size()) { ans = s.substr(i, l + 1 ); } } } return ans; } };
手写:反转单词 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 class Solution {public : string reverseWords (string s) vector <string > str; string temp; if (s.empty()) return "" ; for (int i = 0 ; i < s.size(); ++i) { if (s[i] != ' ' ) { temp += s[i]; } else if (temp.size() > 0 ) { str.push_back(temp); temp.clear(); } } str.push_back(temp); reverse(str.begin(), str.end()); string ret; for (int i = 0 ; i < str.size(); ++i) { if (str[i].size()) { ret += str[i]; if (i != str.size() - 1 ) ret += ' ' ; } } return ret; } };
手写:字符串相加 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 class Solution {public : string addStrings (string num1, string num2) int i = num1.length() - 1 , j = num2.length() - 1 , add = 0 ; string ans = "" ; while (i >= 0 || j >= 0 || add != 0 ) { int x = i >= 0 ? num1[i] - '0' : 0 ; int y = j >= 0 ? num2[j] - '0' : 0 ; int result = x + y + add; ans.push_back('0' + result % 10 ); add = result / 10 ; i -= 1 ; j -= 1 ; } reverse(ans.begin(), ans.end()); return ans; } };
手写:两数链表相加 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 class Solution {public : ListNode* addTwoNumbers (ListNode* l1, ListNode* l2) { ListNode* head = nullptr ; ListNode* tail = head; int carry = 0 ; while (l1 || l2) { int val_1 = l1? l1->val : 0 ; int val_2 = l2? l2->val : 0 ; int sum = val_1 + val_2 + carry; carry = sum / 10 ; if (head == nullptr ) { head = tail = new ListNode(sum % 10 ); } else { tail->next = new ListNode(sum % 10 ); tail = tail->next; } if (l1) l1 = l1->next; if (l2) l2 = l2->next; } if (carry) tail->next = new ListNode(carry); return head; } };
手写:LRU缓存 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 ## LRU缓存 ```c struct LinkNode { int key, value; LinkNode* prev; LinkNode* next; LinkNode() : key(0 ), value(0 ), prev(nullptr ), next(nullptr ) {} LinkNode(int _key, int _value) : key(_key), value(_value), prev(nullptr ), next(nullptr ) {} }; class LRUCache {private : unordered_map <int , LinkNode*> cache; LinkNode* head; LinkNode* tail; int size; int capacity; public : LRUCache(int _capacity) : capacity(_capacity), size(0 ) { head = new LinkNode(); tail = new LinkNode(); head->next = tail; tail->prev = head; } int get (int key) if (!cache.count(key)) { return -1 ; } LinkNode* node = cache[key]; moveToHead(node); return node->value; } void put (int key, int value) if (cache.count(key) == 0 ) { LinkNode* node = new LinkNode(key, value); cache[key] = node; node->next = head->next; node->prev = head; head->next->prev = node; head->next = node; ++size; if (size > capacity) { LinkNode* tailNode = tail->prev; tailNode->prev->next = tail; tailNode->next->prev = tailNode->prev; cache.erase(tailNode->key); delete tailNode; --size; } }else { LinkNode* node = cache[key]; node->value = value; moveToHead(node); } } void moveToHead (LinkNode* node) node->prev->next = node->next; node->next->prev = node->prev; head->next->prev = node; node->next = head->next; node->prev = head; head->next = node; } }; ``` class LRUCache {private : int cap; list <pair <int , int >>l; unordered_map <int , list <pair <int , int >>::iterator>mp; public : LRUCache(int capacity) { cap = capacity; } int get (int key) auto it = mp.find(key); if (it == mp.end()){ return -1 ; } auto target_pair_it = it->second; pair <int , int >np = {target_pair_it->first, target_pair_it->second}; l.erase(target_pair_it); l.push_front(np); mp[key] = l.begin(); return np.second; } void put (int key, int value) pair <int , int >np = {key, value}; auto it = mp.find(key); if (it == mp.end()){ l.push_front(np); mp[key] = l.begin(); }else { auto target_pair_it = it->second; l.erase(target_pair_it); l.push_front(np); mp[key] = l.begin(); } if (l.size() > cap){ auto remove_k = l.back().first; mp.erase(remove_k); l.pop_back(); } } }; 作者:fimm 链接:https: 来源:力扣(LeetCode) 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
手写:岛屿数量 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 class Solution {private : void dfs (vector <vector <char >>& grid, int r, int c) int nr = grid.size(); int nc = grid[0 ].size(); grid[r][c] = '0' ; if (r - 1 >= 0 && grid[r-1 ][c] == '1' ) dfs(grid, r - 1 , c); if (r + 1 < nr && grid[r+1 ][c] == '1' ) dfs(grid, r + 1 , c); if (c - 1 >= 0 && grid[r][c-1 ] == '1' ) dfs(grid, r, c - 1 ); if (c + 1 < nc && grid[r][c+1 ] == '1' ) dfs(grid, r, c + 1 ); } public : int numIslands (vector <vector <char >>& grid) int nr = grid.size(); if (!nr) return 0 ; int nc = grid[0 ].size(); int num_islands = 0 ; for (int r = 0 ; r < nr; ++r) { for (int c = 0 ; c < nc; ++c) { if (grid[r][c] == '1' ) { ++num_islands; dfs(grid, r, c); } } } return num_islands; } }; 作者:LeetCode 链接:https: 来源:力扣(LeetCode) 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
手写:找出数组中出现奇数次的元素( 给定一个含有n个元素的整型数组a,其中只有一个元素出现奇数次,找出这个元素。
因为对于任意一个数k,有k ^ k = 0,k ^ 0 = k,所以将a中所有元素进行异或,那么个数为偶数的元素异或后都变成了0,只留下了个数为奇数的那个元素。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 #include <stdio.h> int FindElementWithOddCount (int * a, int n) int r = a[0 ]; for (int i = 1 ; i < n; ++i) { r ^= a[i]; } return r; } int main () int array [] = { 1 , 2 , 2 , 3 , 3 , 4 , 1 }; int len = sizeof (array ) / sizeof (array [0 ]); printf ("%d\n" , FindElementWithOddCount(array , len)); getchar(); return 0 ; }
手写:实现strStr、KMP 实现字符串匹配算法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 class Solution {public : int strStr (string haystack, string needle) if (needle.empty()) return 0 ; int i=0 ,j=0 ; while (haystack[i]!='\0' &&needle[j]!='\0' ) { if (haystack[i]==needle[j]) { i++; j++; } else { i=i-j+1 ; j=0 ; } } if (needle[j]=='\0' ) return i-j; return -1 ; } }; 作者:Nanase_ 链接:https: 来源:力扣(LeetCode) 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
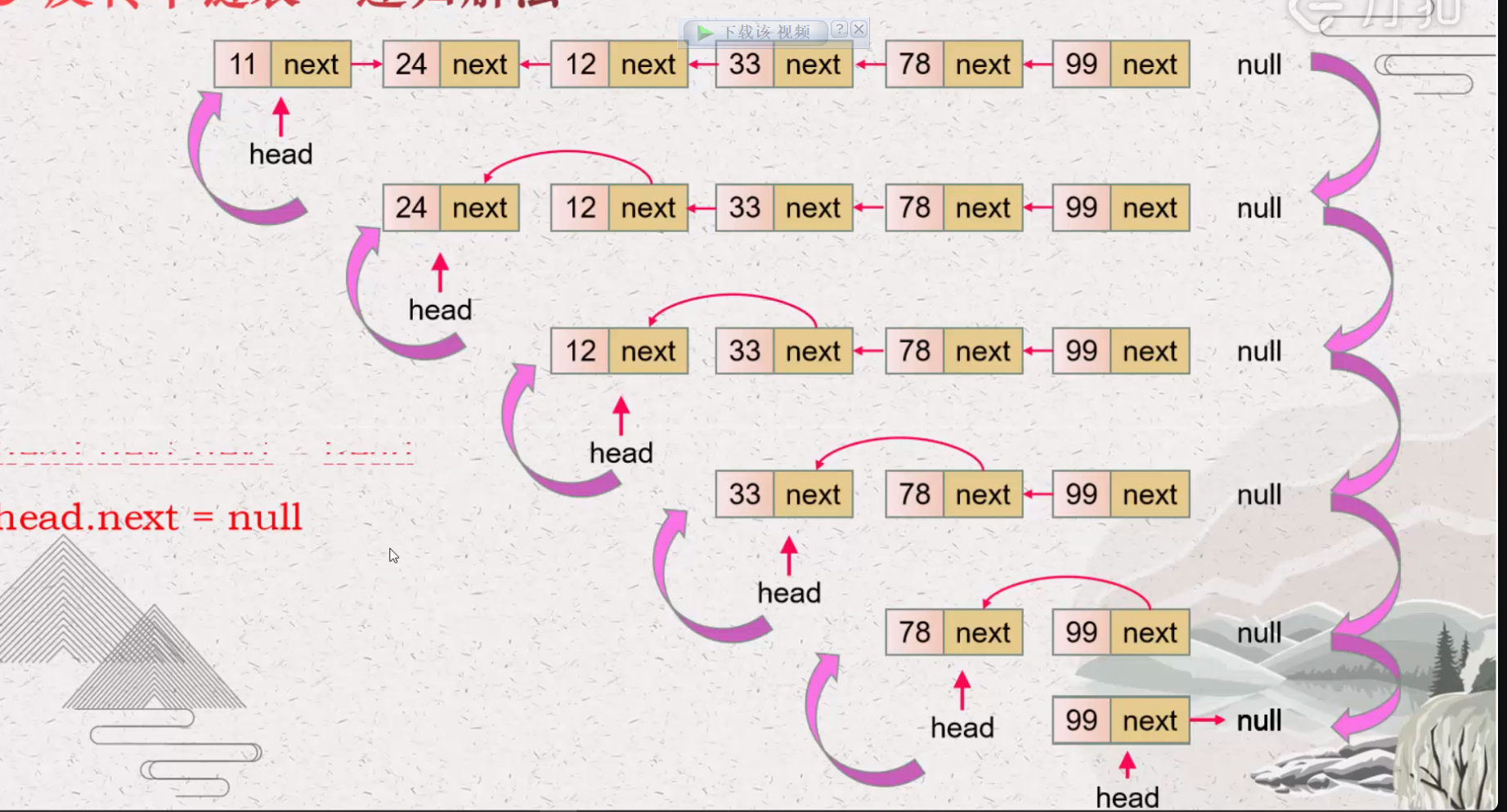
手写:反转链表 注意返回的是 prev 哈!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 class Solution {public : ListNode* reverseList (ListNode* head) { if (head == nullptr ) return nullptr ; ListNode* prev = nullptr ; while (head) { ListNode* temp = head->next; head->next = prev; prev = head; head = temp; } return prev; } };
递归版本:
1 2 3 4 5 6 7 8 9 10 public ListNode reverseList (ListNode head) if (head == null || head.next == null) { return head; } ListNode p = reverseList(head.next); head.next.next = head; head.next = null; return p; }
手写:反转链表2 反转某段区间内的链表,注意先找到left前一个元素prev_broke,再找到right后一个元素after_broke
反转区间后再连接上,这是我自己写的,特别注意一下区间个数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 ListNode* reverseBetween (ListNode* head, int left, int right) { if (head == nullptr ) return nullptr ; ListNode* dummyHead = new ListNode(0 , head); ListNode* prev_broke = dummyHead; ListNode* after_broke = dummyHead; for (int i = 0 ; i < left - 1 ; ++i) { prev_broke = prev_broke->next; } for (int i = 0 ; i <= right; ++i) { after_broke = after_broke->next; } ListNode* prev = nullptr ; ListNode* tail = prev_broke->next; for (int i = left; i <= right; ++i) { ListNode* temp = tail->next; tail->next = prev; prev = tail; tail = temp; } prev_broke->next->next = after_broke; prev_broke->next = prev; return dummyHead->next; }
手写:删除链表倒数第 N 个节点
给定一个链表,删除链表的倒数第 n 个节点,并且返回链表的头结点。
示例:
给定一个链表: 1->2->3->4->5, 和 n = 2.
当删除了倒数第二个节点后,链表变为 1->2->3->5.
这道题很巧妙:
其一是设置了一个虚拟的头结点:这是为了防止让你删除倒数第四个结点时结果把自己的头结点给删除了。。。
其二是窗口的大小比你要删除的大小要大一个,这样可以直接用后面那个的next来删除,省却了后面跟一个伴随指针来做删除。所以你看到n+1
注意看它的动图,它最后q指针指向了null,我感到困惑:指到5不就行了吗?
注意他这里是q,而不是q->next。所以指到5之后还要进行一次while循环,因为q不为空嘛!
while(q) 最后一个元素也要参与到运算中 while(q->next)最后一个元素不参与到运算中
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 class Solution {public : ListNode* removeNthFromEnd (ListNode* head, int n) { ListNode *temp = new ListNode(0 ); temp -> next = head; ListNode *last = temp; ListNode *first = temp; for (int i = 0 ; i < n+1 ; i++) { first = first->next; } while (first) { last = last->next; first = first->next; } ListNode *delNode = last->next; last->next = delNode->next; delete delNode; ListNode *retNode = temp->next; delete temp; return retNode; } };
手写:删除链表中重复元素 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 ListNode* deleteDuplicates (ListNode* head) { ListNode* first = head; ListNode* second = head; while (second) { if (first->val != second->val) { first = first->next; second = second->next; } else { while (second && second->val == first->val) { second = second->next; } first->next = second; first = second; } } return head; }
手写:删除链表中重复元素II 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 class Solution {public : ListNode* deleteDuplicates (ListNode* head) { if (head == nullptr ) return nullptr ; ListNode* dummyHead = new ListNode(0 , head); ListNode* curr = dummyHead; while (curr->next && curr->next->next) { if (curr->next->val == curr->next->next->val) { int val = curr->next->val; while (curr->next && curr->next->val == val) { curr->next = curr->next->next; } } else { curr = curr->next; } } return dummyHead->next; } };
手写:环形链表II 判断环形链表入环点
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 ListNode *detectCycle (ListNode *head) { ListNode* slow = head; ListNode* fast = head; while (fast) { slow = slow->next; if (fast->next == nullptr ) return nullptr ; fast = fast->next->next; if (slow == fast) { ListNode* ptr = head; while (ptr != slow) { slow = slow->next; ptr = ptr->next; } return ptr; } } return nullptr ; }
手写:最小栈 我这么写太麻烦,不如按照官方题解那样
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 class MinStack {public : MinStack() { } void push (int x) stk.push(x); if (min_stk.empty() || min_stk.top() >= x) min_stk.push(x); } void pop () if (stk.top() == min_stk.top()) { stk.pop(); min_stk.pop(); } else { stk.pop(); } } int top () return stk.top(); } int getMin () return min_stk.top(); } private : stack <int > stk; stack <int > min_stk; };
官方题解:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 class MinStack { stack <int > x_stack; stack <int > min_stack; public : MinStack() { min_stack.push(INT_MAX); } void push (int x) x_stack.push(x); min_stack.push(min(min_stack.top(), x)); } void pop () x_stack.pop(); min_stack.pop(); } int top () return x_stack.top(); } int getMin () return min_stack.top(); } };
注意和窗口最小值和最小队列区分开来,那两个需要无限弹出
如果说只用一个栈的话可以:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 class MinStack {public : MinStack() { } void push (int x) if (st.size() == 0 ) { st.push({x, x}); } else { st.push({x, min(x, st.top().second)}); } } void pop () st.pop(); } int top () return st.top().first; } int getMin () return st.top().second; } private : stack <pair <int , int >> st; };
手写:三数之和 注意去重处理:不光第一个元素需要去重,第二个元素也需要去重
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 class Solution {public : vector <vector <int >> threeSum(vector <int >& nums) { if (nums.size() < 3 ) return {}; sort(nums.begin(), nums.end()); vector <vector <int >> res; for (int i = 0 ; i < nums.size() - 2 ; ++i) { if (nums[i] > 0 ) continue ; if (i > 0 && nums[i] == nums[i - 1 ]) { continue ; } int right = nums.size() - 1 ; for (int left = i + 1 ; left < right; ++left) { if (left > i + 1 && nums[left] == nums[left - 1 ]) { continue ; } while (left < right && nums[left] + nums[right] > -nums[i]) { --right; } if (left == right) break ; if (nums[left] + nums[right] == -nums[i]) { res.push_back({nums[i], nums[left], nums[right]}); } } } return res; } }; class Solution {public : vector <vector <int >> threeSum(vector <int >& nums) { int size = nums.size(); if (size < 3 ) return {}; vector <vector <int > >res; std ::sort(nums.begin(), nums.end()); for (int i = 0 ; i < size; i++) { if (nums[i] > 0 ) return res; if (i > 0 && nums[i] == nums[i-1 ]) continue ; int left = i + 1 ; int right = size - 1 ; while (left < right) { if (nums[left] + nums[right] > -nums[i]) right--; else if (nums[left] + nums[right] < -nums[i]) left++; else { res.push_back(vector <int >{nums[i], nums[left], nums[right]}); left++; right--; while (left < right && nums[left] == nums[left-1 ]) left++; while (left < right && nums[right] == nums[right+1 ]) right--; } } } return res; } };
手写:string 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 class string {public : ~string (){ if (m_data != NULL ) { delete [] m_data; m_data = NULL ; } } string (const char * s) { if (s == NULL ) { m_data = new char [1 ]; *m_data = '\0' ; } else { int sz = strlen (s); m_data = new char [sz + 1 ]; strcpy (m_data, s); } }; string (const string & s) { int sz = strlen (s); m_data = new char [sz + 1 ]; strcpy (m_data, s.m_data); } string & operator = (const string & s) { if (*this == s) return *this ; delete [] m_data; int len = strlen (s.m_data); m_data = new char [len + 1 ]; strcpy (m_data, s.m_data); return *this ; } private : char * m_data; }
手写:string 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 class CMyString { public : CMyString(char * pData = nullptr ); CMyString(const CMyString& str); ~CMyString(void ); CMyString& operator = (const CMyString& str); void Print () private : char * m_pData; }; CMyString::CMyString(char *pData) { if (pData == nullptr ) { m_pData = new char [1 ]; m_pData[0 ] = '\0' ; } else { int length = strlen (pData); m_pData = new char [length + 1 ]; strcpy (m_pData, pData); } } CMyString::CMyString(const CMyString &str) { int length = strlen (str.m_pData); m_pData = new char [length + 1 ]; strcpy (m_pData, str.m_pData); } CMyString::~CMyString() { delete [] m_pData; } CMyString& CMyString::operator = (const CMyString& str) { if (this == &str) return *this ; cout << this << endl ; cout << &str << endl ; delete []m_pData; m_pData = nullptr ; m_pData = new char [strlen (str.m_pData) + 1 ]; strcpy (m_pData, str.m_pData); return *this ; }
手写:线程安全单例模式 在c++设计模式中提出一种很简单的实现方法:其实现过程是这样的,首先要保证一个类只有一个实例,而且使用类静态指针指向唯一的实例;当然就在类中构造一个实例,那么就要调用构造函数,为了防止在类的外部调用类的构造函数创建实例,需要将构造函数访问权限设计成私有的;当然要提供一个全局的访问节点,那么就类中定义一个static函数,在其函数体中调用类的构造函数创建实例并且返回这个唯一的构造实例。说了这么多,还不如上代码仔细品味这段话的意思,代码:
我们从头到尾都没考虑线程安全问题,如果你使用第四种方法,恭喜你无意识中避免了线程安全,这又另外一个话题了:在c++ 11新标准中,静态局部变量是线程安全的参考文章:http://anotherlayer.net/2012/05/04/static-initialization-and-thread-safety/
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 #include <iostream> using namespace std ; class Singleton { public : static Singleton* get_instance () { static Singleton instance; return &instance; } private : Singleton(){}; Singleton(const Singleton&); Singleton& operator ==(const Singleton&); }; int main (int argc, char *argv[]) Singleton *object = Singleton::get_instance(); return 0 ; } class singleton {private : singleton() {} static singleton *p; public : static singleton *instance () }; singleton *singleton::p = new singleton(); singleton* singleton::instance () { return p; }
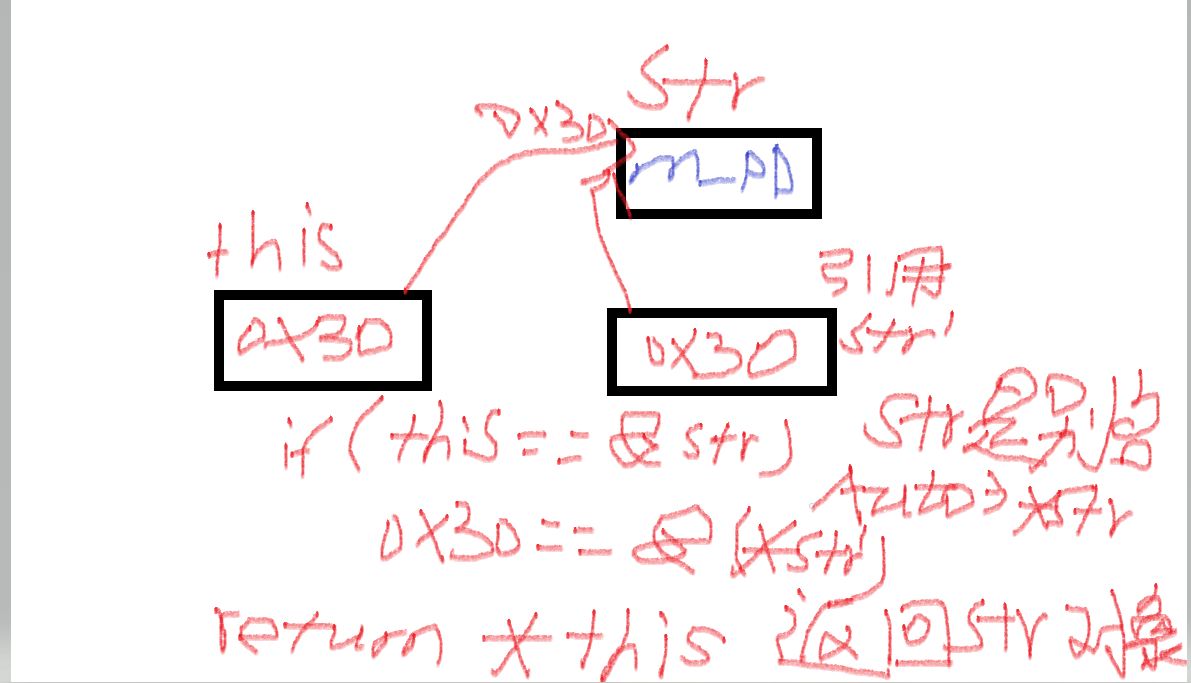
手写:智能指针 // this 是对象的地址,that 是一个引用,会被自动解引用为 * that,所以为了获取对象地址,需要使用&取地址
if (this != &that)
或者还可以写成 if (*this == that)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 #pragma once template <class T >class SharedPointer { public : SharedPointer() :m_refCount(nullptr ), m_pointer(nullptr ) {} SharedPointer(T* adoptTarget) :m_refCount(nullptr ), m_pointer(adoptTarget) { addReference(); } SharedPointer(const SharedPointer<T>& copy) :m_refCount(copy.m_refCount), m_pointer(copy.m_pointer) { addReference(); } virtual ~SharedPointer() { removeReference(); } SharedPointer<T>& operator =(const SharedPointer<T>& that) { if (this != &that) { removeReference(); this ->m_pointer = that.m_pointer; this ->m_refCount = that.m_refCount; addReference(); } return *this ; } bool operator ==(const SharedPointer<T>& other) { return m_pointer == other.m_pointer; } bool operator !=(const SharedPointer<T>& other) { return !operator ==(other); } T& operator *() const { return *m_pointer; } T* operator ->() const { return m_pointer; } int GetReferenceCount () const { if (m_refCount) { return *m_refCount; } else { return -1 ; } } protected : void addReference () { if (m_refCount) { (*m_refCount)++; } else { m_refCount = new int (0 ); *m_refCount = 1 ; } } void removeReference () { if (m_refCount) { (*m_refCount)--; if (*m_refCount == 0 ) { delete m_refCount; delete m_pointer; m_refCount = 0 ; m_pointer = 0 ; } } } private : int * m_refCount; T* m_pointer; };
举个例子,遍历经过 IVIV 的时候先记录 II 的对应值 11 再往前移动一步记录 IVIV 的值 33,加起来正好是 IVIV 的真实值 44。max 函数在这里是为了防止遍历第一个字符的时候出现 [-1:0]的情况
1 2 3 4 5 6 7 8 9 10 11 12 13 class Solution {public : int romanToInt (string s) unordered_map <string , int > m = {{"I" , 1 }, {"IV" , 3 }, {"IX" , 8 }, {"V" , 5 }, {"X" , 10 }, {"XL" , 30 }, {"XC" , 80 }, {"L" , 50 }, {"C" , 100 }, {"CD" , 300 }, {"CM" , 800 }, {"D" , 500 }, {"M" , 1000 }}; int r = m[s.substr(0 , 1 )]; for (int i=1 ; i<s.size(); ++i){ string two = s.substr(i-1 , 2 ); string one = s.substr(i, 1 ); r += m[two] ? m[two] : m[one]; } return r; } };
给定一个链表,旋转链表,将链表每个节点向右移动 k 个位置,其中 k 是非负数。
示例 1:
输入: 1->2->3->4->5->NULL, k = 2
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 class Solution {public : ListNode* rotateRight (ListNode* head, int k) { if (head == NULL ) return NULL ; if (head->next == NULL ) return head; ListNode* temp; temp = head; int length = 1 ; while (temp->next) { ++length; temp = temp->next; } temp->next = head; if (k%=length) { for (int i = 0 ; i < length - k; ++i) { temp = temp->next; } } ListNode* res = temp->next; temp->next = NULL ; return res; } };
这个代码有以下几个值得学习的地方:
将链表做成一个回环:注意空链表与单链表特例
使用++len而不是len++,省却拷贝花销
这里的k%=len很巧妙:其一是对于0和链表长度的k不进行处理–因为就算翻转过来也和原链表一样
其二是将k值重新设置为小于等于len的数值,防止下面len-k出现溢出
还有一点需要注意的是每次你想设置一个节点来追踪前链表元素的时候,不妨考虑一下少走一步?
我本来for循环里是写的head= head->next,前面设置一个节点来做游标,不如人家这个直接使用temp尾节点来做游标好一些。。。
手写:strcpy() 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 #include <iostream> using namespace std ;char * strcpy (char *strSrc, char *strDest) if ((strSrc == NULL ) || (strDest == NULL )) return NULL ; char *strDestCopy = strDest; while ((*strDest++ = *strSrc++) != '\0' ); return strDestCopy; } int main () char strSrc[] = "Hello World!" ; char strDest[20 ]; strcpy (strSrc, strDest); cout << "strDest: " << strDest << endl ; return 0 ; }
手写:链表相邻元素翻转 输入 bacd 输出 abdc
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 class Solution {public : ListNode* swapPairs (ListNode* head) { ListNode* dummyHead = new ListNode(0 ); dummyHead->next = head; ListNode* temp = dummyHead; while (temp->next != nullptr && temp->next->next != nullptr ) { ListNode* node1 = temp->next; ListNode* node2 = temp->next->next; temp->next = node2; node1->next = node2->next; node2->next = node1; temp = node1; } return dummyHead->next; } }; 作者:LeetCode-Solution 链接:https: 来源:力扣(LeetCode) 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
手写:K 个一组翻转链表 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 class Solution {public : pair <ListNode*, ListNode*> myReverse (ListNode* head, ListNode* tail) ListNode* prev = tail->next; ListNode* p = head; while (prev != tail) { ListNode* nex = p->next; p->next = prev; prev = p; p = nex; } return {tail, head}; } ListNode* reverseKGroup (ListNode* head, int k) { ListNode* hair = new ListNode(0 ); hair->next = head; ListNode* pre = hair; while (head) { ListNode* tail = pre; for (int i = 0 ; i < k; ++i) { tail = tail->next; if (!tail) { return hair->next; } } ListNode* nex = tail->next; tie(head, tail) = myReverse(head, tail); pre->next = head; tail->next = nex; pre = tail; head = tail->next; } return hair->next; } }; class Solution {public : pair <ListNode*, ListNode*> myReverse (ListNode* head, ListNode* tail) ListNode* prev = nullptr ; ListNode* p = head; while (prev != tail) { ListNode* nex = p->next; p->next = prev; prev = p; p = nex; } return {head, tail}; } ListNode* reverseKGroup (ListNode* head, int k) { ListNode* dummyHead = new ListNode(0 ); dummyHead->next = head; ListNode* prev = dummyHead; while (head) { ListNode* tail = prev; for (int i = 0 ; i < k; ++i) { tail = tail->next; if (tail == nullptr ) return dummyHead->next; } ListNode* nex = tail->next; pair <ListNode*, ListNode*> result = myReverse(head, tail); head = result.first; tail = result.second; prev->next = tail; head->next = nex; prev = head; head = nex; } return dummyHead->next; } };
手写:合并两个有序链表 1 2 3 4 5 6 7 8 9 10 11 12 13 14 ListNode* mergeTwoLists (ListNode *a, ListNode *b) { if ((!a) || (!b)) return a ? a : b; ListNode head, *tail = &head, *aPtr = a, *bPtr = b; while (aPtr && bPtr) { if (aPtr->val < bPtr->val) { tail->next = aPtr; aPtr = aPtr->next; } else { tail->next = bPtr; bPtr = bPtr->next; } tail = tail->next; } tail->next = (aPtr ? aPtr : bPtr); return head.next; }
手写:统计数组中不同元素出现的次数 (时间复杂度O(n),空间复杂度O(1))
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 vector findNumbers (vector & nums) int n = nums.size(); for (int i = 0 ; i < n; ++ i ) { while (nums[i] > 0 ) { int cur; if (nums[nums[i]-1 ] > 0 ) { cur = nums[i]-1 ; nums[i] = nums[nums[i]-1 ]; nums[cur] = -1 ; } else if (nums[nums[i]-1 ] != inf) { cur = nums[i]-1 ; nums[i] = inf; nums[cur] -= 1 ; } else { cur = nums[i]-1 ; nums[i] = inf; nums[cur] = -1 ; } } } vector ans; for (int i = 0 ; i < n; ++ i ) if (nums[i] == inf) ans.push_back(0 ); else ans.push_back(-nums[i]); return ans; } ------------------------------- #include <iostream> #include <algorithm> #include <vector> #include <queue> #include <stack> #include <string> #include <string.h> #include <fstream> #include <map> #include <iomanip> #include <cstdio> #include <cstdlib> #include <cmath> #include <deque> #include <hash_map> using namespace std ; const int MAX = 0x7FFFFFFF ; const int MIN = 0x80000000 ; void work (int a[], int n) int i = 0 ; while (i < n) { int temp = a[i] - 1 ; if (temp < 0 ) { i++; continue ; } if (a[temp] > 0 ) { a[i] = a[temp]; a[temp] = -1 ; } else { a[temp]--; a[i] = 0 ; } } } int main () int n; while (cin >> n) { int *a = new int [n]; for (int i = 0 ; i < n; i++) cin >> a[i]; work(a, n); for (int i = 0 ; i < n; i++) if (a[i] < 0 ) cout << i + 1 << " " << (-a[i]) << endl ; cout << "********************" << endl ; delete [] a; } system("pause" ); return 0 ; }
手写:统计一个数字在排序数组中出现的次数 统计一个数字在排序数组中出现的次数。
示例 1:
输入: nums = [5,7,7,8,8,10], target = 8
输入: nums = [5,7,7,8,8,10], target = 6
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 class Solution { public int search (int [] nums, int target) int i = 0 , j = nums.length - 1 ; while (i <= j) { int m = (i + j) / 2 ; if (nums[m] <= target) i = m + 1 ; else j = m - 1 ; } int right = i; if (j >= 0 && nums[j] != target) return 0 ; i = 0 ; j = nums.length - 1 ; while (i <= j) { int m = (i + j) / 2 ; if (nums[m] < target) i = m + 1 ; else j = m - 1 ; } int left = j; return right - left - 1 ; } } 作者:jyd 链接:https: 来源:力扣(LeetCode) 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
牛客:字符串压缩 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 #include <iostream> using namespace std ;int main (int argc, char ** argv) string s; cin >> s; int i = 0 ; while (i < strlen (s)) { if (s[i] == ']' ) { int j = i; int k = i; while (s[j] != '[' ) { if (s[j] == '|' ) { k = j; } --j; } int len = stoi(s.substr(j + 1 , k - j - 1 )); string s1 = s.substr(k + 1 , i - k - 1 ); string s2; for (int p = 0 ; p < len; ++p) { s2 += s1; } s.replace(j, i - j + 1 , s2); i = j; } ++i; } cout << s; }
手写:string to int 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 class Solution {public : int strToInt (string str) int i = 0 , flag = 1 ; long res = 0 ; while (str[i] == ' ' ) i ++; if (str[i] == '-' ) flag = -1 ; if (str[i] == '-' || str[i] == '+' ) i ++; for (; i < str.size(); i++) { if (str[i]<'0' ||str[i]>'9' ) break ; res = res * 10 + (str[i] - '0' ); if (res >= INT_MAX && flag == 1 ) return INT_MAX; if (res > INT_MAX && flag == -1 ) return INT_MIN; } return flag * res; } };
字符匹配 题目:glob是一种Unix风格的路径匹配模式,其规则如下:
输入2:“dir/*”,”dir/.env”
手写:二分法 二分法第一种写法
以这道题目来举例,以下的代码中定义 target 是在一个在左闭右闭的区间里,「也就是[left, right] (这个很重要)」 。
这就决定了这个二分法的代码如何去写,大家看如下代码:
「大家要仔细看注释,思考为什么要写while(left <= right), 为什么要写right = middle - 1」 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 class Solution {public : int searchInsert (vector <int >& nums, int target) int n = nums.size(); int left = 0 ; int right = n - 1 ; while (left <= right) { int middle = left + ((right - left) / 2 ); if (nums[middle] > target) { right = middle - 1 ; } else if (nums[middle] < target) { left = middle + 1 ; } else { return middle; } } return right + 1 ; } };
二分法第一种写法
如果说定义 target 是在一个在左闭右开的区间里,也就是[left, right) 。
那么二分法的边界处理方式则截然不同。
不变量是[left, right)的区间,如下代码可以看出是如何在循环中坚持不变量的。
「大家要仔细看注释,思考为什么要写while (left < right), 为什么要写right = middle」 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 class Solution {public : int searchInsert (vector <int >& nums, int target) int n = nums.size(); int left = 0 ; int right = n; while (left < right) { int middle = left + ((right - left) >> 1 ); if (nums[middle] > target) { right = middle; } else if (nums[middle] < target) { left = middle + 1 ; } else { return middle; } } return right; } };
0303
查找旋转排序数组的最小值
注意看当 numbers[pivot] < numbers[high] 时是不减一的哈,因为 pivot 此时可能正在最小值处
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 int low = 0 ; int high = numbers.size() - 1 ; while (low <= high) { int pivot = low + (high - low) / 2 ; if (numbers[pivot] < numbers[high]) { high = pivot; } else if (numbers[pivot] > numbers[high]) { low = pivot + 1 ; } else { high -= 1 ; } } return numbers[low]; 图片链接:https:
旋转数组的查找特定数字
下面的这个nums[0] <= target 处为何加个 = ?
因为当 nums[0] == target 时,应该让远处的 right 滚回来。而不是让就在此处的 left 再移动了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 class Solution {public : int search (vector <int >& nums, int target) int n = (int )nums.size(); if (!n) { return -1 ; } if (n == 1 ) { return nums[0 ] == target ? 0 : -1 ; } int l = 0 , r = n - 1 ; while (l <= r) { int mid = (l + r) / 2 ; if (nums[mid] == target) return mid; if (nums[0 ] <= nums[mid]) { if (nums[0 ] <= target && target < nums[mid]) { r = mid - 1 ; } else { l = mid + 1 ; } } else { if (nums[mid] < target && target <= nums[n - 1 ]) { l = mid + 1 ; } else { r = mid - 1 ; } } } return -1 ; } }; 作者:LeetCode-Solution 链接:https: 来源:力扣(LeetCode) 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
if else 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 #include <iostream> int main () int i = 5 ; if (i < 2 ) { std ::cout << i << " < 2\n" ; } else if (i > 3 ) { std ::cout << i << " > 3\n" ; } else if (i > 4 ){ std ::cout << i << " > 4\n" ; } } --------- 5 > 3 --------
1 2 3 4 5 6 7 8 9 if (条件1 ){ } if (条件2 ){ }
这种格式中,程序会依次判断条件1和条件2是否成立并根据结果决定是否执行语句1和语句2,也就是说,第一个 if 块和第二个 if 块没有影响(除非在执行第一个 if 块的时候就凶残地 return 了)
而下面这种格式,
1 2 3 4 5 6 7 8 if (条件1 ) { } else if (条件2 ){ }
if 块和 else if 块本质上是互斥的!也就是说,一旦语句1得到了执行,程序会跳过 else if 块,else if 块中的判断语句以及语句2一定会被跳过;同时语句2的执行也暗含了条件1判断失败和语句1没有执行;当然还有第3个情况,就是条件1和条件2都判断失败,语句1和语句2都没有得到执行。
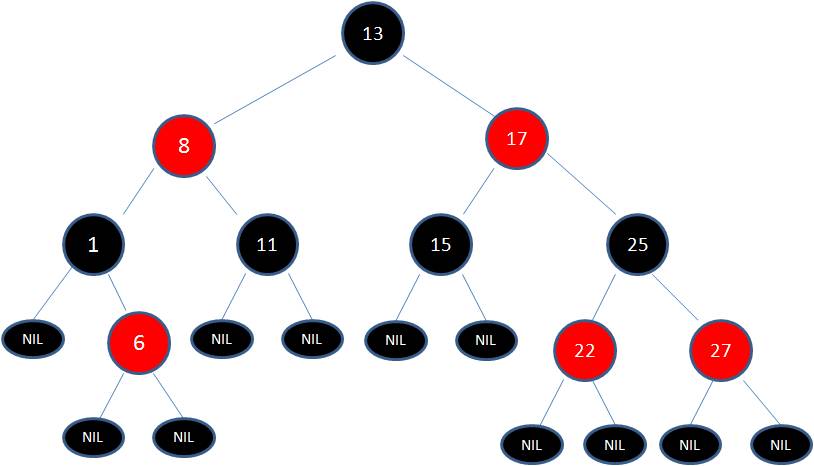
红黑树
1、根节点是黑色;(头头是黑社会)
2、叶子节点(NIL)也是黑色;(小弟也是黑社会)
3、每个红色节点的两个子节点是黑色;(红社会下罩着两个黑社会)
4、从任一节点到其每个叶子的所有路径包含相同数目的黑色节点;(黑社会要均衡,这保证了从根到叶子的最长路径不会超过最短路径的2倍)
0604 今天和7楼另外一个去阿里的学长交流了一下,他拿了阿里腾讯的sp,华为的ssp
1、Linux多线程编程 muduo库 10元(已出)
这几本书研一研二就应该看完
程序员自我修养 Effective C++ + more effective C++ 两本 这几本书应该在找工作前看三遍以上,剑指offer 也是,面试时这些C++ 的基础并不会问的很深,但是这几本书会问的很深
美团0313笔试 滑动窗口找最小
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 #include <iostream> #include <string> #include <vector> #include <algorithm> #include <unordered_map> using namespace std ;#define LOCAL #pragma warning (disable: 4996) bool comp (pair <int , int > a, pair <int , int > b) return a.second < b.second; } int main () int num, cnt; #ifdef LOCAL freopen("out.txt" , "r" , stdin ); #endif while (cin >> num >> cnt) { vector <int > arr (num) for (int i = 0 ; i < num; ++i) { cin >> arr[i]; } for (int i = 0 ; i < num - cnt + 1 ; ++i) { unordered_map <int , int > hash_; vector <pair <int , int >> vec; for (int j = 0 ; j < cnt; ++j) { hash_[arr[i + j]]++; } for (auto & i : hash_) { vec.push_back(i); } std ::sort(vec.begin(), vec.end(), [](pair <int , int >& A, pair <int , int >& B) {return A.second > B.second; }); if (vec[0 ].second == 1 ) { std ::sort(vec.begin(), vec.end(), [](pair <int , int >& A, pair <int , int >& B) {return A.first < B.first; }); cout << vec[0 ].first << endl ; } else cout << vec[0 ].first << endl ; } } return 0 ; }
还有一种堆的算法:
//对于基础类型 默认是大顶堆
priority_queue<int> a;
//等同于 priority_queue<int, vector<int>, less<int> > a;
// 这里一定要有空格,不然成了右移运算符↓
priority_queue<int, vector<int>, greater<int> > c; //这样就是小顶堆1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 #include <iostream> #include <queue> #include <vector> using namespace std ;int main () priority_queue <pair <int , int > > a; pair <int , int > b (1 , 2 ) pair <int , int > c (1 , 3 ) pair <int , int > d (2 , 5 ) a.push(d); a.push(c); a.push(b); while (!a.empty()) { cout << a.top().first << ' ' << a.top().second << '\n' ; a.pop(); } }